Meta ra mắt Chatbot AI "Tắc kè hoa" thách thức GPT-4o, thông số 34B dẫn đầu cuộc cách mạng đa phương thức!
Chưa đầy một tuần sau khi GPT-4o được ra mắt, mẫu mới đầu tiên dám thách thức bot AI này đã ra đời! Gần đây, nhóm Meta đã phát hành chatbot "Chameleon" ( Tắc kè hoa) sử dụng công nghệ "phương thức hỗn hợp", có thể xử lý liền mạch văn bản và hình ảnh trong một mạng lưới thần kinh duy nhất. Hiệu suất của mô hình tham số 34B được đào tạo với 10 nghìn tỷ mã thông báo gần bằng GPT-4V.

Sự xuất hiện của GPT-4o một lần nữa đã tạo ra mô hình mới cho việc phát triển mô hình đa phương thức! OpenAI gọi nó là mô hình đa phương thức "bản địa" đầu tiên, có nghĩa là GPT-4o khác với tất cả các mô hình trước đó.
Các mô hình cơ bản đa phương thức truyền thống thường sử dụng một "bộ mã hóa" hoặc "bộ giải mã" cụ thể cho từng phương thức để phân tách các phương thức khác nhau.
Tuy nhiên, cách tiếp cận này hạn chế khả năng của mô hình trong việc kết hợp thông tin đa phương thức một cách hiệu quả.
GPT-4o là mô hình được đào tạo "từ đầu đến cuối" bao gồm văn bản, hình ảnh và âm thanh. Tất cả đầu vào và đầu ra đều được xử lý bởi một mạng thần kinh duy nhất.
Bằng việc các nhà nghiên cứu từ nhóm Meta đã phát hành “mô hình cơ sở phương thức hỗn hợp” – Chameleon, có thể đây là mẫu AI đầu tiên trong ngành có đủ khả năng cạnh tranh với ChatGPT-4o.
Trong bài báo được chia sẻ trên tạp chí khoa học arxiv.org
Giống như GPT-4o, Chameleon áp dụng kiến trúc Transformer thống nhất và sử dụng các phương thức kết hợp văn bản, hình ảnh và mã để hoàn thành quá trình đào tạo.
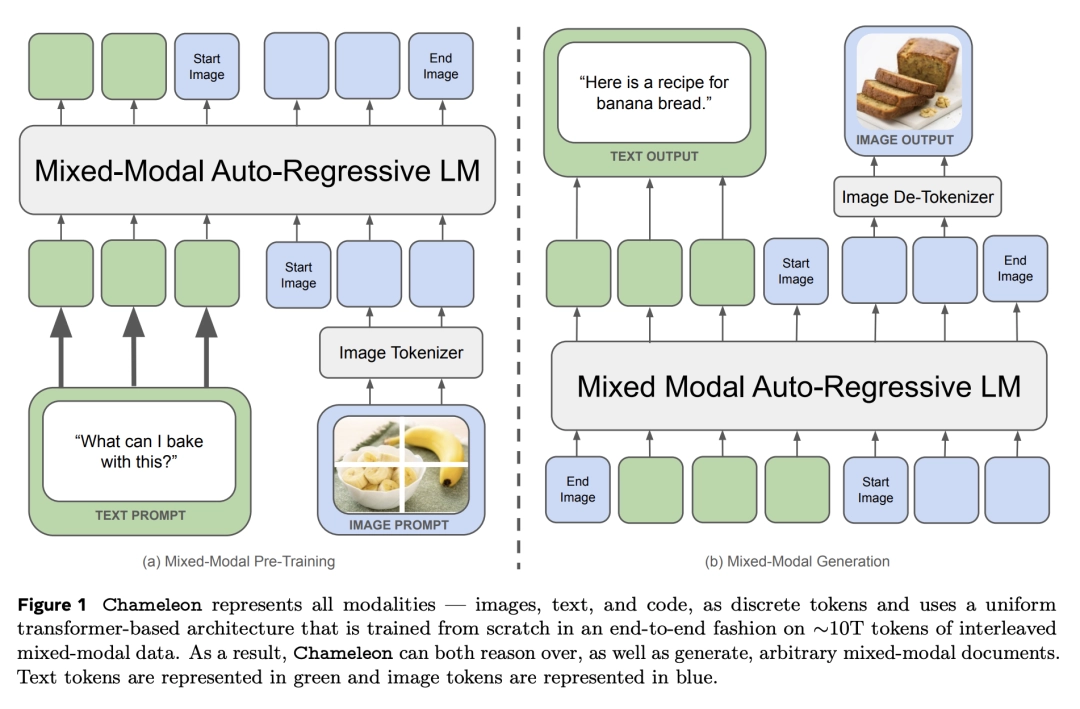
Theo cách tương tự như tạo văn bản, hình ảnh được "mã hóa" (mã thông báo) một cách riêng biệt và cuối cùng, một chuỗi văn bản và hình ảnh xen kẽ được tạo ra và lý giải.
Với phương pháp "kết hợp sớm" này, tất cả các quy trình đều được ánh xạ tới một không gian biểu diễn chung ngay từ đầu, do đó mô hình có thể xử lý văn bản và hình ảnh một cách liền mạch.

Chameleon tạo ra nội dung đa phương thức
Thiết kế này đã mang lại những thách thức kỹ thuật lớn cho việc huấn luyện mô hình. Để đối phó với điều này, nhóm nghiên cứu Meta đã giới thiệu một loạt các đổi mới về kiến trúc và kỹ thuật huấn luyện.
Kết quả cho thấy, trong các nhiệm vụ chỉ liên quan đến văn bản, Chameleon với 34 tỷ tham số (được huấn luyện trên 10 nghìn tỷ token đa phương thức) có hiệu suất tương đương với Gemini-Pro.
Trên các tiêu chuẩn về trả lời câu hỏi trực quan và gán nhãn hình ảnh, Chameleon thiết lập chuẩn mực mới về SOTA, với hiệu suất gần bằng GPT-4V.
Tuy nhiên, dù là GPT-4o hay Chameleon, cả hai đều là những mô hình nền tảng đa phương thức "nguyên bản" thế hệ mới đang trong giai đoạn khám phá ban đầu.
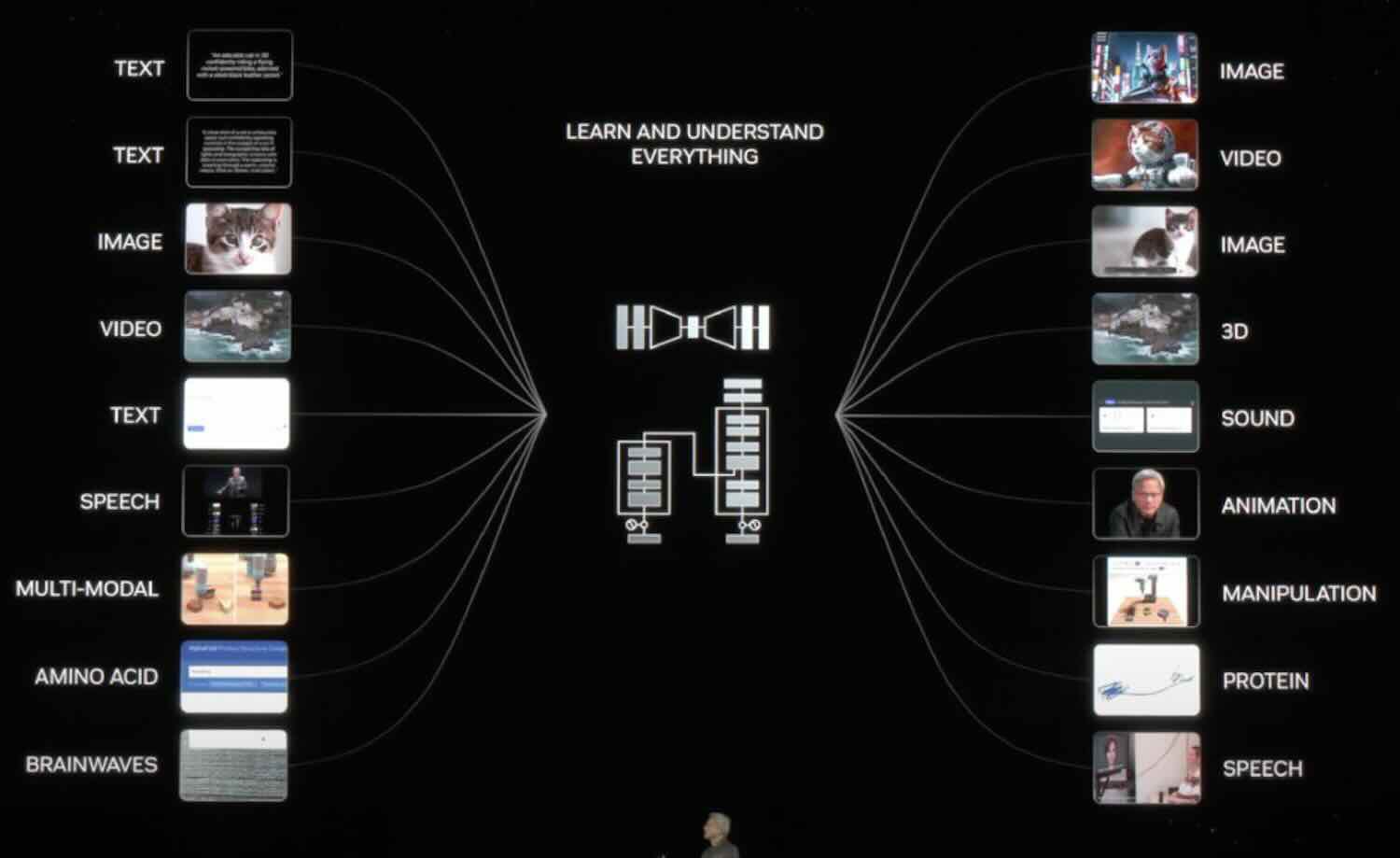
Tại sự kiện GTC 2024, CEO Nvida Mr Huang cũng đã mô tả một bước quan trọng tiến tới tầm nhìn cuối cùng về AGI — sự tương tác giữa các phương thức khác nhau.
GPT-4o nguồn mở tiếp theo sắp ra mắt ?
Việc Meta phát hành Chameleon đơn giản là phản hồi nhanh nhất đối với GPT-4o. Một số người dùng internet cho rằng token đi vào và token đi ra, điều này đơn giản là không thể giải thích được.
Thậm chí còn có những tuyên bố rằng OOS sẽ bắt kịp sau nghiên cứu rất vững chắc được công bố sau sự ra đời của GPT-4o. Tuy nhiên, hiện tại mô hình Chameleon hỗ trợ các phương thức chủ yếu là văn bản hình ảnh. Thiếu khả năng giọng nói như GPT-4o.
Người ta cho rằng sau đó chỉ cần thêm một phương thức khác (âm thanh), mở rộng bộ dữ liệu huấn luyện, “xào nấu” một lúc là sẽ có GPT-4o…? Có lẽ sẽ không lâu nữa chúng ta sẽ có phiên bản nguồn mở của GPT-4o.
Chi tiết kỹ thuật của mô hình Chameleon. Kiến trúc công nghệ
Trong bài báo được chia sẻ trên tạp chí khoa học arxiv.org Meta chia sẻ đầu tiên về Chameleon cho rằng: Nhiều mô hình mới được phát hành gần đây vẫn chưa thực sự triển khai "đa phương thức" một cách triệt để.
Mặc dù các mô hình này sử dụng phương pháp huấn luyện đầu-cuối, nhưng vẫn thực hiện việc mô hình hóa các phương thức khác nhau một cách riêng lẻ, sử dụng các bộ mã hóa hoặc giải mã riêng biệt.
Như đã đề cập ở phần đầu, cách làm này hạn chế khả năng xử lý thông tin liên phương thức của mô hình và cũng khó tạo ra các tài liệu đa phương thức thực sự chứa bất kỳ dạng thông tin nào.
Để cải thiện nhược điểm này, Meta đã đề xuất một loạt các mô hình nền tảng "hỗn hợp phương thức" mang tên Chameleon — có khả năng tạo ra nội dung văn bản và hình ảnh được đan xen với nhau một cách tự do.

Kết quả của Chameleon là văn bản và hình ảnh có thể xuất hiện đan xen nhau. Mô hình nền tảng "hỗn hợp phương thức" của Chameleon không chỉ được huấn luyện từ đầu bằng phương pháp đầu-cuối mà còn kết hợp thông tin từ tất cả các phương thức trong quá trình huấn luyện và sử dụng một kiến trúc thống nhất để xử lý.
Để làm được điều này, tất cả thông tin được biểu diễn dưới dạng token, cho phép ánh xạ thông tin từ tất cả các phương thức vào cùng một không gian vector và Transformer có thể xử lý một cách liền mạch. Tuy nhiên, phương pháp này gặp các thách thức về ổn định tối ưu hóa và khả năng mở rộng của mô hình.
Để khắc phục, bài báo đã đưa ra các cải tiến về kiến trúc mô hình và sử dụng các kỹ thuật huấn luyện như QK chuẩn hóa và Zloss. Ngoài ra, bài báo cũng đề xuất phương pháp tinh chỉnh từ mô hình ngôn ngữ lớn thuần văn bản sang mô hình đa phương thức.
Hình ảnh "Mã thông báo"
Để thể hiện tất cả các phương thức dưới dạng mã thông báo, trước tiên cần có một mã thông báo mạnh mẽ.
Để đạt được mục tiêu này, nhóm của Chameleon đã phát triển một công cụ mã hóa hình ảnh mới dựa trên bài báo trước đó của Meta. Dựa trên sổ mã có kích thước 8192, hình ảnh có thông số kỹ thuật 512×512 được mã hóa thành 1024 mã thông báo riêng biệt.
Bộ phân tách văn bản sử dụng thư viện mã nguồn mở sentencepiece do Google phát triển. Bộ phân tách này đã được huấn luyện để chứa đồng thời 65536 token cho văn bản và 8192 token cho hình ảnh.

Tập huấn trước
Để phát huy hết tiềm năng của “các phương thức hỗn hợp”, dữ liệu huấn luyện cũng được chia nhỏ và trộn lẫn với các phương thức khác nhau để trình bày cho mô hình, bao gồm văn bản thuần túy, cặp văn bản-hình ảnh và tài liệu đa phương thức có văn bản và hình ảnh xen kẽ. .
Dữ liệu văn bản thuần túy bao gồm tất cả dữ liệu tiền huấn luyện mà Llama 2 và CodeLlama đã sử dụng, tổng cộng là 2,9 nghìn tỷ token.
Các cặp văn bản-hình ảnh bao gồm một số dữ liệu công khai, với tổng cộng 1,4 tỷ cặp và 1,5 nghìn tỷ token.
Đối với dữ liệu đan xen giữa văn bản và hình ảnh, bài báo đặc biệt nhấn mạnh không bao gồm dữ liệu từ các sản phẩm của Meta, mà hoàn toàn sử dụng các nguồn dữ liệu công khai, tổng hợp được 400 tỷ token.
Việc tiền huấn luyện của Chameleon được thực hiện qua hai giai đoạn riêng biệt, chiếm lần lượt 80% và 20% tổng thời gian huấn luyện.
Giai đoạn đầu tiên của quá trình huấn luyện là để mô hình học một cách không giám sát từ các dữ liệu trên. Khi bắt đầu giai đoạn thứ hai, trọng số thu được từ giai đoạn đầu tiên sẽ được giảm xuống 50%, sau đó trộn với dữ liệu chất lượng cao hơn để mô hình tiếp tục học.
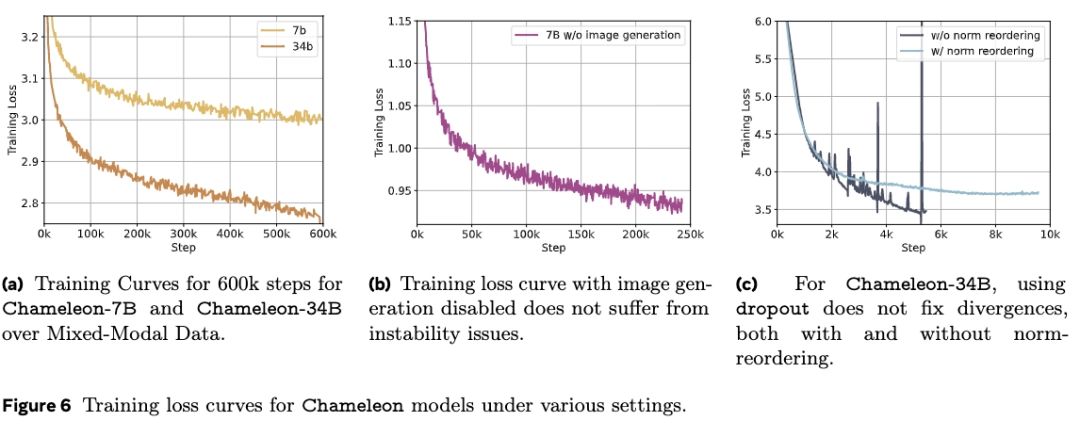
Khi mô hình mở rộng vượt quá 8 tỷ tham số và 1 nghìn tỷ token, sẽ có vấn đề về sự ổn định rõ rệt trong giai đoạn huấn luyện sau.
Do tất cả các phương thức đều chia sẻ trọng số của mô hình, mỗi phương thức dường như có xu hướng tăng norm, "cạnh tranh" với các phương thức khác.
Điều này không gây ra vấn đề lớn trong giai đoạn đầu của quá trình huấn luyện, nhưng khi quá trình huấn luyện tiến triển và dữ liệu vượt quá phạm vi biểu diễn của bf16, sẽ có hiện tượng loss phân tán.
Các nhà nghiên cứu phát hiện rằng hàm softmax có tính chất dịch chuyển bất biến, gây ra hiện tượng "logit drift" trong các mô hình đơn phương thức. Để khắc phục, họ đề xuất:
Ngoài nguồn dữ liệu và kiến trúc, bài báo còntiết lộ quy mô sức mạnh tính toán được sử dụng trong đào tạo trước.
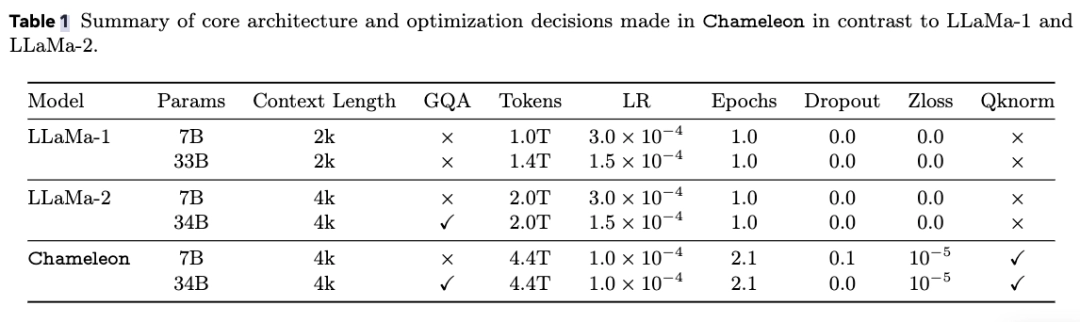
Model phần cứng là NVIDIA A100 với bộ nhớ 80GB. Phiên bản 7B sử dụng song song 1024 GPU để đào tạo trong khoảng 860.000 giờ GPU. Số lượng GPU được sử dụng bởi model 34B đã được mở rộng gấp 3 lần, với hơn 4,28 triệu giờ GPU.

Là một công ty từng phát hành mô hình nguồn mở Llama 2, nhóm nghiên cứu của Meta thực sự rất hào phóng. So với GPT-4o, chúng ta thậm chí còn không được tiếp cận các báo cáo kỹ thuật. Với trường hợp Chameleon, bài báo được chia sẻ với dữ liệu và thông tin thực tế này có thể được mô tả là “hào phóng nhất”.
Vượt xa Llama 2
Trong các phần đánh giá cụ thể của thử nghiệm, các nhà nghiên cứu chia thành đánh giá thủ công và kiểm tra an toàn, cùng với đánh giá chuẩn.
Đánh giá chuẩn
Khi sử dụng gấp bốn lần số lượng token so với Llama 2, Chameleon-34B đã đạt được kết quả ấn tượng trong các thử nghiệm chuẩn đơn mô phỏng.
Trong việc tạo ra văn bản thuần túy, các nhà nghiên cứu đã so sánh khả năng tạo ra văn bản thuần túy của mô hình được huấn luyện trước (không phải SFT) với các mô hình LLM văn bản hàng đầu khác.
Nội dung đánh giá bao gồm suy luận thông thường, hiểu đọc, vấn đề toán học và kiến thức thế giới, kết quả đánh giá được hiển thị trong bảng dưới đây.
- Suy luận thông thường và hiểu đọc
Có thể thấy rằng, so với Llama 2, Chameleon-7B và Chameleon-34B có sự cạnh tranh mạnh mẽ hơn. Thậm chí, 34B thậm chí còn vượt qua Llama-2 70B trong 5/8 nhiệm vụ, với hiệu suất tương đương với Mixtral-8x7B.
- Toán học và kiến thức thế giới
Mặc dù được huấn luyện trên các mô đun khác nhau, hai mô hình Chameleon đều có khả năng toán học mạnh mẽ.
Trên GSM8k, hiệu suất của Chameleon-7B vượt trội hơn so với mô hình Llama 2 có cùng số lượng tham số, với hiệu suất tương đương với Mistral-7B.
Ngoài ra, hiệu suất của Chameleon-34B trong maj@1 (61.4 so với 56.8) và Mixtral-8x7B trong maj@32 (77.0 so với 75.1) đều vượt trội hơn so với Llama 2-70B.
Tương tự, trong các phép tính toán, hiệu suất của Chameleon-7B vượt trội hơn Llama 2 và tương đương với hiệu suất của Mistral-7B trong maj@4, trong khi hiệu suất của Chameleon-34B vượt trội hơn Llama 2-70B và gần bằng hiệu suất của Mixtral-8x7B trong maj@4 (24.7 so với 28.4).
Hiệu suất của Chameleon vượt xa Llama 2, và trong một số nhiệm vụ, tiệm cận với Mistral-7B / 8x7B.
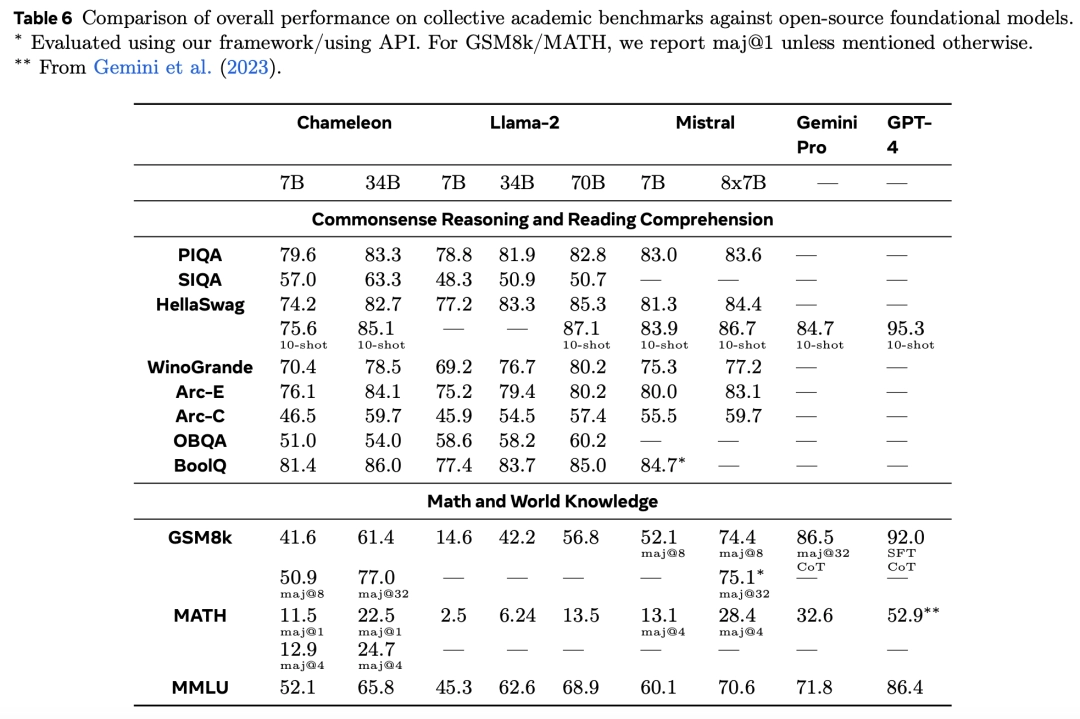
Trong nhiệm vụ từ văn bản đến hình ảnh, các nhà nghiên cứu đã đánh giá cụ thể hai nhiệm vụ cụ thể là câu hỏi về hình ảnh và chú thích hình ảnh.
Chameleon đã vượt qua Flamingo và Llava-1.5 và các mô hình khác để trở thành SOTA trong các nhiệm vụ câu hỏi về hình ảnh và chú thích hình ảnh, và cũng tương đương với các mô hình hàng đầu như Mixtral 8x7B và Gemini Pro trong các nhiệm vụ thuần văn bản.

Kiểm tra an toàn, đánh giá bởi con người.
Ngoài việc thử nghiệm các bài kiểm tra chuẩn, để đánh giá sâu hơn chất lượng của nội dung đa mô đa phương của mô hình, bài báo cũng đã giới thiệu thêm các thử nghiệm đánh giá bởi con người, và phát hiện ra rằng hiệu suất của Chameleon-34B vượt xa cả Gemini Pro và GPT-4V.
So với GPT-4V và Gemini Pro, những người phê bình con người lần lượt đưa ra tỷ lệ ưa thích là 51.6% và 60.4%.
Hình dưới đây thể hiện so sánh hiệu suất giữa Chameleon và các mô hình cơ sở trong việc hiểu và tạo ra nội dung, sử dụng một tập hợp đa dạng các gợi ý từ các nhà đánh giá con người.
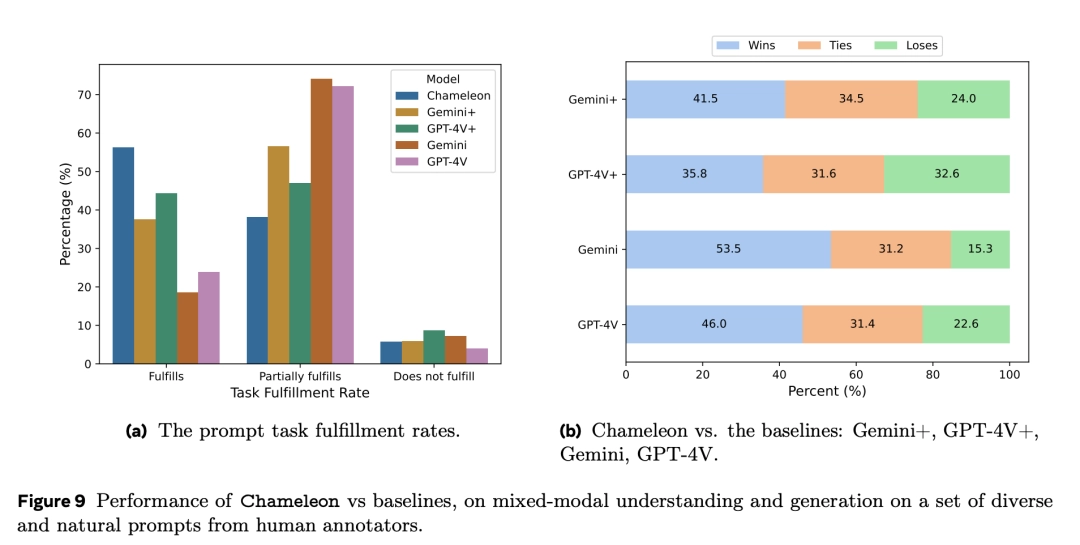
Câu hỏi được trả lời bởi ba nhà đánh giá con người khác nhau, và kết quả được tính dựa trên phiếu đa số như là câu trả lời cuối cùng.
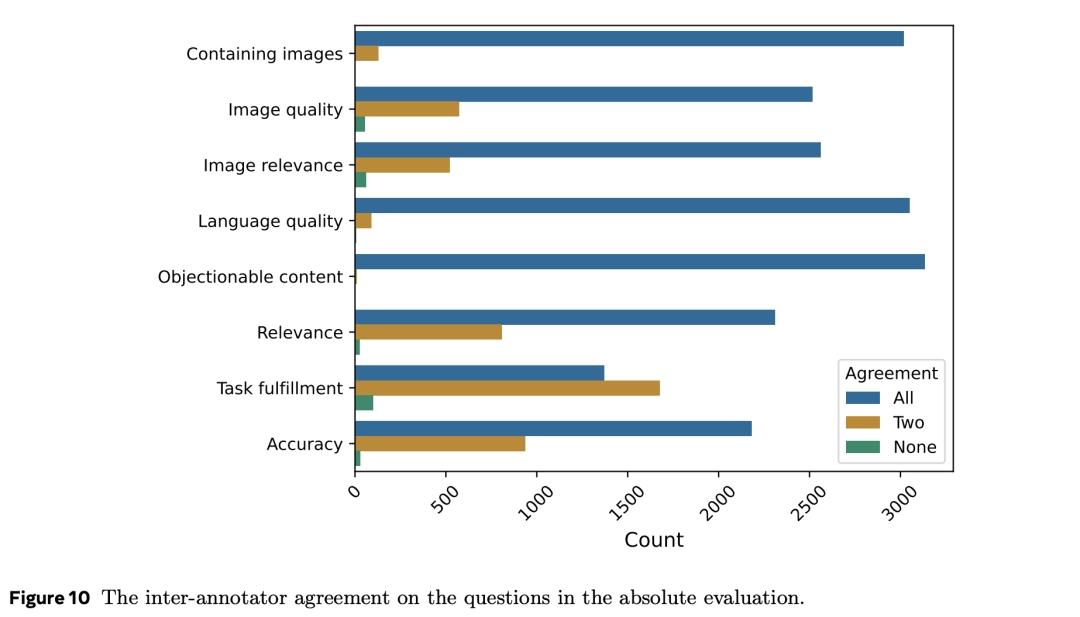
Để hiểu về chất lượng của các nhà đánh giá con người và xem xét việc thiết kế câu hỏi có hợp lý hay không, các nhà nghiên cứu cũng kiểm tra mức độ nhất quán giữa các nhà đánh giá khác nhau.

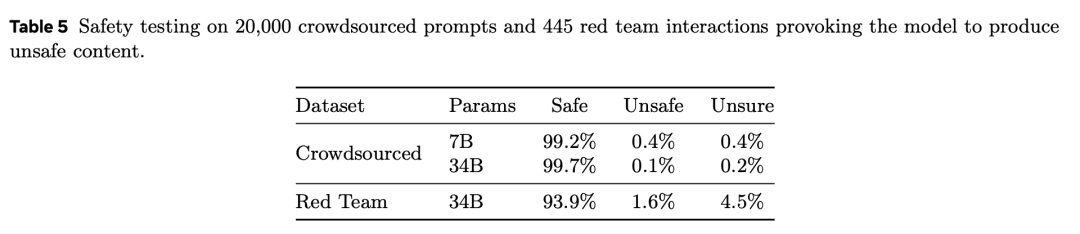
Bảng 5 là kết quả của các bài kiểm tra an toàn trên 20,000 gợi ý từ cộng đồng và 445 tương tác từ đội màu đỏ, gây ra nội dung không an toàn cho mô hình.
So với Gemini và GPT-4V, Chameleon rất cạnh tranh khi xử lý các gợi ý đòi hỏi phản ứng đa mô và hỗn hợp.
Từ các ví dụ có thể thấy, khi hoàn thành các nhiệm vụ trả lời câu hỏi, Chameleon không chỉ hiểu văn bản đầu vào + hình ảnh mà còn có thể đưa ra "hình ảnh đi kèm" phù hợp cho nội dung đầu ra của mô hình.


Hơn nữa, các hình ảnh được tạo ra bởi Chameleon thường liên quan đến ngữ cảnh, điều này khiến cho đầu ra chứa nội dung phản ứng đa mô này rất hấp dẫn đối với người dùng.

Mặc dù hiện vẫn chưa biết nhiều về kiến trúc cụ thể của GPT-4 omni (GPT-4o) vừa được OpenAI giới thiệu gần đây, nhưng có lẽ công ty đang theo đuổi một phương pháp tương tự. Tuy nhiên, khác với Chameleon, mô hình của OpenAI cũng trực tiếp tích hợp âm thanh, có lẽ lớn hơn đáng kể và được huấn luyện chung với nhiều dữ liệu hơn.
Một trong những tuyên bố ngụ ý rằng Chameleon chỉ đại diện cho giai đoạn đầu tiên của nỗ lực của Meta để tiến xa hơn trong việc hiểu biết về mô hình đa mô đa phương thế hệ tiếp theo: Mô hình đa mô đa phương "early-fusion".Mô hình đã được huấn luyện cách đây năm tháng và từ đó đến nay, nhóm phát triển đã đạt được tiến bộ đáng kể, có thể bao gồm việc tích hợp các dạng chế độ bổ sung. Giám đốc điều hành của Meta, Mark Zuckerberg, đã gợi ý về việc sử dụng mô hình đa mô đa phương trong tương lai.
Hiện tại Chameleon vẫn chưa được phát hành công khai.
Bạn đọc có thể tham khảo thêm thông tin nghiên cứu về Chameleon tại đây
Sự xuất hiện của GPT-4o một lần nữa đã tạo ra mô hình mới cho việc phát triển mô hình đa phương thức! OpenAI gọi nó là mô hình đa phương thức "bản địa" đầu tiên, có nghĩa là GPT-4o khác với tất cả các mô hình trước đó.
Các mô hình cơ bản đa phương thức truyền thống thường sử dụng một "bộ mã hóa" hoặc "bộ giải mã" cụ thể cho từng phương thức để phân tách các phương thức khác nhau.
Tuy nhiên, cách tiếp cận này hạn chế khả năng của mô hình trong việc kết hợp thông tin đa phương thức một cách hiệu quả.
GPT-4o là mô hình được đào tạo "từ đầu đến cuối" bao gồm văn bản, hình ảnh và âm thanh. Tất cả đầu vào và đầu ra đều được xử lý bởi một mạng thần kinh duy nhất.
Bằng việc các nhà nghiên cứu từ nhóm Meta đã phát hành “mô hình cơ sở phương thức hỗn hợp” – Chameleon, có thể đây là mẫu AI đầu tiên trong ngành có đủ khả năng cạnh tranh với ChatGPT-4o.
Trong bài báo được chia sẻ trên tạp chí khoa học arxiv.org
Giống như GPT-4o, Chameleon áp dụng kiến trúc Transformer thống nhất và sử dụng các phương thức kết hợp văn bản, hình ảnh và mã để hoàn thành quá trình đào tạo.
Theo cách tương tự như tạo văn bản, hình ảnh được "mã hóa" (mã thông báo) một cách riêng biệt và cuối cùng, một chuỗi văn bản và hình ảnh xen kẽ được tạo ra và lý giải.
Với phương pháp "kết hợp sớm" này, tất cả các quy trình đều được ánh xạ tới một không gian biểu diễn chung ngay từ đầu, do đó mô hình có thể xử lý văn bản và hình ảnh một cách liền mạch.
Chameleon tạo ra nội dung đa phương thức
Thiết kế này đã mang lại những thách thức kỹ thuật lớn cho việc huấn luyện mô hình. Để đối phó với điều này, nhóm nghiên cứu Meta đã giới thiệu một loạt các đổi mới về kiến trúc và kỹ thuật huấn luyện.
Kết quả cho thấy, trong các nhiệm vụ chỉ liên quan đến văn bản, Chameleon với 34 tỷ tham số (được huấn luyện trên 10 nghìn tỷ token đa phương thức) có hiệu suất tương đương với Gemini-Pro.
Trên các tiêu chuẩn về trả lời câu hỏi trực quan và gán nhãn hình ảnh, Chameleon thiết lập chuẩn mực mới về SOTA, với hiệu suất gần bằng GPT-4V.
Tuy nhiên, dù là GPT-4o hay Chameleon, cả hai đều là những mô hình nền tảng đa phương thức "nguyên bản" thế hệ mới đang trong giai đoạn khám phá ban đầu.
GPT-4o nguồn mở tiếp theo sắp ra mắt ?
Việc Meta phát hành Chameleon đơn giản là phản hồi nhanh nhất đối với GPT-4o. Một số người dùng internet cho rằng token đi vào và token đi ra, điều này đơn giản là không thể giải thích được.
Thậm chí còn có những tuyên bố rằng OOS sẽ bắt kịp sau nghiên cứu rất vững chắc được công bố sau sự ra đời của GPT-4o. Tuy nhiên, hiện tại mô hình Chameleon hỗ trợ các phương thức chủ yếu là văn bản hình ảnh. Thiếu khả năng giọng nói như GPT-4o.
Người ta cho rằng sau đó chỉ cần thêm một phương thức khác (âm thanh), mở rộng bộ dữ liệu huấn luyện, “xào nấu” một lúc là sẽ có GPT-4o…? Có lẽ sẽ không lâu nữa chúng ta sẽ có phiên bản nguồn mở của GPT-4o.
Chi tiết kỹ thuật của mô hình Chameleon. Kiến trúc công nghệ
Trong bài báo được chia sẻ trên tạp chí khoa học arxiv.org Meta chia sẻ đầu tiên về Chameleon cho rằng: Nhiều mô hình mới được phát hành gần đây vẫn chưa thực sự triển khai "đa phương thức" một cách triệt để.
Mặc dù các mô hình này sử dụng phương pháp huấn luyện đầu-cuối, nhưng vẫn thực hiện việc mô hình hóa các phương thức khác nhau một cách riêng lẻ, sử dụng các bộ mã hóa hoặc giải mã riêng biệt.
Như đã đề cập ở phần đầu, cách làm này hạn chế khả năng xử lý thông tin liên phương thức của mô hình và cũng khó tạo ra các tài liệu đa phương thức thực sự chứa bất kỳ dạng thông tin nào.
Để cải thiện nhược điểm này, Meta đã đề xuất một loạt các mô hình nền tảng "hỗn hợp phương thức" mang tên Chameleon — có khả năng tạo ra nội dung văn bản và hình ảnh được đan xen với nhau một cách tự do.
Kết quả của Chameleon là văn bản và hình ảnh có thể xuất hiện đan xen nhau. Mô hình nền tảng "hỗn hợp phương thức" của Chameleon không chỉ được huấn luyện từ đầu bằng phương pháp đầu-cuối mà còn kết hợp thông tin từ tất cả các phương thức trong quá trình huấn luyện và sử dụng một kiến trúc thống nhất để xử lý.
Để làm được điều này, tất cả thông tin được biểu diễn dưới dạng token, cho phép ánh xạ thông tin từ tất cả các phương thức vào cùng một không gian vector và Transformer có thể xử lý một cách liền mạch. Tuy nhiên, phương pháp này gặp các thách thức về ổn định tối ưu hóa và khả năng mở rộng của mô hình.
Để khắc phục, bài báo đã đưa ra các cải tiến về kiến trúc mô hình và sử dụng các kỹ thuật huấn luyện như QK chuẩn hóa và Zloss. Ngoài ra, bài báo cũng đề xuất phương pháp tinh chỉnh từ mô hình ngôn ngữ lớn thuần văn bản sang mô hình đa phương thức.
Hình ảnh "Mã thông báo"
Để thể hiện tất cả các phương thức dưới dạng mã thông báo, trước tiên cần có một mã thông báo mạnh mẽ.
Để đạt được mục tiêu này, nhóm của Chameleon đã phát triển một công cụ mã hóa hình ảnh mới dựa trên bài báo trước đó của Meta. Dựa trên sổ mã có kích thước 8192, hình ảnh có thông số kỹ thuật 512×512 được mã hóa thành 1024 mã thông báo riêng biệt.
Bộ phân tách văn bản sử dụng thư viện mã nguồn mở sentencepiece do Google phát triển. Bộ phân tách này đã được huấn luyện để chứa đồng thời 65536 token cho văn bản và 8192 token cho hình ảnh.
Tập huấn trước
Để phát huy hết tiềm năng của “các phương thức hỗn hợp”, dữ liệu huấn luyện cũng được chia nhỏ và trộn lẫn với các phương thức khác nhau để trình bày cho mô hình, bao gồm văn bản thuần túy, cặp văn bản-hình ảnh và tài liệu đa phương thức có văn bản và hình ảnh xen kẽ. .
Dữ liệu văn bản thuần túy bao gồm tất cả dữ liệu tiền huấn luyện mà Llama 2 và CodeLlama đã sử dụng, tổng cộng là 2,9 nghìn tỷ token.
Các cặp văn bản-hình ảnh bao gồm một số dữ liệu công khai, với tổng cộng 1,4 tỷ cặp và 1,5 nghìn tỷ token.
Đối với dữ liệu đan xen giữa văn bản và hình ảnh, bài báo đặc biệt nhấn mạnh không bao gồm dữ liệu từ các sản phẩm của Meta, mà hoàn toàn sử dụng các nguồn dữ liệu công khai, tổng hợp được 400 tỷ token.
Việc tiền huấn luyện của Chameleon được thực hiện qua hai giai đoạn riêng biệt, chiếm lần lượt 80% và 20% tổng thời gian huấn luyện.
Giai đoạn đầu tiên của quá trình huấn luyện là để mô hình học một cách không giám sát từ các dữ liệu trên. Khi bắt đầu giai đoạn thứ hai, trọng số thu được từ giai đoạn đầu tiên sẽ được giảm xuống 50%, sau đó trộn với dữ liệu chất lượng cao hơn để mô hình tiếp tục học.
Khi mô hình mở rộng vượt quá 8 tỷ tham số và 1 nghìn tỷ token, sẽ có vấn đề về sự ổn định rõ rệt trong giai đoạn huấn luyện sau.
Do tất cả các phương thức đều chia sẻ trọng số của mô hình, mỗi phương thức dường như có xu hướng tăng norm, "cạnh tranh" với các phương thức khác.
Điều này không gây ra vấn đề lớn trong giai đoạn đầu của quá trình huấn luyện, nhưng khi quá trình huấn luyện tiến triển và dữ liệu vượt quá phạm vi biểu diễn của bf16, sẽ có hiện tượng loss phân tán.
Các nhà nghiên cứu phát hiện rằng hàm softmax có tính chất dịch chuyển bất biến, gây ra hiện tượng "logit drift" trong các mô hình đơn phương thức. Để khắc phục, họ đề xuất:
- QK chuẩn hóa: Áp dụng chuẩn hóa layer cho các vector query và key trong module attention để kiểm soát sự tăng của norm trong đầu vào của softmax.
- Dropout: Thêm các lớp dropout sau các lớp attention và feedforward để giảm overfitting và tăng cường tính ổn định.
- Zloss: Sử dụng Zloss trong hàm mất mát để điều chỉnh và duy trì sự ổn định của mô hình trong quá trình huấn luyện.
Ngoài nguồn dữ liệu và kiến trúc, bài báo còntiết lộ quy mô sức mạnh tính toán được sử dụng trong đào tạo trước.
Model phần cứng là NVIDIA A100 với bộ nhớ 80GB. Phiên bản 7B sử dụng song song 1024 GPU để đào tạo trong khoảng 860.000 giờ GPU. Số lượng GPU được sử dụng bởi model 34B đã được mở rộng gấp 3 lần, với hơn 4,28 triệu giờ GPU.
Vượt xa Llama 2
Trong các phần đánh giá cụ thể của thử nghiệm, các nhà nghiên cứu chia thành đánh giá thủ công và kiểm tra an toàn, cùng với đánh giá chuẩn.
Đánh giá chuẩn
Khi sử dụng gấp bốn lần số lượng token so với Llama 2, Chameleon-34B đã đạt được kết quả ấn tượng trong các thử nghiệm chuẩn đơn mô phỏng.
Trong việc tạo ra văn bản thuần túy, các nhà nghiên cứu đã so sánh khả năng tạo ra văn bản thuần túy của mô hình được huấn luyện trước (không phải SFT) với các mô hình LLM văn bản hàng đầu khác.
Nội dung đánh giá bao gồm suy luận thông thường, hiểu đọc, vấn đề toán học và kiến thức thế giới, kết quả đánh giá được hiển thị trong bảng dưới đây.
- Suy luận thông thường và hiểu đọc
Có thể thấy rằng, so với Llama 2, Chameleon-7B và Chameleon-34B có sự cạnh tranh mạnh mẽ hơn. Thậm chí, 34B thậm chí còn vượt qua Llama-2 70B trong 5/8 nhiệm vụ, với hiệu suất tương đương với Mixtral-8x7B.
- Toán học và kiến thức thế giới
Mặc dù được huấn luyện trên các mô đun khác nhau, hai mô hình Chameleon đều có khả năng toán học mạnh mẽ.
Trên GSM8k, hiệu suất của Chameleon-7B vượt trội hơn so với mô hình Llama 2 có cùng số lượng tham số, với hiệu suất tương đương với Mistral-7B.
Ngoài ra, hiệu suất của Chameleon-34B trong maj@1 (61.4 so với 56.8) và Mixtral-8x7B trong maj@32 (77.0 so với 75.1) đều vượt trội hơn so với Llama 2-70B.
Tương tự, trong các phép tính toán, hiệu suất của Chameleon-7B vượt trội hơn Llama 2 và tương đương với hiệu suất của Mistral-7B trong maj@4, trong khi hiệu suất của Chameleon-34B vượt trội hơn Llama 2-70B và gần bằng hiệu suất của Mixtral-8x7B trong maj@4 (24.7 so với 28.4).
Hiệu suất của Chameleon vượt xa Llama 2, và trong một số nhiệm vụ, tiệm cận với Mistral-7B / 8x7B.
Trong nhiệm vụ từ văn bản đến hình ảnh, các nhà nghiên cứu đã đánh giá cụ thể hai nhiệm vụ cụ thể là câu hỏi về hình ảnh và chú thích hình ảnh.
Chameleon đã vượt qua Flamingo và Llava-1.5 và các mô hình khác để trở thành SOTA trong các nhiệm vụ câu hỏi về hình ảnh và chú thích hình ảnh, và cũng tương đương với các mô hình hàng đầu như Mixtral 8x7B và Gemini Pro trong các nhiệm vụ thuần văn bản.
Kiểm tra an toàn, đánh giá bởi con người.
Ngoài việc thử nghiệm các bài kiểm tra chuẩn, để đánh giá sâu hơn chất lượng của nội dung đa mô đa phương của mô hình, bài báo cũng đã giới thiệu thêm các thử nghiệm đánh giá bởi con người, và phát hiện ra rằng hiệu suất của Chameleon-34B vượt xa cả Gemini Pro và GPT-4V.
So với GPT-4V và Gemini Pro, những người phê bình con người lần lượt đưa ra tỷ lệ ưa thích là 51.6% và 60.4%.
Hình dưới đây thể hiện so sánh hiệu suất giữa Chameleon và các mô hình cơ sở trong việc hiểu và tạo ra nội dung, sử dụng một tập hợp đa dạng các gợi ý từ các nhà đánh giá con người.
Câu hỏi được trả lời bởi ba nhà đánh giá con người khác nhau, và kết quả được tính dựa trên phiếu đa số như là câu trả lời cuối cùng.
Để hiểu về chất lượng của các nhà đánh giá con người và xem xét việc thiết kế câu hỏi có hợp lý hay không, các nhà nghiên cứu cũng kiểm tra mức độ nhất quán giữa các nhà đánh giá khác nhau.
Bảng 5 là kết quả của các bài kiểm tra an toàn trên 20,000 gợi ý từ cộng đồng và 445 tương tác từ đội màu đỏ, gây ra nội dung không an toàn cho mô hình.
So với Gemini và GPT-4V, Chameleon rất cạnh tranh khi xử lý các gợi ý đòi hỏi phản ứng đa mô và hỗn hợp.
Từ các ví dụ có thể thấy, khi hoàn thành các nhiệm vụ trả lời câu hỏi, Chameleon không chỉ hiểu văn bản đầu vào + hình ảnh mà còn có thể đưa ra "hình ảnh đi kèm" phù hợp cho nội dung đầu ra của mô hình.
Mặc dù hiện vẫn chưa biết nhiều về kiến trúc cụ thể của GPT-4 omni (GPT-4o) vừa được OpenAI giới thiệu gần đây, nhưng có lẽ công ty đang theo đuổi một phương pháp tương tự. Tuy nhiên, khác với Chameleon, mô hình của OpenAI cũng trực tiếp tích hợp âm thanh, có lẽ lớn hơn đáng kể và được huấn luyện chung với nhiều dữ liệu hơn.
Một trong những tuyên bố ngụ ý rằng Chameleon chỉ đại diện cho giai đoạn đầu tiên của nỗ lực của Meta để tiến xa hơn trong việc hiểu biết về mô hình đa mô đa phương thế hệ tiếp theo: Mô hình đa mô đa phương "early-fusion".Mô hình đã được huấn luyện cách đây năm tháng và từ đó đến nay, nhóm phát triển đã đạt được tiến bộ đáng kể, có thể bao gồm việc tích hợp các dạng chế độ bổ sung. Giám đốc điều hành của Meta, Mark Zuckerberg, đã gợi ý về việc sử dụng mô hình đa mô đa phương trong tương lai.
Hiện tại Chameleon vẫn chưa được phát hành công khai.
Bạn đọc có thể tham khảo thêm thông tin nghiên cứu về Chameleon tại đây
