Xiaomi tung bộ ba AI MiMo-V2: Pro hơn 1T tham số, Omni đa phương thức, TTS nói – hát như người thật
Xiaomi bất ngờ ra mắt 3 mô hình lớn — MiMo-V2-Pro, MiMo-V2-Omni và MiMo-V2-TTS. Hiện tại, các mô hình này đã có mặt trên Xiaomi miclaw, MiMo Studio, Kingsoft Office và trình duyệt Xiaomi, đồng thời có thể truy cập thông qua OpenClaw, OpenCode, KiloCode, Blackbox, Cline, cho phép trải nghiệm miễn phí trong thời gian giới hạn một tuần.

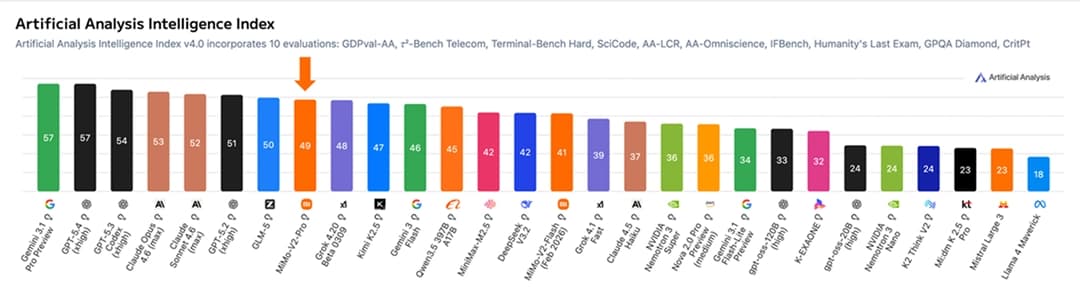
Xiaomi MiMo-V2-Pro được thiết kế chuyên biệt cho các kịch bản làm việc Agent cường độ cao trong thế giới thực. Mô hình sở hữu tổng số tham số vượt quá 1T (42B tham số kích hoạt), sử dụng kiến trúc attention lai sáng tạo và hỗ trợ độ dài ngữ cảnh siêu dài 1 triệu token. Xiaomi cũng tiếp tục mở rộng năng lực tính toán trong nhiều kịch bản Agent đa dạng hơn, qua đó mở rộng không gian hành động của trí tuệ, hiện thực hóa bước tổng quát hóa quan trọng từ Coding sang Claw. Trên bảng xếp hạng Artificial Analysis, MiMo-V2-Pro đứng thứ 8 toàn cầu, thứ 2 tại Trung Quốc.
Trong các framework Agent như OpenClaw, Claude Code…, MiMo-V2-Pro có thể hoàn thành việc điều phối workflow phức tạp, lập kế hoạch dài hạn và gọi công cụ chính xác mà không cần can thiệp của con người, đồng thời liên tục cung cấp kết quả cuối cùng một cách đáng tin cậy. Trải nghiệm sử dụng tổng thể đã vượt Claude Sonnet 4.6, tiệm cận Opus 4.6, nhưng giá API chỉ bằng 1/5, giúp giảm đáng kể rào cản tiếp cận AI tiên tiến.
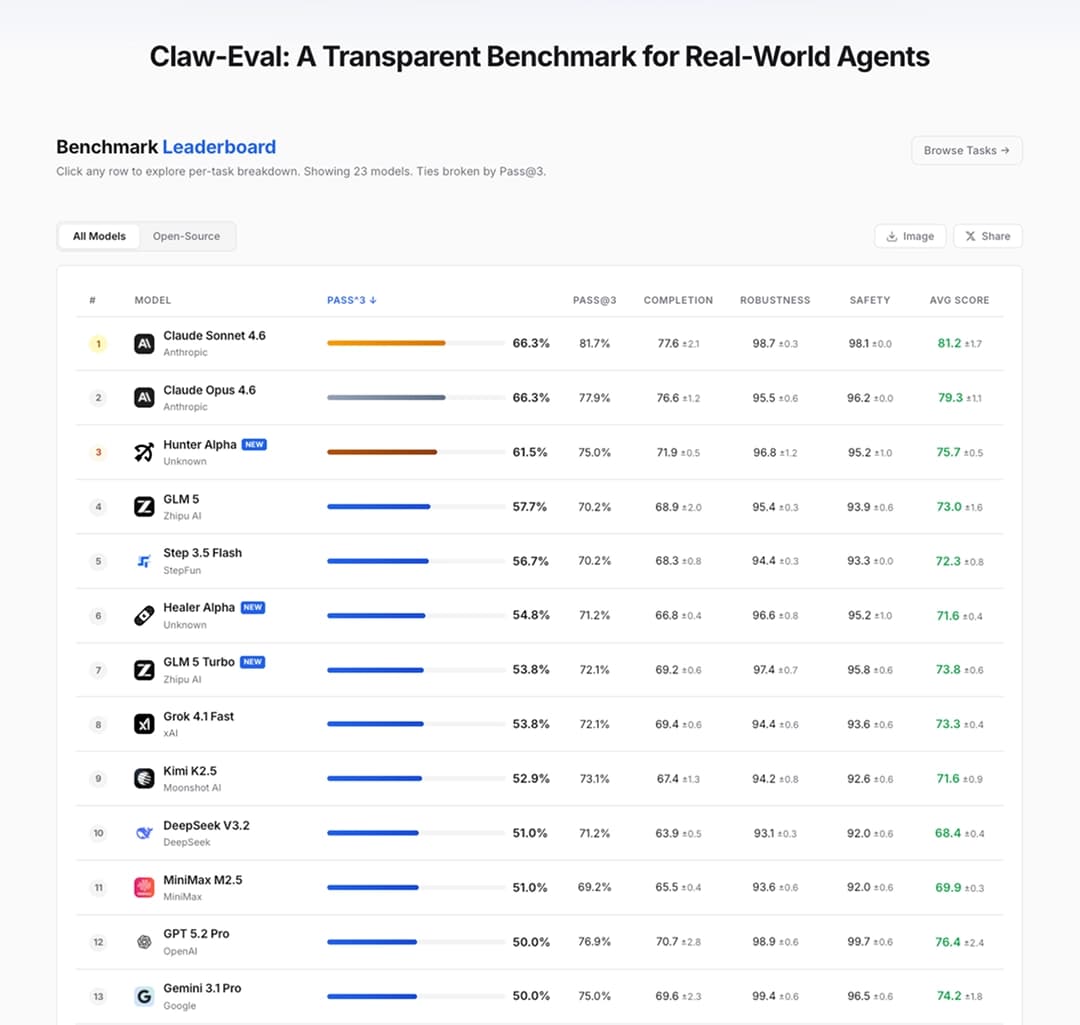
MiMo-V2-Pro được tối ưu sâu cho các kịch bản Agent. Thông qua SFT và RL trên nhiều dạng Agent Scaffold phức tạp, mô hình có năng lực gọi công cụ và suy luận nhiều bước mạnh mẽ hơn. Trên các bảng đánh giá tiêu chuẩn OpenClaw như PinchBench, ClawEval, hiệu quả của MiMo-V2-Pro nằm trong top đầu thế giới. Đồng thời, nhờ cửa sổ ngữ cảnh 1 triệu token, mô hình có thể dễ dàng hỗ trợ các ứng dụng Claw phức tạp trong thực tế.
MiMo-V2-Pro cũng có thể tham gia xây dựng các dự án lập trình nghiêm túc. Đánh giá nội bộ từ các kỹ sư cho thấy trải nghiệm đã tiệm cận Claude Opus 4.6, đồng thời thể hiện trí tuệ lập trình cao cấp với khả năng thiết kế hệ thống tốt hơn, lập kế hoạch nhiệm vụ rõ ràng hơn, phong cách code tinh gọn hơn và giải quyết vấn đề hiệu quả hơn.
Hiện mô hình đã mở API chính thức, hỗ trợ ngữ cảnh 1 triệu token, với mức giá tính theo dung lượng sử dụng:
Bạn có thể truy cập https://platform.xiaomimimo.com để kết nối API ngay.
Module MiMo Claw hiện đã tích hợp hoàn toàn với hệ sinh thái Kingsoft WebOffice, hỗ trợ nguyên bản các định dạng Word, Excel, PPT và PDF, bao phủ hơn 95% nhu cầu tài liệu hàng ngày.
Engine suy luận nền tảng của Xiaomi MiMo cũng đã tích hợp ở cấp framework với hệ sinh thái Kingsoft Office. WPS Lingxi hiện đã truy cập MiMo-V2-Pro, cho phép đặt câu hỏi hoặc giao nhiệm vụ cho Lingxi Claw, giúp công việc văn phòng hiệu quả hơn.
Về hiểu âm thanh, mô hình hỗ trợ từ phân loại âm thanh môi trường, tách nhiều người nói, suy luận kết hợp audio-visual đến việc hiểu sâu các đoạn audio liên tục dài hơn 10 giờ. Hiệu năng tổng thể vượt Gemini 3 Pro, trở thành một trong những mô hình nền tảng hiểu âm thanh mạnh nhất hiện nay.
Về hiểu hình ảnh, MiMo-V2-Omni thể hiện khả năng suy luận thị giác đa lĩnh vực và phân tích biểu đồ phức tạp, vượt Claude Opus 4.6, tiệm cận các mô hình đóng hàng đầu như Gemini 3 Pro.
Về video, mô hình hỗ trợ đầu vào audio-video gốc, thực hiện hiểu video đa phương thức thực sự. Thông qua pretraining video sáng tạo, mô hình có khả năng nhận thức ngữ cảnh mạnh mẽ và suy luận tương lai.
MiMo-V2-Omni có thể hiểu môi trường phức tạp đa phương thức, tự lập kế hoạch và thực thi, đồng thời điều chỉnh chiến lược theo thời gian thực khi gặp tình huống bất thường, cuối cùng cung cấp kết quả hoàn chỉnh theo kiểu end-to-end.
Mô hình đã mở API chính thức, hỗ trợ 256K context với mức giá:
Ngoài ra, MiMo-V2-Omni cùng với các framework OpenClaw, OpenCode, KiloCode, Blackbox và Cline cung cấp API miễn phí trong 1 tuần cho các nhà phát triển toàn cầu.
MiMo-V2-TTS là mô hình tổng hợp giọng nói do Xiaomi tự phát triển. Dựa trên Audio Tokenizer tự nghiên cứu và kiến trúc mô hình hóa kết hợp giọng nói – văn bản đa mã bản, cùng với quá trình tiền huấn luyện quy mô lớn hàng trăm triệu giờ dữ liệu và học tăng cường đa chiều, mô hình đạt được khả năng kiểm soát phong cách giọng nói ở nhiều cấp độ.
MiMo-V2-TTS hỗ trợ điều chỉnh từ phong cách tổng thể đến cảm xúc cục bộ, có thể thực hiện chuyển đổi ngữ điệu và cảm xúc trong cùng một câu, tái hiện nhịp điệu tự nhiên của giọng nói con người. Khi hát, mô hình cũng có thể thể hiện chính xác cao độ và nhịp điệu, mang lại giọng hát tự nhiên và giàu biểu cảm.
Trong quá trình huấn luyện, mô hình trước tiên học được khả năng liên kết và hiểu sinh đa phương thức thông qua tiền huấn luyện quy mô lớn dữ liệu giọng nói – văn bản, sau đó được tinh chỉnh bằng dữ liệu chất lượng cao để đạt khả năng điều khiển đa phong cách.
Để phát huy tối đa khả năng tạo giọng biểu cảm, Xiaomi còn áp dụng học tăng cường đa chiều, tối ưu các yếu tố như nhịp điệu tự nhiên, chất lượng âm thanh ổn định, độ chính xác phát âm, khả năng clone giọng và cách biểu đạt phù hợp trong các ngữ cảnh khác nhau.
Nhờ kiến trúc mã bản nhiều lớp, mô hình có thể biểu diễn giọng nói trong không gian token rời rạc độ trung thực cao, giữ lại thông tin phong phú của âm thanh gốc, giúp tối ưu hiệu quả trong giai đoạn học tăng cường.
MiMo-V2-TTS hỗ trợ điều khiển phong cách giọng nói đa cấp độ từ tổng thể đến cục bộ. Người dùng có thể thiết lập tông giọng chung bằng ngôn ngữ tự nhiên, đồng thời điều chỉnh chi tiết cảm xúc trong từng đoạn câu, tạo ra chuyển đổi cảm xúc mượt mà trong cùng một câu.
Mô hình còn hỗ trợ khả năng biểu đạt đa dạng: phát âm tự nhiên nhiều phương ngữ, diễn xuất theo vai trò và tổng hợp giọng hát chất lượng cao — cho phép một mô hình vừa nói, vừa diễn, vừa hát, hỗ trợ nhiều giọng địa phương tại Trung Quốc như Đông Bắc, Tứ Xuyên, Hà Nam, Quảng Đông, Đài Loan…

 github.com
github.com

Mô hình nền tảng flagship dành cho kỷ nguyên Agent của Xiaomi: Xiaomi MiMo-V2-Pro
Xiaomi MiMo-V2-Pro được thiết kế chuyên biệt cho các kịch bản làm việc Agent cường độ cao trong thế giới thực. Mô hình sở hữu tổng số tham số vượt quá 1T (42B tham số kích hoạt), sử dụng kiến trúc attention lai sáng tạo và hỗ trợ độ dài ngữ cảnh siêu dài 1 triệu token. Xiaomi cũng tiếp tục mở rộng năng lực tính toán trong nhiều kịch bản Agent đa dạng hơn, qua đó mở rộng không gian hành động của trí tuệ, hiện thực hóa bước tổng quát hóa quan trọng từ Coding sang Claw. Trên bảng xếp hạng Artificial Analysis, MiMo-V2-Pro đứng thứ 8 toàn cầu, thứ 2 tại Trung Quốc.
MiMo-V2-Pro được tối ưu sâu cho các kịch bản Agent. Thông qua SFT và RL trên nhiều dạng Agent Scaffold phức tạp, mô hình có năng lực gọi công cụ và suy luận nhiều bước mạnh mẽ hơn. Trên các bảng đánh giá tiêu chuẩn OpenClaw như PinchBench, ClawEval, hiệu quả của MiMo-V2-Pro nằm trong top đầu thế giới. Đồng thời, nhờ cửa sổ ngữ cảnh 1 triệu token, mô hình có thể dễ dàng hỗ trợ các ứng dụng Claw phức tạp trong thực tế.
Hiện mô hình đã mở API chính thức, hỗ trợ ngữ cảnh 1 triệu token, với mức giá tính theo dung lượng sử dụng:
- Trong phạm vi 256K context: input 1 USD / triệu token, output 3 USD / triệu token
- Trong phạm vi 1M context: input 2 USD / triệu token, output 6 USD / triệu token
Bạn có thể truy cập https://platform.xiaomimimo.com để kết nối API ngay.
Module MiMo Claw hiện đã tích hợp hoàn toàn với hệ sinh thái Kingsoft WebOffice, hỗ trợ nguyên bản các định dạng Word, Excel, PPT và PDF, bao phủ hơn 95% nhu cầu tài liệu hàng ngày.
Engine suy luận nền tảng của Xiaomi MiMo cũng đã tích hợp ở cấp framework với hệ sinh thái Kingsoft Office. WPS Lingxi hiện đã truy cập MiMo-V2-Pro, cho phép đặt câu hỏi hoặc giao nhiệm vụ cho Lingxi Claw, giúp công việc văn phòng hiệu quả hơn.
Mô hình nền tảng đa phương thức dành cho kỷ nguyên Agent: Xiaomi MiMo-V2-Omni
MiMo-V2-Omni được tạo ra cho các kịch bản tương tác và thực thi đa phương thức phức tạp trong thế giới thực, có thể kết nối liền mạch với nhiều framework Agent, thực hiện bước nhảy từ “hiểu” sang “thao tác”, giảm đáng kể rào cản triển khai Agent đa phương thức.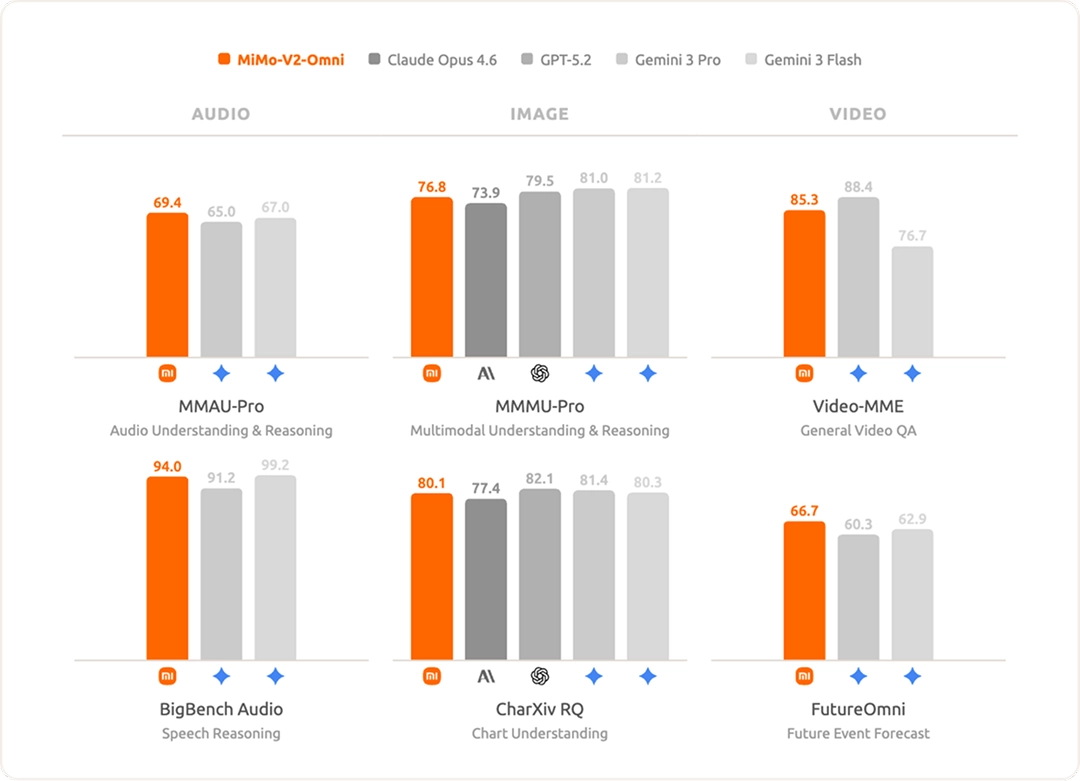
Về hiểu hình ảnh, MiMo-V2-Omni thể hiện khả năng suy luận thị giác đa lĩnh vực và phân tích biểu đồ phức tạp, vượt Claude Opus 4.6, tiệm cận các mô hình đóng hàng đầu như Gemini 3 Pro.
Về video, mô hình hỗ trợ đầu vào audio-video gốc, thực hiện hiểu video đa phương thức thực sự. Thông qua pretraining video sáng tạo, mô hình có khả năng nhận thức ngữ cảnh mạnh mẽ và suy luận tương lai.
MiMo-V2-Omni có thể hiểu môi trường phức tạp đa phương thức, tự lập kế hoạch và thực thi, đồng thời điều chỉnh chiến lược theo thời gian thực khi gặp tình huống bất thường, cuối cùng cung cấp kết quả hoàn chỉnh theo kiểu end-to-end.
Mô hình đã mở API chính thức, hỗ trợ 256K context với mức giá:
- Input 0.4 USD / triệu token
- Output 2 USD / triệu token
Ngoài ra, MiMo-V2-Omni cùng với các framework OpenClaw, OpenCode, KiloCode, Blackbox và Cline cung cấp API miễn phí trong 1 tuần cho các nhà phát triển toàn cầu.
Mô hình tổng hợp giọng nói dành cho kỷ nguyên Agent: Xiaomi MiMo-V2-TTS
MiMo-V2-TTS là mô hình tổng hợp giọng nói do Xiaomi tự phát triển. Dựa trên Audio Tokenizer tự nghiên cứu và kiến trúc mô hình hóa kết hợp giọng nói – văn bản đa mã bản, cùng với quá trình tiền huấn luyện quy mô lớn hàng trăm triệu giờ dữ liệu và học tăng cường đa chiều, mô hình đạt được khả năng kiểm soát phong cách giọng nói ở nhiều cấp độ.
MiMo-V2-TTS hỗ trợ điều chỉnh từ phong cách tổng thể đến cảm xúc cục bộ, có thể thực hiện chuyển đổi ngữ điệu và cảm xúc trong cùng một câu, tái hiện nhịp điệu tự nhiên của giọng nói con người. Khi hát, mô hình cũng có thể thể hiện chính xác cao độ và nhịp điệu, mang lại giọng hát tự nhiên và giàu biểu cảm.
Trong quá trình huấn luyện, mô hình trước tiên học được khả năng liên kết và hiểu sinh đa phương thức thông qua tiền huấn luyện quy mô lớn dữ liệu giọng nói – văn bản, sau đó được tinh chỉnh bằng dữ liệu chất lượng cao để đạt khả năng điều khiển đa phong cách.
Để phát huy tối đa khả năng tạo giọng biểu cảm, Xiaomi còn áp dụng học tăng cường đa chiều, tối ưu các yếu tố như nhịp điệu tự nhiên, chất lượng âm thanh ổn định, độ chính xác phát âm, khả năng clone giọng và cách biểu đạt phù hợp trong các ngữ cảnh khác nhau.
Nhờ kiến trúc mã bản nhiều lớp, mô hình có thể biểu diễn giọng nói trong không gian token rời rạc độ trung thực cao, giữ lại thông tin phong phú của âm thanh gốc, giúp tối ưu hiệu quả trong giai đoạn học tăng cường.
MiMo-V2-TTS hỗ trợ điều khiển phong cách giọng nói đa cấp độ từ tổng thể đến cục bộ. Người dùng có thể thiết lập tông giọng chung bằng ngôn ngữ tự nhiên, đồng thời điều chỉnh chi tiết cảm xúc trong từng đoạn câu, tạo ra chuyển đổi cảm xúc mượt mà trong cùng một câu.
Mô hình còn hỗ trợ khả năng biểu đạt đa dạng: phát âm tự nhiên nhiều phương ngữ, diễn xuất theo vai trò và tổng hợp giọng hát chất lượng cao — cho phép một mô hình vừa nói, vừa diễn, vừa hát, hỗ trợ nhiều giọng địa phương tại Trung Quốc như Đông Bắc, Tứ Xuyên, Hà Nam, Quảng Đông, Đài Loan…
GitHub - XiaomiMiMo/MiMo-V2-Flash: MiMo-V2-Flash: Efficient Reasoning, Coding, and Agentic Foundation Model
MiMo-V2-Flash: Efficient Reasoning, Coding, and Agentic Foundation Model - XiaomiMiMo/MiMo-V2-Flash
github.com
BÀI MỚI ĐANG THẢO LUẬN