Hôm nay, NVIDIA đã chính thức ra mắt card tăng tốc AI mạnh nhất GB200 tại sự kiện nhà phát triển GTC và dự kiến xuất xưởng vào cuối năm nay.

GB200 sử dụng kiến trúc bộ xử lý đồ họa AI thế hệ mới Blackwell. Jen-Hsun cho biết tại sự kiện GTC: "Hopper đã rất tốt rồi, nhưng chúng tôi cần một GPU mạnh hơn."
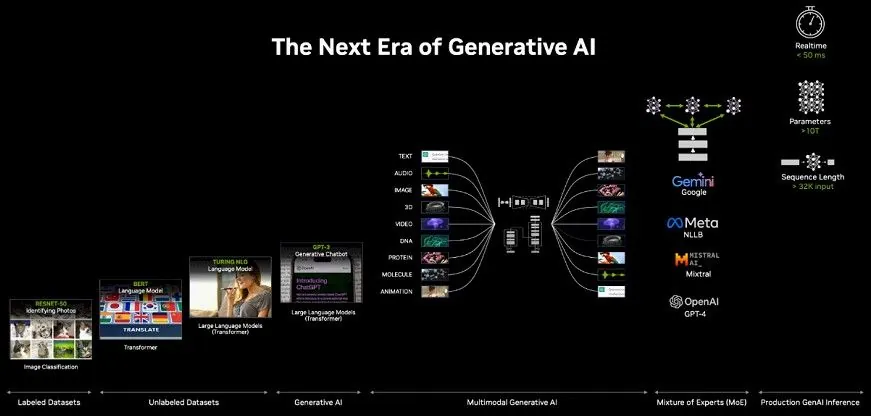
NVIDIA hiện nâng cấp kiến trúc GPU 2 năm một lần để cải thiện đáng kể hiệu suất. NVIDIA đã phát hành card tăng tốc H100 dựa trên kiến trúc Hopper vào năm 2022 và hiện tại card tăng tốc dựa trên Blackwell mạnh hơn và xử lý tốt hơn các tác vụ liên quan đến AI.
Jen-Hsun cho biết hiệu suất AI của Blackwell có thể đạt tới 20 petaflop, trong khi H100 chỉ là 4 petaflop. Sức mạnh xử lý bổ sung sẽ cho phép các công ty AI đào tạo các mô hình lớn hơn, phức tạp hơn.

GPU Blackwell cồng kềnh và được khắc bằng quy trình 4nm (4NP) của TSMC, tích hợp hai khuôn được sản xuất độc lập với tổng cộng 208 tỷ bóng bán dẫn, sau đó bó các con chip lại như dây kéo thông qua NVLink 5.0.

Nvidia cho biết mỗi Blackwell Die có sức mạnh tính toán dấu phẩy động cao hơn 25% so với Hopper Die và với hai chip Blackwell trong mỗi gói, tổng hiệu suất tăng lên 2,5 lần. Nếu xử lý các phép toán dấu phẩy động có độ chính xác tám FP4, hiệu suất có thể được cải thiện lên đến 5 lần. Hiệu suất khối lượng công việc thực tế có thể cao hơn tùy thuộc vào dung lượng bộ nhớ và cấu hình băng thông của các thiết bị Blackwell khác nhau.
Nvidia kết nối mỗi Die bằng 10 TB/giây NVLink 5.0, được gọi chính thức là NV-HBI. Các cổng NVLink 5.0 của tổ hợp Blackwell cung cấp băng thông 1,8 TB/giây, nhanh gấp đôi tốc độ của các cổng NVLink 4.0 trên GPU Hopper.
Nvidia GB200 bao gồm hai GPU B200 Blackwell và CPU Grace dựa trên Arm, hiệu suất suy luận mô hình ngôn ngữ lớn cao hơn 30 lần so với H100, đồng thời chi phí và mức tiêu thụ năng lượng giảm xuống còn 1/25.

NVIDIA Grace Blackwell
Quá trình đào tạo mô hình với 1,8 nghìn tỷ tham số trước đây cần 8.000 GPU Hopper và 15 megawatt điện. Giờ đây, 2.000 GPU Blackwell có thể thực hiện công việc này mà chỉ sử dụng 4 megawatt điện.
Trên benchmark GPT-3 LLM với 175 tỷ thông số, Nvidia tuyên bố GB200 hoạt động tốt hơn 7 lần và đào tạo nhanh hơn H100 gấp 4 lần.

NVIDIA cũng cung cấp dịch vụ thành phẩm cho các doanh nghiệp có nhu cầu lớn, cung cấp các lô máy chủ hoàn chỉnh, chẳng hạn như máy chủ GB200 NVL72, cung cấp 36 CPU và 72 GPU Blackwell, đồng thời cung cấp giải pháp làm mát bằng nước tích hợp . Hiệu suất huấn luyện AI có thể đạt được tổng cộng 720 petaflop hoặc hiệu xuất suy luận đạt 1.440 petaflop (hay còn gọi là 1,4 exaflop). Hệ thống này được kết nối bởi gần 2 dặm đoạn cáp với tổng số 5.000 sợi cáp riêng lẻ.
Mỗi khay trong giá chứa hai chip GB200 hoặc hai công tắc NVLink, với tổng số 18 chip GB200 và chín công tắc NVLink trên mỗi giá, Nvidia cho biết có thể hỗ trợ tổng cộng 27 nghìn tỷ mô hình tham số trong một giá. Để so sánh, mô hình tham số của GPT-4 là khoảng 1,7 nghìn tỷ.
Nvidia cho biết Amazon, Google, Microsoft và Oracle đều có kế hoạch cung cấp giá đỡ NVL72 trong các dịch vụ đám mây của họ, nhưng không rõ họ sẽ mua bao nhiêu.
Amazon AWS đã lên kế hoạch mua một cụm máy chủ gồm 20.000 chip GB200, có thể triển khai một mô hình với 27 nghìn tỷ tham số.
Dưới đây là cụm DGX Superpod cho DGX GB200, kết hợp tám hệ thống thành một với tổng số 288 CPU, 576 GPU, bộ nhớ 240TB và sức mạnh tính toán FP4 11,5 exaflop.

Nvidia cho biết hệ thống của họ có thể mở rộng tới hàng chục nghìn siêu chip GB200, được kết nối với nhau bằng mạng 800Gbps thông qua Quantum-X800 InfiniBand mới (tối đa 144 kết nối) hoặc Spectrum-X800 Ethernet (tối đa 64 kết nối).
NVIDIA vẫn chưa công bố thông tin về giá của GB200 và toàn bộ giải pháp.
NVIDIA hiện nâng cấp kiến trúc GPU 2 năm một lần để cải thiện đáng kể hiệu suất. NVIDIA đã phát hành card tăng tốc H100 dựa trên kiến trúc Hopper vào năm 2022 và hiện tại card tăng tốc dựa trên Blackwell mạnh hơn và xử lý tốt hơn các tác vụ liên quan đến AI.
Jen-Hsun cho biết hiệu suất AI của Blackwell có thể đạt tới 20 petaflop, trong khi H100 chỉ là 4 petaflop. Sức mạnh xử lý bổ sung sẽ cho phép các công ty AI đào tạo các mô hình lớn hơn, phức tạp hơn.
Nvidia kết nối mỗi Die bằng 10 TB/giây NVLink 5.0, được gọi chính thức là NV-HBI. Các cổng NVLink 5.0 của tổ hợp Blackwell cung cấp băng thông 1,8 TB/giây, nhanh gấp đôi tốc độ của các cổng NVLink 4.0 trên GPU Hopper.
Nvidia GB200 bao gồm hai GPU B200 Blackwell và CPU Grace dựa trên Arm, hiệu suất suy luận mô hình ngôn ngữ lớn cao hơn 30 lần so với H100, đồng thời chi phí và mức tiêu thụ năng lượng giảm xuống còn 1/25.
NVIDIA Grace Blackwell
Quá trình đào tạo mô hình với 1,8 nghìn tỷ tham số trước đây cần 8.000 GPU Hopper và 15 megawatt điện. Giờ đây, 2.000 GPU Blackwell có thể thực hiện công việc này mà chỉ sử dụng 4 megawatt điện.
Trên benchmark GPT-3 LLM với 175 tỷ thông số, Nvidia tuyên bố GB200 hoạt động tốt hơn 7 lần và đào tạo nhanh hơn H100 gấp 4 lần.
Mỗi khay trong giá chứa hai chip GB200 hoặc hai công tắc NVLink, với tổng số 18 chip GB200 và chín công tắc NVLink trên mỗi giá, Nvidia cho biết có thể hỗ trợ tổng cộng 27 nghìn tỷ mô hình tham số trong một giá. Để so sánh, mô hình tham số của GPT-4 là khoảng 1,7 nghìn tỷ.
Nvidia cho biết Amazon, Google, Microsoft và Oracle đều có kế hoạch cung cấp giá đỡ NVL72 trong các dịch vụ đám mây của họ, nhưng không rõ họ sẽ mua bao nhiêu.
Amazon AWS đã lên kế hoạch mua một cụm máy chủ gồm 20.000 chip GB200, có thể triển khai một mô hình với 27 nghìn tỷ tham số.
Dưới đây là cụm DGX Superpod cho DGX GB200, kết hợp tám hệ thống thành một với tổng số 288 CPU, 576 GPU, bộ nhớ 240TB và sức mạnh tính toán FP4 11,5 exaflop.
NVIDIA vẫn chưa công bố thông tin về giá của GB200 và toàn bộ giải pháp.
BÀI MỚI ĐANG THẢO LUẬN
