Google ra mắt mô hình mã nguồn mở Gemma 4, bản 31B đạt hiệu năng hàng đầu
Hôm nay, Google chính thức giới thiệu mô hình lớn Gemma 4, được cho là mô hình mã nguồn mở thông minh nhất của hãng từ trước đến nay. Gemma 4 được thiết kế chuyên cho suy luận nâng cao và các quy trình làm việc của tác nhân AI (agent), đạt được mức “trí tuệ trên mỗi tham số” chưa từng có.

Trong lần ra mắt này, Google cung cấp 4 phiên bản Gemma 4 gồm: bản hiệu quả 2 tỷ tham số (E2B), bản hiệu quả 4 tỷ tham số (E4B), mô hình hỗn hợp chuyên gia 26 tỷ tham số (MoE) và mô hình dense 31 tỷ tham số. Toàn bộ các phiên bản đều vượt xa các kịch bản hội thoại đơn giản, có thể xử lý logic phức tạp và các workflow tác nhân AI.
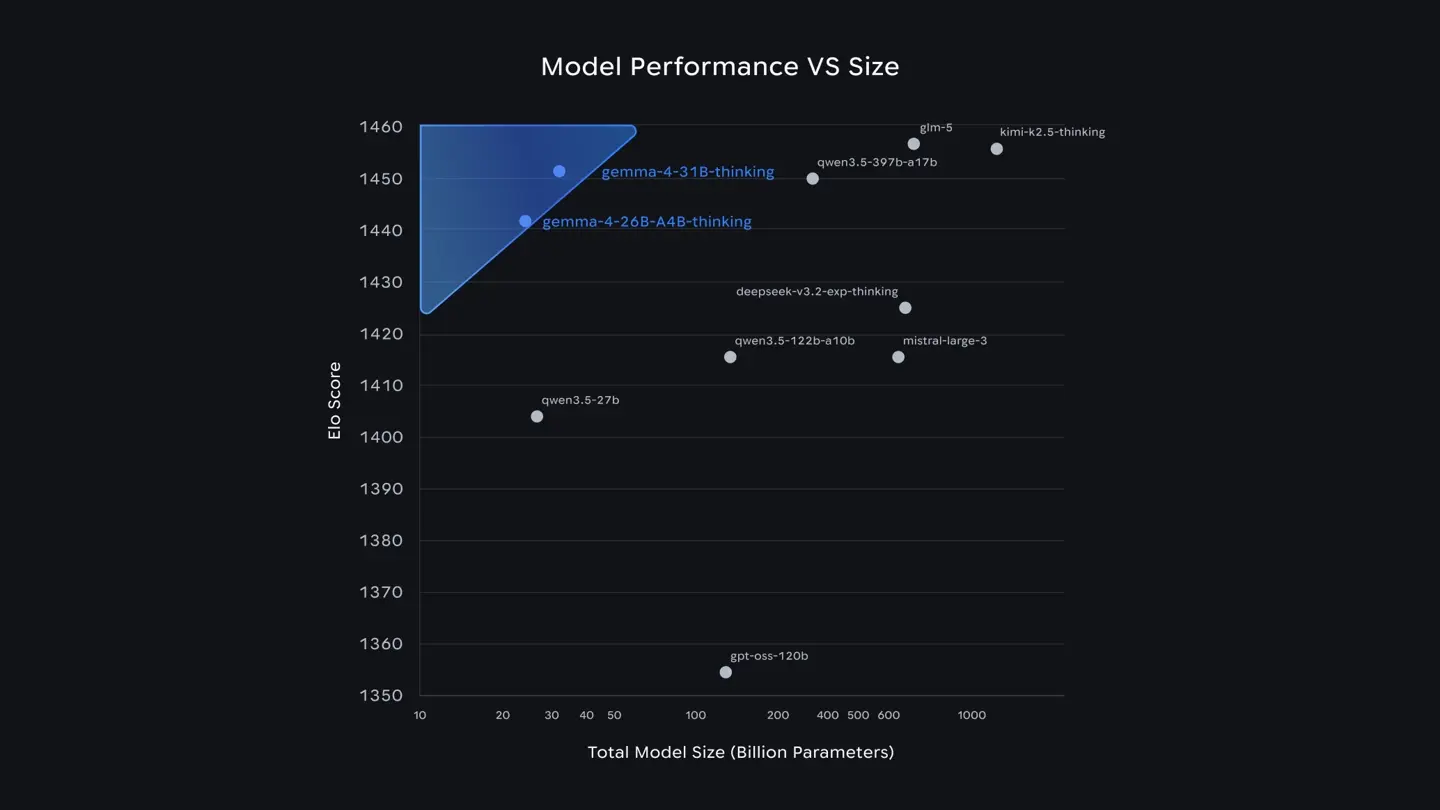
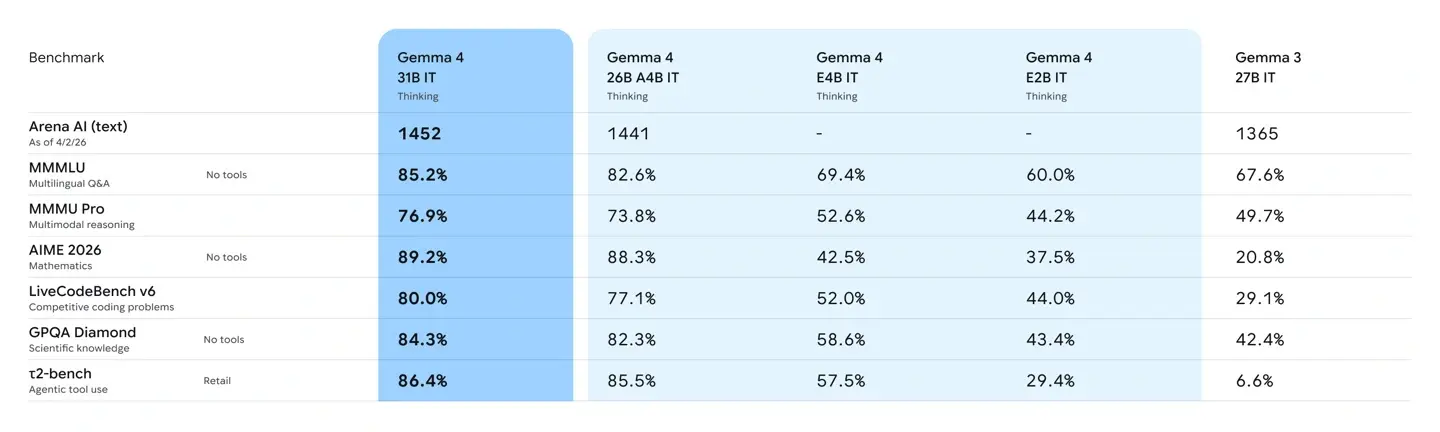
Trong đó, các mô hình tham số lớn đạt hiệu năng hàng đầu trong cùng phân khúc. Cụ thể, bản 31B hiện đứng thứ ba trong bảng xếp hạng văn bản Arena AI dành cho mô hình mã nguồn mở toàn cầu, còn bản 26B đứng thứ sáu. Đáng chú ý, hiệu năng của Gemma 4 thậm chí vượt qua những mô hình có quy mô lớn hơn tới 20 lần. Đối với nhà phát triển, điều này đồng nghĩa với việc chỉ cần ít phần cứng hơn nhưng vẫn có thể đạt được năng lực AI tiên tiến.
Ở phía thiết bị đầu cuối, các mô hình E2B và E4B mang lại giá trị mới cho việc triển khai cục bộ. Thay vì chỉ tăng số lượng tham số, chúng tập trung vào khả năng đa phương tiện, độ trễ thấp và tích hợp hệ sinh thái mượt mà.
Gemma 4 sở hữu nhiều ưu điểm nổi bật. Về khả năng suy luận, mô hình có thể thực hiện lập kế hoạch nhiều bước và xử lý logic sâu, cải thiện rõ rệt trong các bài kiểm tra toán học và thực thi chỉ lệnh. Về tác nhân AI, mô hình hỗ trợ sẵn việc gọi hàm, xuất dữ liệu JSON có cấu trúc và sử dụng chỉ thị hệ thống, cho phép xây dựng các tác nhân có thể kết nối công cụ, API và thực thi quy trình một cách đáng tin cậy.
Trong lĩnh vực lập trình, Gemma 4 hỗ trợ sinh mã chất lượng cao ngay cả khi chạy offline, biến máy trạm thành trợ lý lập trình AI cục bộ. Về đa phương tiện, toàn bộ dòng model hỗ trợ xử lý hình ảnh và video, tương thích với nhiều độ phân giải và thể hiện tốt trong các tác vụ như OCR hay phân tích biểu đồ. Riêng các bản E2B và E4B còn hỗ trợ đầu vào âm thanh, cho phép nhận diện và hiểu giọng nói.
Ngoài ra, Gemma 4 hỗ trợ ngữ cảnh dài, với cửa sổ context lên tới 128K cho các model nhỏ và tối đa 256K cho model lớn, giúp xử lý trơn tru các tài liệu dài hoặc toàn bộ codebase trong một lần nhập. Mô hình cũng được huấn luyện trên hơn 140 ngôn ngữ, hỗ trợ các nhà phát triển xây dựng ứng dụng phục vụ người dùng toàn cầu.
Đối với các phiên bản 26B và 31B, Google đã tối ưu để đạt hiệu năng suy luận cao trên phần cứng phổ thông. Các trọng số bfloat16 chưa lượng tử hóa có thể chạy hiệu quả trên một GPU NVIDIA H100 80GB, trong khi các phiên bản lượng tử hóa có thể triển khai trên GPU tiêu dùng, phục vụ môi trường phát triển tích hợp, trợ lý lập trình và workflow tác nhân AI. Mô hình 26B MoE tập trung vào độ trễ thấp, khi chỉ kích hoạt khoảng 3,8 tỷ tham số trong quá trình suy luận để tăng tốc độ sinh token. Trong khi đó, mô hình 31B dense tối đa hóa hiệu năng gốc và phù hợp cho việc tinh chỉnh (fine-tune).
Với các phiên bản E2B và E4B, Google tập trung tối ưu hiệu quả tính toán và bộ nhớ ngay từ thiết kế, giúp giảm tiêu thụ tài nguyên và điện năng. Hãng cũng hợp tác với Qualcomm, MediaTek cùng đội ngũ Pixel để đưa các mô hình đa phương tiện này chạy hoàn toàn offline với độ trễ gần như bằng 0 trên điện thoại, Raspberry Pi và các thiết bị như Jetson Orin Nano. Các nhà phát triển Android hiện có thể sử dụng AICore bản preview để xây dựng workflow tác nhân, đồng thời đảm bảo khả năng tương thích với Gemini Nano 4 trong tương lai.
Tham khảo thêm tại

Hôm nay, Google chính thức giới thiệu mô hình lớn Gemma 4, được cho là mô hình mã nguồn mở thông minh nhất của hãng từ trước đến nay. Gemma 4 được thiết kế chuyên cho suy luận nâng cao và các quy trình làm việc của tác nhân AI (agent), đạt được mức “trí tuệ trên mỗi tham số” chưa từng có.

Trong đó, các mô hình tham số lớn đạt hiệu năng hàng đầu trong cùng phân khúc. Cụ thể, bản 31B hiện đứng thứ ba trong bảng xếp hạng văn bản Arena AI dành cho mô hình mã nguồn mở toàn cầu, còn bản 26B đứng thứ sáu. Đáng chú ý, hiệu năng của Gemma 4 thậm chí vượt qua những mô hình có quy mô lớn hơn tới 20 lần. Đối với nhà phát triển, điều này đồng nghĩa với việc chỉ cần ít phần cứng hơn nhưng vẫn có thể đạt được năng lực AI tiên tiến.
Gemma 4 sở hữu nhiều ưu điểm nổi bật. Về khả năng suy luận, mô hình có thể thực hiện lập kế hoạch nhiều bước và xử lý logic sâu, cải thiện rõ rệt trong các bài kiểm tra toán học và thực thi chỉ lệnh. Về tác nhân AI, mô hình hỗ trợ sẵn việc gọi hàm, xuất dữ liệu JSON có cấu trúc và sử dụng chỉ thị hệ thống, cho phép xây dựng các tác nhân có thể kết nối công cụ, API và thực thi quy trình một cách đáng tin cậy.
Trong lĩnh vực lập trình, Gemma 4 hỗ trợ sinh mã chất lượng cao ngay cả khi chạy offline, biến máy trạm thành trợ lý lập trình AI cục bộ. Về đa phương tiện, toàn bộ dòng model hỗ trợ xử lý hình ảnh và video, tương thích với nhiều độ phân giải và thể hiện tốt trong các tác vụ như OCR hay phân tích biểu đồ. Riêng các bản E2B và E4B còn hỗ trợ đầu vào âm thanh, cho phép nhận diện và hiểu giọng nói.
Ngoài ra, Gemma 4 hỗ trợ ngữ cảnh dài, với cửa sổ context lên tới 128K cho các model nhỏ và tối đa 256K cho model lớn, giúp xử lý trơn tru các tài liệu dài hoặc toàn bộ codebase trong một lần nhập. Mô hình cũng được huấn luyện trên hơn 140 ngôn ngữ, hỗ trợ các nhà phát triển xây dựng ứng dụng phục vụ người dùng toàn cầu.
Đối với các phiên bản 26B và 31B, Google đã tối ưu để đạt hiệu năng suy luận cao trên phần cứng phổ thông. Các trọng số bfloat16 chưa lượng tử hóa có thể chạy hiệu quả trên một GPU NVIDIA H100 80GB, trong khi các phiên bản lượng tử hóa có thể triển khai trên GPU tiêu dùng, phục vụ môi trường phát triển tích hợp, trợ lý lập trình và workflow tác nhân AI. Mô hình 26B MoE tập trung vào độ trễ thấp, khi chỉ kích hoạt khoảng 3,8 tỷ tham số trong quá trình suy luận để tăng tốc độ sinh token. Trong khi đó, mô hình 31B dense tối đa hóa hiệu năng gốc và phù hợp cho việc tinh chỉnh (fine-tune).
Với các phiên bản E2B và E4B, Google tập trung tối ưu hiệu quả tính toán và bộ nhớ ngay từ thiết kế, giúp giảm tiêu thụ tài nguyên và điện năng. Hãng cũng hợp tác với Qualcomm, MediaTek cùng đội ngũ Pixel để đưa các mô hình đa phương tiện này chạy hoàn toàn offline với độ trễ gần như bằng 0 trên điện thoại, Raspberry Pi và các thiết bị như Jetson Orin Nano. Các nhà phát triển Android hiện có thể sử dụng AICore bản preview để xây dựng workflow tác nhân, đồng thời đảm bảo khả năng tương thích với Gemini Nano 4 trong tương lai.
Tham khảo thêm tại
BÀI MỚI ĐANG THẢO LUẬN