Hugging Face ra mắt mô hình AI thị giác-ngôn ngữ nhỏ nhất: 256 triệu tham số, chạy được trên máy tính cấu hình yếu
Vn-Z.vn Ngày 24 tháng 01 năm 2025, Hugging Face đăng bài viết thông báo ra mắt hai mô hình AI nhẹ SmolVLM-256M-Instruct và SmolVLM-500M-Instruct. Đây là những mô hình được tối ưu hóa để hoạt động hiệu quả trên các thiết bị có khả năng xử lý AI hạn chế.

Trước đó, vào tháng 11/2024, Hugging Face từng giới thiệu mô hình AI thị giác-ngôn ngữ (VLM) SmolVLM với 2 tỷ tham số, được thiết kế để chạy trực tiếp trên thiết bị với bộ nhớ cực thấp, nổi bật trong số các mô hình cùng loại.
Lần này, SmolVLM-256M-Instruct chỉ có 256 triệu tham số, trở thành mô hình thị giác-ngôn ngữ nhỏ nhất từng được công bố. Mô hình này có thể hoạt động trên PC với bộ nhớ RAM dưới 1GB mà vẫn mang lại hiệu suất vượt trội.
SmolVLM-500M-Instruct, với 500 triệu tham số, được tối ưu cho các thiết bị hạn chế về tài nguyên phần cứng. Nó hỗ trợ các nhà phát triển xử lý dữ liệu quy mô lớn, mở ra những bước tiến mới về hiệu suất AI và khả năng tiếp cận.
Các mô hình SmolVLM tích hợp khả năng đa phương thức tiên tiến, có thể thực hiện các nhiệm vụ như mô tả hình ảnh, phân tích video ngắn, trả lời câu hỏi về tài liệu PDF hoặc biểu đồ khoa học. Hugging Face khẳng định: “SmolVLM xây dựng cơ sở dữ liệu có khả năng tìm kiếm nhanh hơn và chi phí thấp hơn, với tốc độ tương đương các mô hình lớn gấp 10 lần so với nó.”
Quá trình phát triển các mô hình này dựa trên hai tập dữ liệu chuyên biệt: The Cauldron và Docmatix.
• The Cauldron là tập hợp gồm 50 tập dữ liệu hình ảnh và văn bản chất lượng cao, tập trung vào việc học đa phương thức.
• Docmatix được thiết kế riêng cho việc hiểu tài liệu, ghép nối các tệp quét với tiêu đề chi tiết nhằm tăng cường khả năng hiểu.
Các mô hình SmolVLM sử dụng bộ mã hóa hình ảnh nhỏ hơn, SigLIP base patch-16/512, thay vì bộ mã hóa lớn hơn SigLIP 400M SO trong SmolVLM 2B. Việc tối ưu hóa cách xử lý các thẻ hình ảnh đã giảm bớt sự dư thừa và cải thiện khả năng xử lý dữ liệu phức tạp.
Mô hình SmolVLM hiện có khả năng mã hóa hình ảnh với tốc độ 4096 pixel trên mỗi thẻ, cải tiến đáng kể so với 1820 pixel trên mỗi thẻ ở phiên bản trước.
Ngay bây giờ bạn có thể thử phiên bản Web phiên bản SmolVLM-256M-Instruct hoặc SmolVLM-500M-Instruct . Xem mã nguồn của mô hình tại đây https://github.com/huggingface/transformers.js-examples/tree/main/smolvlm-webgpu

Trước đó, vào tháng 11/2024, Hugging Face từng giới thiệu mô hình AI thị giác-ngôn ngữ (VLM) SmolVLM với 2 tỷ tham số, được thiết kế để chạy trực tiếp trên thiết bị với bộ nhớ cực thấp, nổi bật trong số các mô hình cùng loại.
Lần này, SmolVLM-256M-Instruct chỉ có 256 triệu tham số, trở thành mô hình thị giác-ngôn ngữ nhỏ nhất từng được công bố. Mô hình này có thể hoạt động trên PC với bộ nhớ RAM dưới 1GB mà vẫn mang lại hiệu suất vượt trội.
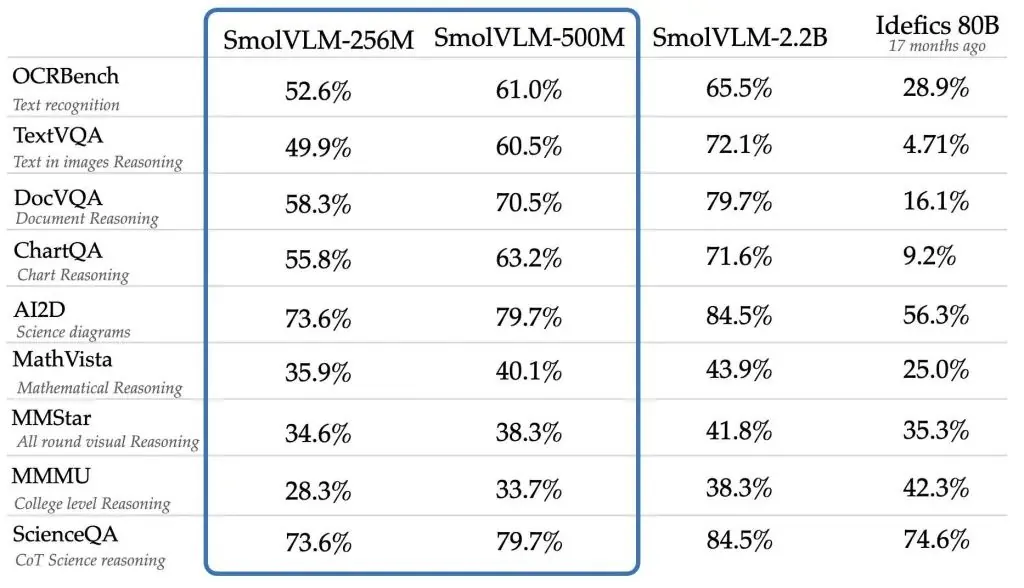
Các mô hình SmolVLM tích hợp khả năng đa phương thức tiên tiến, có thể thực hiện các nhiệm vụ như mô tả hình ảnh, phân tích video ngắn, trả lời câu hỏi về tài liệu PDF hoặc biểu đồ khoa học. Hugging Face khẳng định: “SmolVLM xây dựng cơ sở dữ liệu có khả năng tìm kiếm nhanh hơn và chi phí thấp hơn, với tốc độ tương đương các mô hình lớn gấp 10 lần so với nó.”
Quá trình phát triển các mô hình này dựa trên hai tập dữ liệu chuyên biệt: The Cauldron và Docmatix.
• The Cauldron là tập hợp gồm 50 tập dữ liệu hình ảnh và văn bản chất lượng cao, tập trung vào việc học đa phương thức.
• Docmatix được thiết kế riêng cho việc hiểu tài liệu, ghép nối các tệp quét với tiêu đề chi tiết nhằm tăng cường khả năng hiểu.
Các mô hình SmolVLM sử dụng bộ mã hóa hình ảnh nhỏ hơn, SigLIP base patch-16/512, thay vì bộ mã hóa lớn hơn SigLIP 400M SO trong SmolVLM 2B. Việc tối ưu hóa cách xử lý các thẻ hình ảnh đã giảm bớt sự dư thừa và cải thiện khả năng xử lý dữ liệu phức tạp.
Mô hình SmolVLM hiện có khả năng mã hóa hình ảnh với tốc độ 4096 pixel trên mỗi thẻ, cải tiến đáng kể so với 1820 pixel trên mỗi thẻ ở phiên bản trước.
Ngay bây giờ bạn có thể thử phiên bản Web phiên bản SmolVLM-256M-Instruct hoặc SmolVLM-500M-Instruct . Xem mã nguồn của mô hình tại đây https://github.com/huggingface/transformers.js-examples/tree/main/smolvlm-webgpu
BÀI MỚI ĐANG THẢO LUẬN