GPT-4.5 có khả năng sáng tạo yếu hơn GPT-4o, Trung Quốc ra mắt bộ tiêu chuẩn Creation-MMBench, đánh giá khả năng sáng tạo của các mô hình đa mô thức
Gần đây, GPT-4.5 đang gây chú ý không chỉ nhờ khả năng duy trì ngữ cảnh mạch lạc trong các tương tác hàng ngày mà còn tỏa sáng trong những nhiệm vụ đòi hỏi tính sáng tạo cao như thiết kế, tư vấn...
Khi GPT-4.5 thể hiện khả năng sáng tạo và logic đáng kinh ngạc trong các tác vụ như viết truyện ngắn dựa trên hình ảnh, tư vấn giáo dục hay đề xuất thiết kế, một câu hỏi quan trọng được đặt ra:
"Giới hạn sáng tạo của các mô hình đa phương thức (MLLMs) nằm ở đâu?"
Viết một câu chuyện ngắn từ hình ảnh, phân tích slide giảng dạy phức tạp, hay thiết kế giao diện người dùng...
Những nhiệm vụ này với con người có thể dễ dàng, nhưng đối với nhiều mô hình đa phương thức hiện nay lại là thách thức lớn.
Tuy nhiên, các tiêu chuẩn đánh giá hiện tại khó đo lường được liệu đầu ra của MLLMs có thực sự mang tính sáng tạo hay không. Đồng thời, một số kịch bản đánh giá quá đơn giản, không phản ánh chân thực khả năng tư duy sáng tạo của mô hình trong các tình huống phức tạp.
Làm thế nào để định lượng "khả năng sáng tạo đa phương thức" một cách khoa học?
Để giải quyết vấn đề này, nhóm nghiên cứu từ Đại học Zhejiang ( Chiết Giang) phối hợp với Phòng thí nghiệm AI Thượng Hải và các đơn vị khác đã cho ra mắt Creation-MMBench –
Tiêu chuẩn đánh giá đa phương thức đầu tiên trên thế giới tập trung vào khả năng sáng tạo trong bối cảnh thực tế, bao gồm 4 nhóm nhiệm vụ chính và 51 tác vụ chi tiết, sử dụng 765 test case độ khó cao để kiểm tra toàn diện "trí thông minh sáng tạo thị giác" của các MLLMs.
Các tiêu chuẩn đánh giá MLLM hiện nay như MMBench, MMMU… thường tập trung vào các nhiệm vụ phân tích hoặc thực dụng, nhưng lại bỏ qua những tác vụ sáng tạo mà AI đa phương thức thường gặp trong đời sống thực tế.
Việc thiếu vắng một hệ thống đo lường khả năng sáng tạo đa phương thức khiến chúng ta khó hiểu rõ:

Ngược lại, Creation-MMBench được thiết kế với:
✅ Tình huống phức tạp – mô phỏng các tình huống thực tế đa dạng
✅ Đa dạng nội dung – kết hợp câu hỏi hình ảnh đơn & hình ảnh liên hoàn
✅ Độ khó cao – đòi hỏi mô hình phải thể hiện tư duy sáng tạo thực sự
✍️ "Đóng vai nhà văn, viết một bài tùy bút giàu cảm xúc và cốt truyện từ bức ảnh chân dung."
👨🍳 "Tưởng tượng bạn là bếp trưởng Michelin, giải thích chi tiết cách chế biến món ăn từ ảnh chụp cho người mới học nấu ăn."
Những nhiệm vụ này yêu cầu mô hình đồng thời sở hữu:
🔹 Khả năng hiểu nội dung hình ảnh sâu
🔹 Tư duy thích ứng ngữ cảnh linh hoạt
🔹 Kỹ năng tạo văn bản vừa logic vừa độc đáo
Đây chính là năng lực cốt lõi mà các benchmark truyền thống chưa thể đánh giá toàn diện. Creation-MMBench không chỉ kiểm tra "AI có thể làm gì", mà quan trọng hơn là "AI có thể sáng tạo đến đâu" – yếu tố quyết định tính ứng dụng thực tế của các mô hình đa phương thức.

Bốn loại nhiệm vụ chính: Creation-MMBench bao gồm 51 nhiệm vụ, chủ yếu được chia thành bốn loại sau:

Hình ảnh đa lĩnh vực với quy mô lớn: Về mặt hình ảnh, Creation-MMBench bao phủ gần 30 thể loại khác nhau từ tác phẩm nghệ thuật, bản thiết kế cho đến cảnh sinh hoạt đời thường, với tổng cộng khoảng một nghìn hình ảnh. Mỗi nhiệm vụ có thể tiếp nhận tối đa 9 hình ảnh đầu vào, tái hiện chân thực môi trường sáng tạo trong thực tế.

Bối cảnh thực tế phức tạp: Mỗi trường hợp mẫu đều được chú thích dựa trên hình ảnh thực tế, bao gồm bốn thành phần: vai trò xác định, bối cảnh cụ thể, hướng dẫn nhiệm vụ và yêu cầu bổ sung. Đồng thời, so với các tiêu chuẩn đánh giá đa phương thức phổ biến khác, Creation-MMBench sở hữu thiết kế vấn đề toàn diện và phức tạp hơn, với đa số câu hỏi có độ dài vượt quá 500 token, giúp mô hình nắm bắt ngữ cảnh sáng tạo phong phú hơn.
Trong chiến lược đánh giá, nhóm nghiên cứu đã lựa chọn sử dụng mô hình đa phương thức lớn làm mô hình đánh giá, đồng thời áp dụng hai chỉ số khác nhau để thực hiện đánh giá kép.
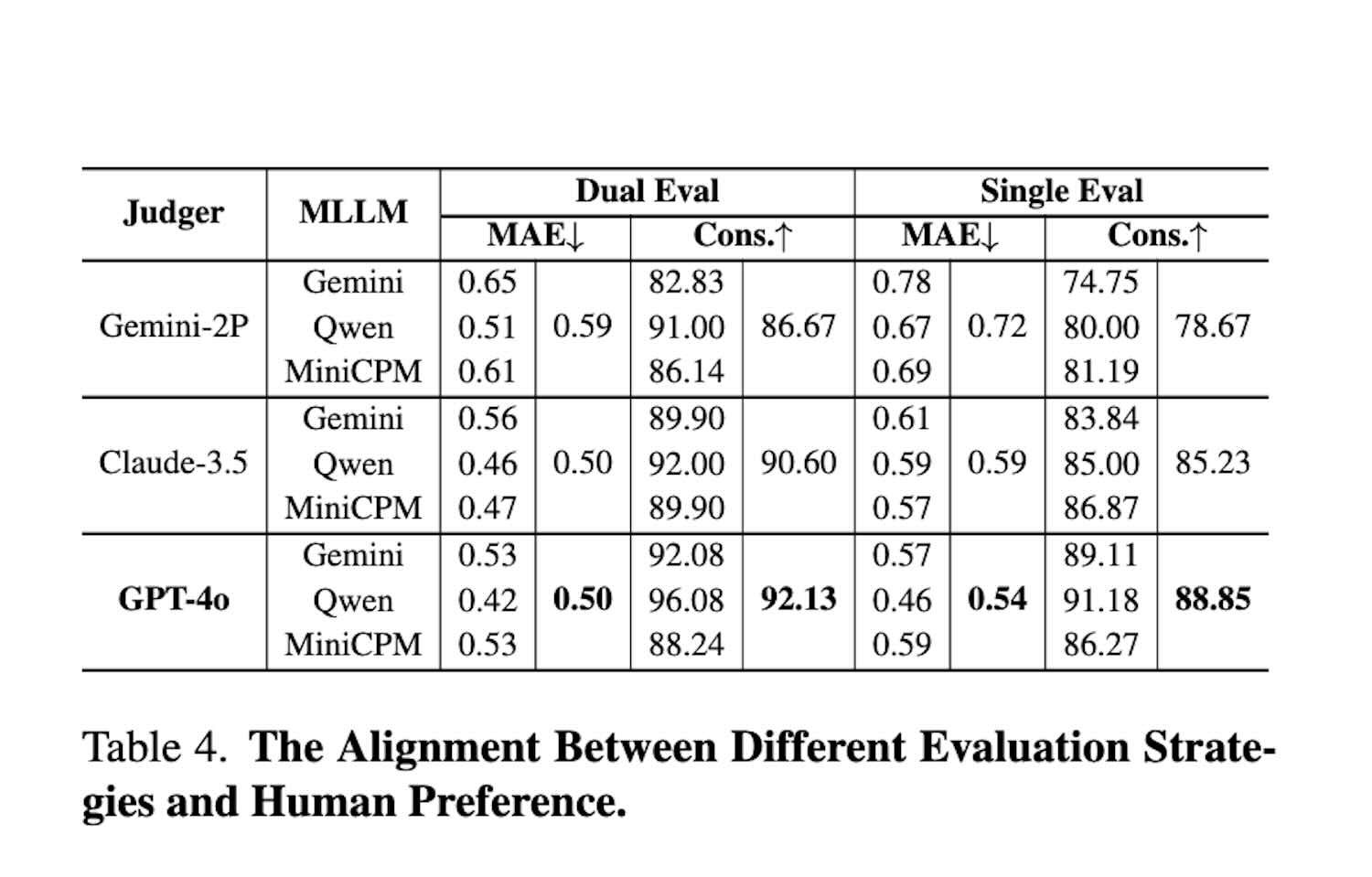
Để kiểm chứng độ tin cậy của mô hình đánh giá và chiến lược đánh giá được áp dụng, nhóm đã tuyển dụng tình nguyện viên để tiến hành đánh giá thủ công trên 13% mẫu. Kết quả được thể hiện ở hình trên. So với các mô hình đánh giá khác, GPT-4o cho thấy tính nhất quán cao hơn với sở thích của con người và cũng chứng minh tính cần thiết của đánh giá hai chiều.
Kết quả thí nghiệm: Để xác định mô hình nào thực sự dẫn đầu về khả năng sáng tạo, nhóm nghiên cứu đã sử dụng bộ công cụ VLMEvalKit để đánh giá toàn diện hơn 20 MLLM phổ biến, bao gồm cả các mô hình đóng như GPT-4o, series Gemini, Claude 3.5 và các mô hình nguồn mở như Qwen2.5-VL, InternVL.

Kết quả tổng quan:

Để so sánh tốt hơn giữa hiệu suất khách quan của các mô hình và khả năng sáng tạo thị giác của chúng, nhóm nghiên cứu đã sử dụng điểm trung bình từ bảng xếp hạng đánh giá đa mô thức OpenCompass để biểu thị hiệu suất khách quan tổng thể.
Như hình trên cho thấy, một số mô hình dù có hiệu suất khách quan rất mạnh, nhưng lại thể hiện kém trong các nhiệm vụ sáng tạo thị giác mở. Những mô hình này thường hoạt động tốt trong các tác vụ có đáp án rõ ràng, nhưng lại thiếu khả năng tạo ra nội dung mang tính sáng tạo và phù hợp với ngữ cảnh. Sự khác biệt này cho thấy các chỉ số khách quan truyền thống có thể không phản ánh đầy đủ khả năng sáng tạo của mô hình trong những tình huống thực tế phức tạp, từ đó càng chứng minh tầm quan trọng của bộ đánh giá Creation-MMBench trong việc lấp đầy khoảng trống này.
Hiện nay, các bộ tiêu chuẩn đánh giá khả năng sáng tạo của mô hình ngôn ngữ lớn (LLM) chủ yếu tập trung vào các chủ đề cụ thể (chẳng hạn như sinh ý tưởng nghiên cứu khoa học), tương đối đơn điệu và chưa thể phản ánh đầy đủ năng lực sáng tạo của LLM trong nhiều bối cảnh đời sống hàng ngày khác nhau.
Chính vì vậy, nhóm nghiên cứu đã sử dụng GPT-4o để mô tả chi tiết nội dung hình ảnh, từ đó xây dựng phiên bản hoàn toàn bằng văn bản mang tên Creation-MMBench-TO (Text-Only).

Từ kết quả đánh giá các mô hình ngôn ngữ thuần túy, có thể thấy rằng các mô hình LLM đóng (closed-source) có năng lực sáng tạo nhỉnh hơn một chút so với các mô hình LLM mã nguồn mở. Điều đáng ngạc nhiên là GPT-4o đạt điểm thưởng sáng tạo cao hơn trong bộ đánh giá Creation-MMBench-TO.
Nguyên nhân có thể là do GPT-4o có thể tập trung hơn vào tư duy phân kỳ và sáng tạo tự do nhờ sự hỗ trợ từ phần mô tả hình ảnh, từ đó giảm bớt ảnh hưởng tiêu cực của việc hiểu nội dung thị giác cơ bản đến khả năng sáng tạo.
Đồng thời, để điều tra sâu hơn tác động của việc tinh chỉnh theo hướng dẫn thị giác (visual instruction tuning) đối với các LLM, nhóm nghiên cứu đã tiến hành các thí nghiệm so sánh. Kết quả cho thấy, các mô hình đa mô thức mã nguồn mở sau khi được tinh chỉnh bằng hướng dẫn thị giác lại có hiệu suất thấp hơn so với mô hình ngôn ngữ nền tương ứng trên bộ đánh giá Creation-MMBench-TO.
Nguyên nhân có thể là do các cặp hỏi – đáp được sử dụng trong quá trình tinh chỉnh có độ dài tương đối ngắn, khiến mô hình gặp khó khăn trong việc hiểu nội dung chi tiết của văn bản dài. Điều này khiến mô hình khó nhập vai vào ngữ cảnh để sáng tạo các đoạn văn dài, từ đó dẫn đến điểm số thấp hơn ở cả hai hạng mục: độ chính xác thị giác và điểm thưởng sáng tạo.

Nhóm nghiên cứu cũng đã tiến hành nghiên cứu định tính đối với một số mô hình, như thể hiện trong hình trên. Loại nhiệm vụ trong ví dụ là giải thích hình ảnh kỹ thuật phần mềm, thuộc nhóm viết chuyên sâu mang tính chức năng.
Kết quả cho thấy Qwen2.5-VL, do thiếu hiểu biết về kiến thức chuyên ngành, đã nhầm lẫn sơ đồ bể bơi (swimlane diagram) với sơ đồ luồng dữ liệu (data flow diagram), dẫn đến việc phân tích biểu đồ sau đó bị sai lệch.
Ngược lại, GPT-4o đã tránh được lỗi này, sử dụng ngôn ngữ chuyên nghiệp và cấu trúc chặt chẽ hơn, đồng thời đưa ra phân tích chính xác và chi tiết hơn về biểu đồ, từ đó được mô hình đánh giá ưu tiên lựa chọn.
Trường hợp này phản ánh tầm quan trọng của kiến thức chuyên ngành và khả năng hiểu nội dung hình ảnh một cách chi tiết trong loại nhiệm vụ này, đồng thời cho thấy khoảng cách vẫn tồn tại giữa các mô hình mã nguồn mở và mã nguồn đóng.
Creation-MMBench là một bộ đánh giá mới mẻ, được thiết kế để đánh giá khả năng sáng tạo của các mô hình đa mô thức trong bối cảnh thực tế. Bộ đánh giá này bao gồm 765 ví dụ, bao phủ 51 nhiệm vụ chi tiết.
Đối với mỗi ví dụ, nhóm nghiên cứu đã xây dựng tiêu chí đánh giá tương ứng để đo lường chất lượng phản hồi và tính đúng đắn về mặt thị giác của mô hình.
Ngoài ra, nhóm đã tạo ra một phiên bản chỉ sử dụng văn bản - Creation-MMBench-TO bằng cách thay thế hình ảnh đầu vào bằng mô tả chi tiết bằng văn bản. Các thí nghiệm trên cả hai phiên bản đã giúp đánh giá toàn diện khả năng sáng tạo của các mô hình đa mô thức hiện nay, đồng thời làm rõ những ảnh hưởng tiêu cực tiềm ẩn của việc tinh chỉnh bằng hướng dẫn thị giác.
Hiện tại, Creation-MMBench đã được tích hợp vào VLMEvalKit, hỗ trợ chấm điểm chỉ với một cú nhấp chuột, cho phép bạn đánh giá toàn diện khả năng sáng tạo của mô hình trên các tác vụ sáng tạo.
Kết quả nghiên cứu hiện đã được đăng tải trên các tạp chí khoa học, các bạn có thể tham khảo thêm thông tin tại đây
 arxiv.org
arxiv.org

 github.com
github.com
Khi GPT-4.5 thể hiện khả năng sáng tạo và logic đáng kinh ngạc trong các tác vụ như viết truyện ngắn dựa trên hình ảnh, tư vấn giáo dục hay đề xuất thiết kế, một câu hỏi quan trọng được đặt ra:
"Giới hạn sáng tạo của các mô hình đa phương thức (MLLMs) nằm ở đâu?"
Viết một câu chuyện ngắn từ hình ảnh, phân tích slide giảng dạy phức tạp, hay thiết kế giao diện người dùng...
Những nhiệm vụ này với con người có thể dễ dàng, nhưng đối với nhiều mô hình đa phương thức hiện nay lại là thách thức lớn.
Tuy nhiên, các tiêu chuẩn đánh giá hiện tại khó đo lường được liệu đầu ra của MLLMs có thực sự mang tính sáng tạo hay không. Đồng thời, một số kịch bản đánh giá quá đơn giản, không phản ánh chân thực khả năng tư duy sáng tạo của mô hình trong các tình huống phức tạp.
Làm thế nào để định lượng "khả năng sáng tạo đa phương thức" một cách khoa học?
Để giải quyết vấn đề này, nhóm nghiên cứu từ Đại học Zhejiang ( Chiết Giang) phối hợp với Phòng thí nghiệm AI Thượng Hải và các đơn vị khác đã cho ra mắt Creation-MMBench –
Tiêu chuẩn đánh giá đa phương thức đầu tiên trên thế giới tập trung vào khả năng sáng tạo trong bối cảnh thực tế, bao gồm 4 nhóm nhiệm vụ chính và 51 tác vụ chi tiết, sử dụng 765 test case độ khó cao để kiểm tra toàn diện "trí thông minh sáng tạo thị giác" của các MLLMs.
Tại sao chúng ta cần quan tâm đến "trí thông minh sáng tạo thị giác"?
Theo "Thuyết trí tuệ tam nguyên" (Triarchic Theory of Intelligence) trong trí tuệ nhân tạo, trí thông minh sáng tạo (Creative Intelligence) luôn là yếu tố khó đánh giá và chinh phục nhất, đòi hỏi khả năng tạo ra những giải pháp mới mẻ và phù hợp trong các bối cảnh khác nhau.Các tiêu chuẩn đánh giá MLLM hiện nay như MMBench, MMMU… thường tập trung vào các nhiệm vụ phân tích hoặc thực dụng, nhưng lại bỏ qua những tác vụ sáng tạo mà AI đa phương thức thường gặp trong đời sống thực tế.
Việc thiếu vắng một hệ thống đo lường khả năng sáng tạo đa phương thức khiến chúng ta khó hiểu rõ:
- Liệu AI có thể thực sự hiểu và tạo ra nội dung độc đáo, thay vì chỉ tổng hợp thông tin có sẵn?
- Mô hình có thể thích ứng linh hoạt với các yêu cầu mở, phức tạp như con người?
Tại sao Creation-MMBench vượt trội so với các tiêu chuẩn đánh giá hiện có?
Một số benchmark đa phương thức hiện nay cũng đã đề cập đến khả năng sáng tạo của mô hình, nhưng chúng thường có quy mô nhỏ, chỉ sử dụng hình ảnh đơn lẻ và bối cảnh đơn giản, khiến ngay cả những mô hình thông thường cũng có thể dễ dàng vượt qua.Ngược lại, Creation-MMBench được thiết kế với:
✅ Tình huống phức tạp – mô phỏng các tình huống thực tế đa dạng
✅ Đa dạng nội dung – kết hợp câu hỏi hình ảnh đơn & hình ảnh liên hoàn
✅ Độ khó cao – đòi hỏi mô hình phải thể hiện tư duy sáng tạo thực sự
Ví dụ minh họa:
🎤 "Hãy đóng vai hướng dẫn viên bảo tàng, dựa trên hình ảnh hiện vật để soạn một bài thuyết minh hấp dẫn."✍️ "Đóng vai nhà văn, viết một bài tùy bút giàu cảm xúc và cốt truyện từ bức ảnh chân dung."
👨🍳 "Tưởng tượng bạn là bếp trưởng Michelin, giải thích chi tiết cách chế biến món ăn từ ảnh chụp cho người mới học nấu ăn."
Những nhiệm vụ này yêu cầu mô hình đồng thời sở hữu:
🔹 Khả năng hiểu nội dung hình ảnh sâu
🔹 Tư duy thích ứng ngữ cảnh linh hoạt
🔹 Kỹ năng tạo văn bản vừa logic vừa độc đáo
Đây chính là năng lực cốt lõi mà các benchmark truyền thống chưa thể đánh giá toàn diện. Creation-MMBench không chỉ kiểm tra "AI có thể làm gì", mà quan trọng hơn là "AI có thể sáng tạo đến đâu" – yếu tố quyết định tính ứng dụng thực tế của các mô hình đa phương thức.
Creation-MMBench "cứng" cỡ nào?
1. Kịch bản thực tế × Đa phương thức: Từ "đánh trận giấy" tới "chiến trường thật"
Bốn loại nhiệm vụ chính: Creation-MMBench bao gồm 51 nhiệm vụ, chủ yếu được chia thành bốn loại sau:
- Sáng tác văn học: Tập trung vào các hoạt động sáng tác trong lĩnh vực văn học, bao gồm thơ, đối thoại, truyện và các hình thức viết khác. Loại này nhằm đánh giá khả năng biểu đạt nghệ thuật và sáng tạo của mô hình, chẳng hạn như tạo ra văn bản giàu cảm xúc, xây dựng câu chuyện hấp dẫn hoặc hình tượng nhân vật sống động. Các nhiệm vụ điển hình bao gồm viết tiếp truyện, sáng tác thơ, v.v.
- Viết chức năng hàng ngày: Tập trung vào các nhiệm vụ viết chức năng phổ biến trong đời sống hàng ngày, chẳng hạn như viết nội dung mạng xã hội, đề xuất sáng kiến cộng đồng, v.v. Loại này nhấn mạnh tính thực tiễn, kiểm tra khả năng của mô hình trong việc xử lý các yêu cầu viết phổ biến trong bối cảnh thực tế, chẳng hạn như viết email, trả lời các vấn đề thực tế trong cuộc sống, v.v.
- Viết chức năng chuyên nghiệp: Tập trung vào khả năng viết chức năng và giải quyết vấn đề sáng tạo trong các lĩnh vực chuyên môn. Các nhiệm vụ cụ thể bao gồm thiết kế nội thất, soạn giáo án, viết lời dẫn du lịch phong cảnh, v.v. Loại này yêu cầu mô hình có nền tảng kiến thức chuyên môn mạnh và khả năng suy luận logic để đáp ứng các tình huống công việc phức tạp và chuyên sâu.
- Hiểu và sáng tạo đa phương thức: Tập trung vào sự kết hợp giữa hiểu biết thị giác và sáng tạo, bao gồm các nhiệm vụ như phân tích tài liệu, thưởng thức tác phẩm nhiếp ảnh, v.v. Loại này đánh giá khả năng của mô hình trong việc xử lý thông tin đa phương thức (kết hợp văn bản và hình ảnh), kiểm tra xem nó có thể trích xuất thông tin quan trọng từ nội dung trực quan và chuyển đổi thành đầu ra sáng tạo có ý nghĩa hay không.
Bối cảnh thực tế phức tạp: Mỗi trường hợp mẫu đều được chú thích dựa trên hình ảnh thực tế, bao gồm bốn thành phần: vai trò xác định, bối cảnh cụ thể, hướng dẫn nhiệm vụ và yêu cầu bổ sung. Đồng thời, so với các tiêu chuẩn đánh giá đa phương thức phổ biến khác, Creation-MMBench sở hữu thiết kế vấn đề toàn diện và phức tạp hơn, với đa số câu hỏi có độ dài vượt quá 500 token, giúp mô hình nắm bắt ngữ cảnh sáng tạo phong phú hơn.
2. Hệ thống đánh giá kép: Loại bỏ "chủ quan suy đoán", định lượng chất lượng sáng tạo
Trong chiến lược đánh giá, nhóm nghiên cứu đã lựa chọn sử dụng mô hình đa phương thức lớn làm mô hình đánh giá, đồng thời áp dụng hai chỉ số khác nhau để thực hiện đánh giá kép.
1. Điểm số thực tế thị giác (VFS): Đảm bảo mô hình không "bịa đặt" - phải hiểu rõ chi tiết hình ảnh.
- Đối với một số trường hợp mẫu, cần đánh giá khả năng hiểu biết cơ bản của mô hình về hình ảnh trước tiên, để tránh việc sáng tạo bừa bãi nhằm đạt điểm cao.
- Nhóm nghiên cứu đã xây dựng tiêu chuẩn thực tế thị giác riêng cho từng trường hợp, kiểm tra nghiêm ngặt các chi tiết quan trọng trong hình ảnh và chấm điểm theo từng tiêu chí.
2. Điểm thưởng sáng tạo (Reward): Không chỉ hiểu hình ảnh, mà còn phải viết hay, viết khéo!
- Bên cạnh khả năng hiểu biết cơ bản, Creation-MMBench chú trọng đánh giá khả năng sáng tạo và diễn đạt của mô hình khi kết hợp với nội dung thị giác.
- Do mỗi trường hợp có vai trò, bối cảnh, hướng dẫn nhiệm vụ và yêu cầu bổ sung khác nhau, nhóm nghiên cứu đã xây dựng tiêu chuẩn đánh giá phù hợp cho từng trường hợp, xem xét nhiều khía cạnh từ độ trôi chảy trong diễn đạt, tính logic mạch lạc đến tính mới lạ trong sáng tạo.
- GPT-4o được sử dụng làm mô hình đánh giá, kết hợp đầy đủ giữa tiêu chuẩn đánh giá, nội dung hình ảnh và phản hồi của mô hình.
- Quy trình đánh giá hai chiều (hoán đổi vị trí của hai mô hình trong quá trình đánh giá để tránh sai lệch) được áp dụng để xác định sự ưu tiên tương đối giữa phản hồi của mô hình và đáp án tham khảo (không phải đáp án chuẩn).
Để kiểm chứng độ tin cậy của mô hình đánh giá và chiến lược đánh giá được áp dụng, nhóm đã tuyển dụng tình nguyện viên để tiến hành đánh giá thủ công trên 13% mẫu. Kết quả được thể hiện ở hình trên. So với các mô hình đánh giá khác, GPT-4o cho thấy tính nhất quán cao hơn với sở thích của con người và cũng chứng minh tính cần thiết của đánh giá hai chiều.
Kết quả thí nghiệm: Để xác định mô hình nào thực sự dẫn đầu về khả năng sáng tạo, nhóm nghiên cứu đã sử dụng bộ công cụ VLMEvalKit để đánh giá toàn diện hơn 20 MLLM phổ biến, bao gồm cả các mô hình đóng như GPT-4o, series Gemini, Claude 3.5 và các mô hình nguồn mở như Qwen2.5-VL, InternVL.
Kết quả tổng quan:
- So sánh giữa các mô hình đóng:
- Gemini-2.0-Pro thể hiện khả năng viết sáng tạo đa phương thức vượt trội hơn GPT-4o, đặc biệt trong các nhiệm vụ như viết chức năng hàng ngày, có thể tích hợp hình ảnh để tạo nội dung phù hợp với đời sống thực tế.
- Kiến thức nền tảng mạnh mẽ của Gemini giúp nó thể hiện tốt trong lĩnh vực viết chức năng chuyên nghiệp, tuy nhiên vẫn còn khoảng cách đáng kể so với GPT-4o trong việc hiểu các chi tiết thị giác phức tạp.
- Bất ngờ về GPT-4.5:
- Mặc dù được quảng cáo tập trung vào sáng tạo, GPT-4.5 có hiệu suất tổng thể thấp hơn cả Gemini-pro và GPT-4o.
- Tuy nhiên, mô hình này lại thể hiện khả năng vượt trội trong các nhiệm vụ hiểu và sáng tạo nội dung đa phương thức.
- Mô hình nguồn mở:
- Các mô hình như Qwen2.5-VL-72B và InternVL2.5-78B-MPO cho thấy khả năng sáng tạo có thể so sánh với các mô hình đóng.
- Tuy nhiên, vẫn tồn tại khoảng cách nhất định so với các mô hình đóng về tổng thể.
- Phân tích theo loại nhiệm vụ:
- Viết chức năng chuyên nghiệp: Độ khó cao do yêu cầu kiến thức chuyên môn và khả năng hiểu nội dung thị giác sâu.
- Viết chức năng hàng ngày: Dễ dàng hơn do bối cảnh gần gũi với đời sống, ngay cả các mô hình có hiệu suất tổng thể thấp cũng thể hiện tốt.
- Hiểu và sáng tạo đa phương thức: Dù đạt điểm VFS cao, các mô hình vẫn gặp hạn chế trong việc tái sáng tạo nội dung dựa trên hình ảnh.
Để so sánh tốt hơn giữa hiệu suất khách quan của các mô hình và khả năng sáng tạo thị giác của chúng, nhóm nghiên cứu đã sử dụng điểm trung bình từ bảng xếp hạng đánh giá đa mô thức OpenCompass để biểu thị hiệu suất khách quan tổng thể.
Như hình trên cho thấy, một số mô hình dù có hiệu suất khách quan rất mạnh, nhưng lại thể hiện kém trong các nhiệm vụ sáng tạo thị giác mở. Những mô hình này thường hoạt động tốt trong các tác vụ có đáp án rõ ràng, nhưng lại thiếu khả năng tạo ra nội dung mang tính sáng tạo và phù hợp với ngữ cảnh. Sự khác biệt này cho thấy các chỉ số khách quan truyền thống có thể không phản ánh đầy đủ khả năng sáng tạo của mô hình trong những tình huống thực tế phức tạp, từ đó càng chứng minh tầm quan trọng của bộ đánh giá Creation-MMBench trong việc lấp đầy khoảng trống này.
Khám phá sâu hơn: Việc tinh chỉnh mô hình thị giác là con dao hai lưỡi
Hiện nay, các bộ tiêu chuẩn đánh giá khả năng sáng tạo của mô hình ngôn ngữ lớn (LLM) chủ yếu tập trung vào các chủ đề cụ thể (chẳng hạn như sinh ý tưởng nghiên cứu khoa học), tương đối đơn điệu và chưa thể phản ánh đầy đủ năng lực sáng tạo của LLM trong nhiều bối cảnh đời sống hàng ngày khác nhau.
Chính vì vậy, nhóm nghiên cứu đã sử dụng GPT-4o để mô tả chi tiết nội dung hình ảnh, từ đó xây dựng phiên bản hoàn toàn bằng văn bản mang tên Creation-MMBench-TO (Text-Only).
Từ kết quả đánh giá các mô hình ngôn ngữ thuần túy, có thể thấy rằng các mô hình LLM đóng (closed-source) có năng lực sáng tạo nhỉnh hơn một chút so với các mô hình LLM mã nguồn mở. Điều đáng ngạc nhiên là GPT-4o đạt điểm thưởng sáng tạo cao hơn trong bộ đánh giá Creation-MMBench-TO.
Nguyên nhân có thể là do GPT-4o có thể tập trung hơn vào tư duy phân kỳ và sáng tạo tự do nhờ sự hỗ trợ từ phần mô tả hình ảnh, từ đó giảm bớt ảnh hưởng tiêu cực của việc hiểu nội dung thị giác cơ bản đến khả năng sáng tạo.
Đồng thời, để điều tra sâu hơn tác động của việc tinh chỉnh theo hướng dẫn thị giác (visual instruction tuning) đối với các LLM, nhóm nghiên cứu đã tiến hành các thí nghiệm so sánh. Kết quả cho thấy, các mô hình đa mô thức mã nguồn mở sau khi được tinh chỉnh bằng hướng dẫn thị giác lại có hiệu suất thấp hơn so với mô hình ngôn ngữ nền tương ứng trên bộ đánh giá Creation-MMBench-TO.
Nguyên nhân có thể là do các cặp hỏi – đáp được sử dụng trong quá trình tinh chỉnh có độ dài tương đối ngắn, khiến mô hình gặp khó khăn trong việc hiểu nội dung chi tiết của văn bản dài. Điều này khiến mô hình khó nhập vai vào ngữ cảnh để sáng tạo các đoạn văn dài, từ đó dẫn đến điểm số thấp hơn ở cả hai hạng mục: độ chính xác thị giác và điểm thưởng sáng tạo.
Nhóm nghiên cứu cũng đã tiến hành nghiên cứu định tính đối với một số mô hình, như thể hiện trong hình trên. Loại nhiệm vụ trong ví dụ là giải thích hình ảnh kỹ thuật phần mềm, thuộc nhóm viết chuyên sâu mang tính chức năng.
Kết quả cho thấy Qwen2.5-VL, do thiếu hiểu biết về kiến thức chuyên ngành, đã nhầm lẫn sơ đồ bể bơi (swimlane diagram) với sơ đồ luồng dữ liệu (data flow diagram), dẫn đến việc phân tích biểu đồ sau đó bị sai lệch.
Ngược lại, GPT-4o đã tránh được lỗi này, sử dụng ngôn ngữ chuyên nghiệp và cấu trúc chặt chẽ hơn, đồng thời đưa ra phân tích chính xác và chi tiết hơn về biểu đồ, từ đó được mô hình đánh giá ưu tiên lựa chọn.
Trường hợp này phản ánh tầm quan trọng của kiến thức chuyên ngành và khả năng hiểu nội dung hình ảnh một cách chi tiết trong loại nhiệm vụ này, đồng thời cho thấy khoảng cách vẫn tồn tại giữa các mô hình mã nguồn mở và mã nguồn đóng.
Creation-MMBench là một bộ đánh giá mới mẻ, được thiết kế để đánh giá khả năng sáng tạo của các mô hình đa mô thức trong bối cảnh thực tế. Bộ đánh giá này bao gồm 765 ví dụ, bao phủ 51 nhiệm vụ chi tiết.
Đối với mỗi ví dụ, nhóm nghiên cứu đã xây dựng tiêu chí đánh giá tương ứng để đo lường chất lượng phản hồi và tính đúng đắn về mặt thị giác của mô hình.
Ngoài ra, nhóm đã tạo ra một phiên bản chỉ sử dụng văn bản - Creation-MMBench-TO bằng cách thay thế hình ảnh đầu vào bằng mô tả chi tiết bằng văn bản. Các thí nghiệm trên cả hai phiên bản đã giúp đánh giá toàn diện khả năng sáng tạo của các mô hình đa mô thức hiện nay, đồng thời làm rõ những ảnh hưởng tiêu cực tiềm ẩn của việc tinh chỉnh bằng hướng dẫn thị giác.
Hiện tại, Creation-MMBench đã được tích hợp vào VLMEvalKit, hỗ trợ chấm điểm chỉ với một cú nhấp chuột, cho phép bạn đánh giá toàn diện khả năng sáng tạo của mô hình trên các tác vụ sáng tạo.
Kết quả nghiên cứu hiện đã được đăng tải trên các tạp chí khoa học, các bạn có thể tham khảo thêm thông tin tại đây
Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLM
Creativity is a fundamental aspect of intelligence, involving the ability to generate novel and appropriate solutions across diverse contexts. While Large Language Models (LLMs) have been extensively evaluated for their creative capabilities, the assessment of Multimodal Large Language Models...
GitHub - open-compass/Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLMs
Assessing Context-Aware Creative Intelligence in MLLMs - open-compass/Creation-MMBench
github.com
Creation-MMBench
Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLMs
open-compass.github.io
BÀI MỚI ĐANG THẢO LUẬN
