Trí tuệ nhân tạo (AI) có khả năng theo dõi trạng thái tâm lý của người khác, tương đương hoặc vượt qua khả năng của con người.
Vn-Z.vn Ngày 26 tháng 05 năm 2024, Trong số mới nhất của tạp chí "Nature Human Behaviour" phát hành vào cuối tháng này, có đăng một bài báo nghiên cứu về trí tuệ nhân tạo (AI). Bài báo này đề cập rằng trong các nhiệm vụ kiểm tra khả năng theo dõi trạng thái tâm lý của người khác, hai loại mô hình ngôn ngữ lớn (large language models) của AI, trong những tình huống cụ thể, đã thể hiện khả năng tương đương hoặc thậm chí vượt qua con người.
Là một yếu tố then chốt trong giao tiếp và tạo ra sự đồng cảm giữa con người, khả năng tâm lý (còn gọi là lý thuyết tâm lý) rất quan trọng đối với tương tác xã hội của con người.
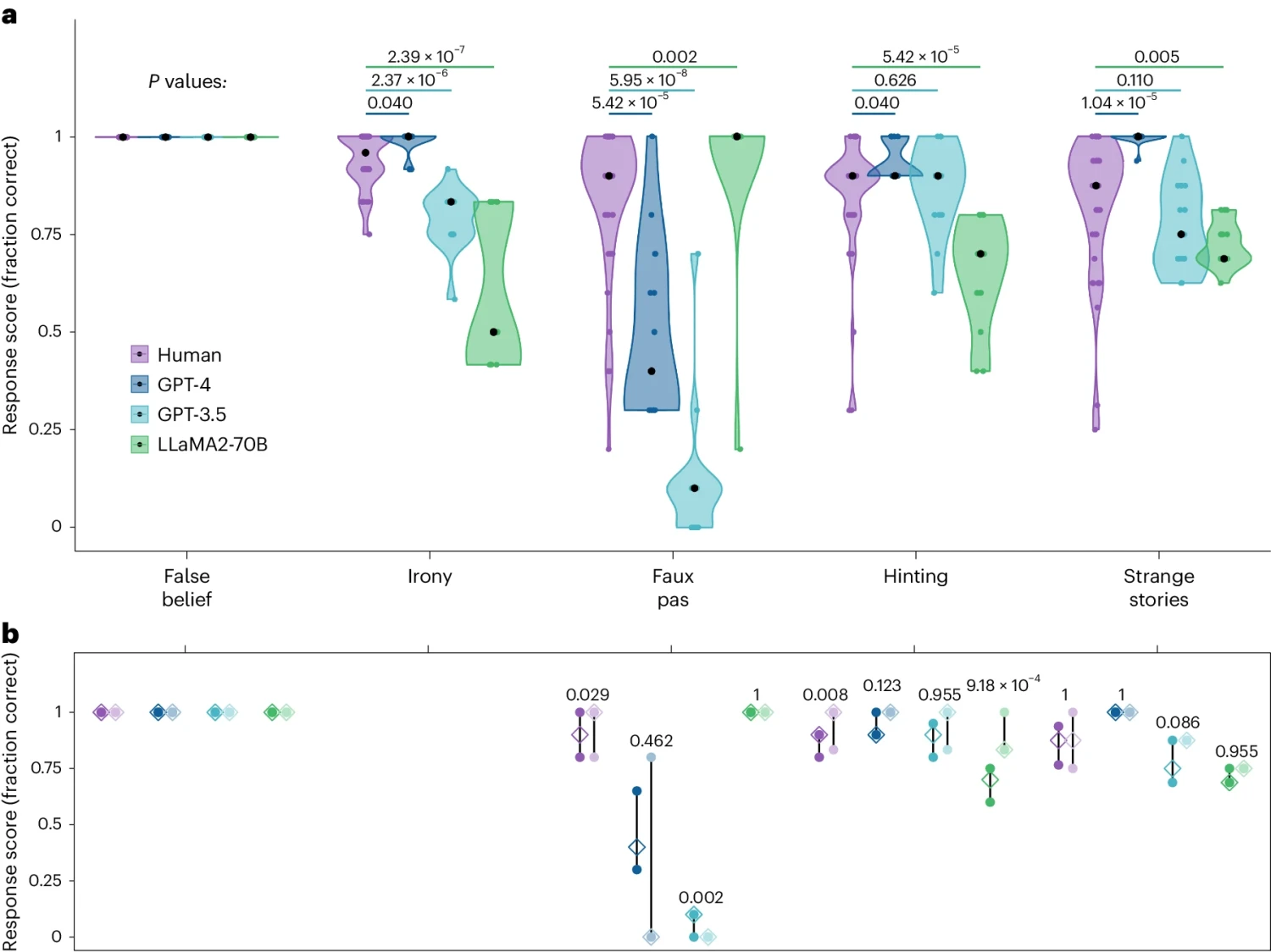
Tác giả chính của bài báo này - James W. A. Strachan từ Trung tâm Y khoa Đại học Hamburg-Eppendorf, Đức, cùng với các đồng nghiệp và cộng tác viên đã chọn những nhiệm vụ có thể kiểm tra các khía cạnh khác nhau của lý thuyết tâm lý, bao gồm phát hiện các ý nghĩ sai lầm, hiểu ngôn ngữ gián tiếp và nhận diện sự thất lễ.
Nhóm nghiên cứu đã sử dụng các mô hình GPT và LLaMA2 để tiến hành thử nghiệm và so sánh với 1907 người.
Kết quả cho thấy, mô hình GPT trong việc nhận diện yêu cầu gián tiếp, ý nghĩ sai lầm và sự lừa dối có thể đạt và thậm chí vượt mức trung bình của con người trong một số trường hợp, trong khi đó, hiệu suất của LLaMA2 lại kém hơn mức trung bình của con người. Trong việc nhận diện sự thất lễ, LLaMA2 lại tốt hơn con người, nhưng GPT lại có biểu hiện không tốt.
Sự tương tác của LLaMA2 được chứng minh là do mức độ "thiên lệch" trong câu trả lời thấp, chứ không thực sự nhạy cảm với sự thất lễ, còn việc GPT "biểu hiện không tốt" là do thái độ "quá bảo thủ" trong việc kiên trì với kết luận, chứ không phải do lỗi suy luận.
Kết quả chính:
- GPT-4 đạt hoặc vượt trội so với con người trong việc nhận diện yêu cầu gián tiếp, niềm tin sai và lạc hướng, nhưng gặp khó khăn trong việc phát hiện lỗi lầm xã hội.
- LLaMA2 vượt trội con người duy nhất trong bài kiểm tra lỗi lầm xã hội, nhưng điều này có thể do sự thiên vị trong việc cho rằng người nói không biết ngữ cảnh.
- GPT-3.5 thất bại trong bài kiểm tra lỗi lầm xã hội do thái độ quá thận trọng trong việc đưa ra kết luận.
- Cả GPT-4 và GPT-3.5 đều có thể suy luận tâm lý về nhân vật nhưng GPT-4 dường như ít cam kết vào kết luận hơn so với con người.
Các tác giả nhấn mạnh tầm quan trọng của việc kiểm tra có hệ thống để đảm bảo so sánh không phù phiếu giữa trí tuệ nhân tạo và con người. Họ cũng thảo luận những hạn chế của LLM do thiếu sự lưu tâm và nhận thức thứ nhất, dẫn đến những khác biệt trong cách giải quyết bất định xã hội so với con người. Tổng quan, nghiên cứu này cung cấp bằng chứng về khả năng lý luận tương tự con người của LLM nhưng cũng nêu bật những khác biệt quan trọng cần được nghiên cứu thêm.
Chi tiết nghiên cứu
 www.nature.com
www.nature.com
Fig. 1: Performance of human (purple), GPT-4 (dark blue), GPT-3.5 (light blue) and LLaMA2-70B (green) on the battery of theory of mind tests.
Tác giả chính của bài báo này - James W. A. Strachan từ Trung tâm Y khoa Đại học Hamburg-Eppendorf, Đức, cùng với các đồng nghiệp và cộng tác viên đã chọn những nhiệm vụ có thể kiểm tra các khía cạnh khác nhau của lý thuyết tâm lý, bao gồm phát hiện các ý nghĩ sai lầm, hiểu ngôn ngữ gián tiếp và nhận diện sự thất lễ.
Nhóm nghiên cứu đã sử dụng các mô hình GPT và LLaMA2 để tiến hành thử nghiệm và so sánh với 1907 người.
Kết quả cho thấy, mô hình GPT trong việc nhận diện yêu cầu gián tiếp, ý nghĩ sai lầm và sự lừa dối có thể đạt và thậm chí vượt mức trung bình của con người trong một số trường hợp, trong khi đó, hiệu suất của LLaMA2 lại kém hơn mức trung bình của con người. Trong việc nhận diện sự thất lễ, LLaMA2 lại tốt hơn con người, nhưng GPT lại có biểu hiện không tốt.
Sự tương tác của LLaMA2 được chứng minh là do mức độ "thiên lệch" trong câu trả lời thấp, chứ không thực sự nhạy cảm với sự thất lễ, còn việc GPT "biểu hiện không tốt" là do thái độ "quá bảo thủ" trong việc kiên trì với kết luận, chứ không phải do lỗi suy luận.
Kết quả chính:
- GPT-4 đạt hoặc vượt trội so với con người trong việc nhận diện yêu cầu gián tiếp, niềm tin sai và lạc hướng, nhưng gặp khó khăn trong việc phát hiện lỗi lầm xã hội.
- LLaMA2 vượt trội con người duy nhất trong bài kiểm tra lỗi lầm xã hội, nhưng điều này có thể do sự thiên vị trong việc cho rằng người nói không biết ngữ cảnh.
- GPT-3.5 thất bại trong bài kiểm tra lỗi lầm xã hội do thái độ quá thận trọng trong việc đưa ra kết luận.
- Cả GPT-4 và GPT-3.5 đều có thể suy luận tâm lý về nhân vật nhưng GPT-4 dường như ít cam kết vào kết luận hơn so với con người.
Các tác giả nhấn mạnh tầm quan trọng của việc kiểm tra có hệ thống để đảm bảo so sánh không phù phiếu giữa trí tuệ nhân tạo và con người. Họ cũng thảo luận những hạn chế của LLM do thiếu sự lưu tâm và nhận thức thứ nhất, dẫn đến những khác biệt trong cách giải quyết bất định xã hội so với con người. Tổng quan, nghiên cứu này cung cấp bằng chứng về khả năng lý luận tương tự con người của LLM nhưng cũng nêu bật những khác biệt quan trọng cần được nghiên cứu thêm.
Chi tiết nghiên cứu
Testing theory of mind in large language models and humans - Nature Human Behaviour
Testing two families of large language models (LLMs) (GPT and LLaMA2) on a battery of measurements spanning different theory of mind abilities, Strachan et al. find that the performance of LLMs can mirror that of humans on most of these tasks. The authors explored potential reasons for this.
www.nature.com
BÀI MỚI ĐANG THẢO LUẬN