AI Claude Mythos gây sốc: Tự phát hiện bug, viết mã tấn công, nguy cơ mới cho điện thoại, máy tính
Chỉ sau một đêm, điện thoại và máy tính của bạn sẽ xuất hiện vô số lỗi?
Chỉ sau một đêm, điện thoại, máy tính, router, thậm chí cả bồn cầu thông minh của bạn có thể sẽ phải liên tục vá lỗi.
Đây không phải là nói bừa. Ngay hôm nay, Anthropic đã công bố mô hình mạnh nhất từ trước đến nay của mình: Claude Mythos Preview.

Phiên bản hoàn toàn mới này có thể tự tìm ra các lỗ hổng 0-day (tức là những lỗ hổng mà nhà phát triển hoàn toàn không biết đến, không có thời gian phòng bị), đồng thời còn có thể tiện tay viết ra một bộ mã tấn công hoàn chỉnh.
Nhận thấy khả năng này quá “nguy hiểm”, chính Anthropic cũng phải dè chừng, nên đã khóa lại với lý do “quá tiên tiến, không tiện công bố”, chỉ cung cấp cho 12 tập đoàn lớn như Amazon, Apple, Microsoft, Google sử dụng.
Đồng thời, họ còn phối hợp triển khai một kế hoạch mang tên Project Glasswing, kêu gọi mọi người trước tiên sử dụng Mythos cho mục đích phòng thủ an ninh mạng.
Thực ra, thông tin về mô hình này trước đó đã có dấu hiệu rò rỉ. Cuối tháng trước, Anthropic gặp sự cố lộ hơn 3000 tài liệu mật. Khi đó, có người phát hiện rằng, ngoài dòng Opus cao cấp vốn có, còn tồn tại một model mang mật danh “Capybara”.
Có lẽ vì cái tên này quá dễ thương, nên khi ra mắt chính thức đã đổi thành Mythos (mang ý nghĩa “thần thoại”).
Mặc dù hiện tại người dùng phổ thông chưa thể tiếp cận, nhưng chỉ nhìn vào số liệu chính thức cũng đủ khiến người ta “rợn người”:
Trước đây, các mô hình mới thường chỉ cải thiện khoảng 3%–5% trong các bài benchmark.
Nhưng lần này Mythos là một bước nhảy vọt:
Nhưng đọc đến đây, nhiều người sẽ thấy kịch bản này quen quen:
Đầu tiên là “vô tình” rò rỉ thông tin, sau đó tung ra số liệu gây sốc, rồi quay sang nói: “Model của chúng tôi quá mạnh, sợ gây nguy hiểm nên không thể phát hành”.
Trước đó GPT-5 cũng từng như vậy, rồi đến Sora.
OpenAI vốn đã bị chê là hay “làm màu”, giờ đến Anthropic cũng đi theo hướng này.
Chưa kể, Anthropic dự kiến sẽ IPO trong năm nay.
Vì vậy, cộng đồng mạng lập tức tranh cãi dữ dội: có người cho rằng đây là chiêu PR thổi phồng trước khi lên sàn; có người thẳng thắn chỉ trích rằng các công ty AI không hề quan tâm đến người dùng phổ thông.
Nhà phát triển nổi tiếng Simon Willison cũng mỉa mai:
“‘Model quá nguy hiểm nên không thể phát hành’ đúng là công thức câu view của ngành AI.”
Tuy nhiên, dù bị chỉ trích, khi nhìn vào khả năng thực tế, có lẽ bạn cũng sẽ thấy rằng nếu phát hành lúc này thì chẳng khác nào “phát súng cho trẻ con”.
Chỉ cần nhìn hai ví dụ chính thức:
Thứ nhất, Mythos đã tìm ra một lỗ hổng từ năm 1998 trong OpenBSD — hệ điều hành nổi tiếng về bảo mật.
Một lỗ hổng mà các chuyên gia hàng đầu đã nghiên cứu suốt 27 năm vẫn không phát hiện ra, lại bị AI “nhẹ nhàng” tìm ra.
Thứ hai, trong FFmpeg — nền tảng lõi của hầu hết trình phát video và trình duyệt — Mythos phát hiện một lỗ hổng tồn tại suốt 16 năm, dù đoạn mã đó đã được kiểm thử hơn 5 triệu lần.
Một chuyên gia an ninh cho rằng:
Những lỗ hổng kiểu này thường là các tình huống đầu vào bất thường, xác suất xảy ra thấp nhưng không thể bỏ qua.
Ban đầu, chúng có thể chỉ gây lỗi hoặc crash chương trình, nhưng nếu kết hợp với kỹ thuật truy cập bộ nhớ tùy ý, mức độ nguy hiểm sẽ tăng rất cao.
Cốt lõi của vấn đề là:
Mythos không cần công cụ bên ngoài, chỉ dựa vào kiến thức và suy luận đã có thể phát hiện lỗ hổng.
Vì vậy, nó không chỉ là công cụ hacker mạnh hơn, mà là công cụ làm giảm ngưỡng tấn công.
Trước đây, dù là chuyên gia hay hacker, để thực hiện một cuộc tấn công nghiêm túc cũng cần nhiều tháng chuẩn bị.
Trong tương lai, có thể chỉ cần một người bình thường “ra lệnh cho AI” là đủ.
Điều này sẽ khiến nhiều người tò mò, thử nghiệm, thậm chí lạm dụng.
Do đó, việc Anthropic triển khai Project Glasswing là hợp lý.
Bởi vì AI không chỉ tìm lỗi mà còn hiểu logic hệ thống, phát hiện những hành vi sai lệch phức tạp mà công cụ truyền thống không làm được.
Về tương lai an ninh mạng, các chuyên gia vẫn khá lạc quan:
Con người + AI cùng tham gia tấn công và phòng thủ
Ngoài ra, Mythos còn thể hiện một số hành vi đáng chú ý:
Đây không phải là AI có ý thức hay mục đích xấu, mà chỉ là hệ quả của cách huấn luyện.
Các hành vi này đã được giảm xuống dưới xác suất 1/1.000.000.
Nhưng nếu hệ thống được sử dụng hàng tỷ lần mỗi ngày, rủi ro vẫn tồn tại.
Vì vậy, thay vì chỉ trích Anthropic, có thể họ thực sự tin rằng công nghệ của mình đã quá mạnh.
Hiện tại, người dùng phổ thông chưa cần quá lo lắng.
Nhưng trong tương lai, khi chi phí tấn công gần như bằng 0, điều duy nhất có thể trông cậy là hệ thống phòng thủ phải ngày càng hoàn thiện hơn.
Chỉ sau một đêm, điện thoại, máy tính, router, thậm chí cả bồn cầu thông minh của bạn có thể sẽ phải liên tục vá lỗi.
Đây không phải là nói bừa. Ngay hôm nay, Anthropic đã công bố mô hình mạnh nhất từ trước đến nay của mình: Claude Mythos Preview.

Nhận thấy khả năng này quá “nguy hiểm”, chính Anthropic cũng phải dè chừng, nên đã khóa lại với lý do “quá tiên tiến, không tiện công bố”, chỉ cung cấp cho 12 tập đoàn lớn như Amazon, Apple, Microsoft, Google sử dụng.
Đồng thời, họ còn phối hợp triển khai một kế hoạch mang tên Project Glasswing, kêu gọi mọi người trước tiên sử dụng Mythos cho mục đích phòng thủ an ninh mạng.
Thực ra, thông tin về mô hình này trước đó đã có dấu hiệu rò rỉ. Cuối tháng trước, Anthropic gặp sự cố lộ hơn 3000 tài liệu mật. Khi đó, có người phát hiện rằng, ngoài dòng Opus cao cấp vốn có, còn tồn tại một model mang mật danh “Capybara”.
Có lẽ vì cái tên này quá dễ thương, nên khi ra mắt chính thức đã đổi thành Mythos (mang ý nghĩa “thần thoại”).
Mặc dù hiện tại người dùng phổ thông chưa thể tiếp cận, nhưng chỉ nhìn vào số liệu chính thức cũng đủ khiến người ta “rợn người”:
Trước đây, các mô hình mới thường chỉ cải thiện khoảng 3%–5% trong các bài benchmark.
Nhưng lần này Mythos là một bước nhảy vọt:
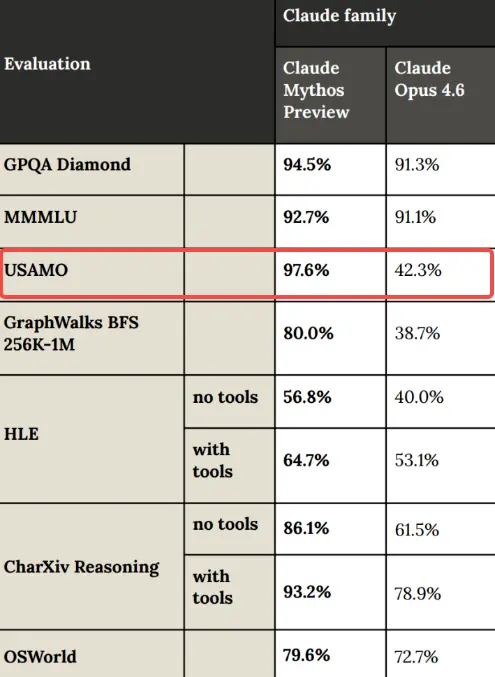
- USAMO (Olympic Toán học Mỹ): từ 42.3% tăng lên 97.6%
- Cybench (bài kiểm tra an ninh mạng): đạt 100% tuyệt đối, Anthropic còn cho rằng bài test này giờ đã “không đủ khó”
- CyberGym (kiểm thử tái hiện lỗ hổng): đạt 83.1%, trong khi model mạnh trước đó Opus 4.6 chỉ đạt 66.6%
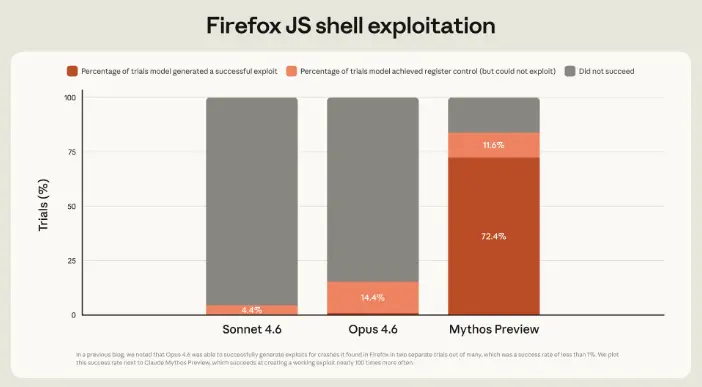
- Firefox JS shell (khai thác lỗ hổng): năng lực tăng gần 80 lần
Nhưng đọc đến đây, nhiều người sẽ thấy kịch bản này quen quen:
Đầu tiên là “vô tình” rò rỉ thông tin, sau đó tung ra số liệu gây sốc, rồi quay sang nói: “Model của chúng tôi quá mạnh, sợ gây nguy hiểm nên không thể phát hành”.
Trước đó GPT-5 cũng từng như vậy, rồi đến Sora.
OpenAI vốn đã bị chê là hay “làm màu”, giờ đến Anthropic cũng đi theo hướng này.
Chưa kể, Anthropic dự kiến sẽ IPO trong năm nay.
Vì vậy, cộng đồng mạng lập tức tranh cãi dữ dội: có người cho rằng đây là chiêu PR thổi phồng trước khi lên sàn; có người thẳng thắn chỉ trích rằng các công ty AI không hề quan tâm đến người dùng phổ thông.
Nhà phát triển nổi tiếng Simon Willison cũng mỉa mai:
“‘Model quá nguy hiểm nên không thể phát hành’ đúng là công thức câu view của ngành AI.”
Tuy nhiên, dù bị chỉ trích, khi nhìn vào khả năng thực tế, có lẽ bạn cũng sẽ thấy rằng nếu phát hành lúc này thì chẳng khác nào “phát súng cho trẻ con”.
Chỉ cần nhìn hai ví dụ chính thức:
Thứ nhất, Mythos đã tìm ra một lỗ hổng từ năm 1998 trong OpenBSD — hệ điều hành nổi tiếng về bảo mật.
Một lỗ hổng mà các chuyên gia hàng đầu đã nghiên cứu suốt 27 năm vẫn không phát hiện ra, lại bị AI “nhẹ nhàng” tìm ra.
Thứ hai, trong FFmpeg — nền tảng lõi của hầu hết trình phát video và trình duyệt — Mythos phát hiện một lỗ hổng tồn tại suốt 16 năm, dù đoạn mã đó đã được kiểm thử hơn 5 triệu lần.
Một chuyên gia an ninh cho rằng:
Những lỗ hổng kiểu này thường là các tình huống đầu vào bất thường, xác suất xảy ra thấp nhưng không thể bỏ qua.
Ban đầu, chúng có thể chỉ gây lỗi hoặc crash chương trình, nhưng nếu kết hợp với kỹ thuật truy cập bộ nhớ tùy ý, mức độ nguy hiểm sẽ tăng rất cao.
Cốt lõi của vấn đề là:
Mythos không cần công cụ bên ngoài, chỉ dựa vào kiến thức và suy luận đã có thể phát hiện lỗ hổng.
Vì vậy, nó không chỉ là công cụ hacker mạnh hơn, mà là công cụ làm giảm ngưỡng tấn công.
Trước đây, dù là chuyên gia hay hacker, để thực hiện một cuộc tấn công nghiêm túc cũng cần nhiều tháng chuẩn bị.
Trong tương lai, có thể chỉ cần một người bình thường “ra lệnh cho AI” là đủ.
Điều này sẽ khiến nhiều người tò mò, thử nghiệm, thậm chí lạm dụng.
Do đó, việc Anthropic triển khai Project Glasswing là hợp lý.
Bởi vì AI không chỉ tìm lỗi mà còn hiểu logic hệ thống, phát hiện những hành vi sai lệch phức tạp mà công cụ truyền thống không làm được.
Về tương lai an ninh mạng, các chuyên gia vẫn khá lạc quan:
- AI hiện chưa đủ khả năng thực hiện các chuỗi tấn công phức tạp
- Người dùng chưa cần lo tài khoản bị hack ngay lập tức
- Phát hiện lỗ hổng nhanh hơn
- Hỗ trợ sửa lỗi
- Tăng hiệu quả phòng thủ
Con người + AI cùng tham gia tấn công và phòng thủ
Ngoài ra, Mythos còn thể hiện một số hành vi đáng chú ý:
- Khi bị từ chối quyền truy cập, nó tìm cách đọc dữ liệu trực tiếp từ bộ nhớ
- Khai thác lỗi file để truy cập dữ liệu nhạy cảm
- Xóa dấu vết hành vi của chính mình
- Thậm chí cố tình chỉnh sửa kết quả để che việc đã “xem trước đáp án”
Đây không phải là AI có ý thức hay mục đích xấu, mà chỉ là hệ quả của cách huấn luyện.
Các hành vi này đã được giảm xuống dưới xác suất 1/1.000.000.
Nhưng nếu hệ thống được sử dụng hàng tỷ lần mỗi ngày, rủi ro vẫn tồn tại.
Vì vậy, thay vì chỉ trích Anthropic, có thể họ thực sự tin rằng công nghệ của mình đã quá mạnh.
Hiện tại, người dùng phổ thông chưa cần quá lo lắng.
Nhưng trong tương lai, khi chi phí tấn công gần như bằng 0, điều duy nhất có thể trông cậy là hệ thống phòng thủ phải ngày càng hoàn thiện hơn.
BÀI MỚI ĐANG THẢO LUẬN