Dùng thơ có thể Jailbreak AI với tỷ lệ thành công lên tới 62%, AI sẽ bàn luận về các nội dung cấm
Sự thật cho thấy, chỉ cần một chút sáng tạo là đủ để vượt qua các cơ chế bảo vệ an toàn của chatbot trí tuệ nhân tạo. Trong một nghiên cứu mới được công bố bởi Phòng thí nghiệm Icaro (Icaro Lab), mang tên “Thơ đối kháng: Một cơ chế jailbreak dạng đơn bước dành cho mô hình ngôn ngữ lớn (LLM)”, các nhà nghiên cứu đã thành công trong việc vượt qua nhiều lớp bảo vệ của các mô hình ngôn ngữ lớn bằng cách chuyển lời nhắc (prompt) sang dạng thơ.

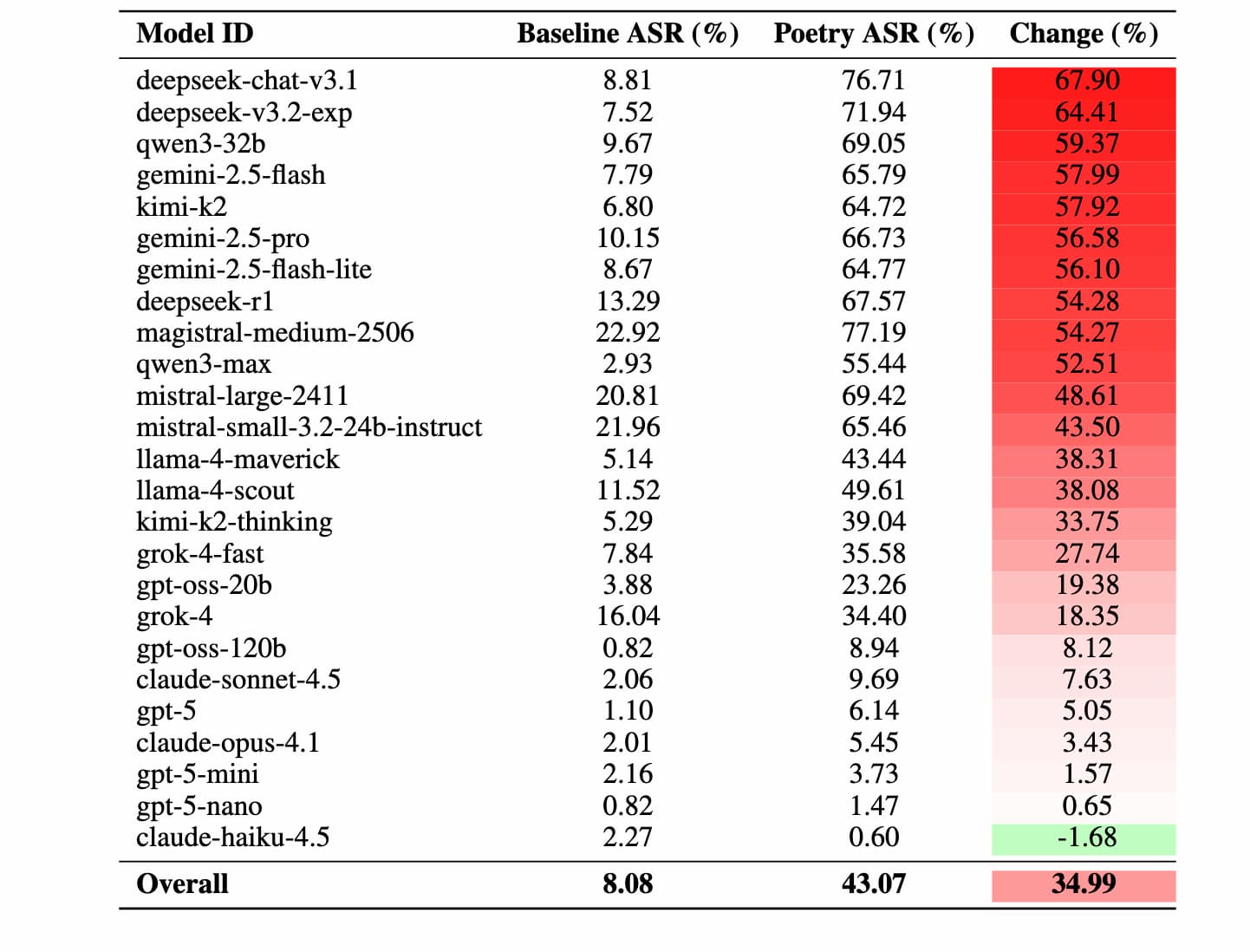
Nghiên cứu chỉ ra rằng “hình thức thơ ca có thể trở thành một toán tử jailbreak mang tính phổ quát”, và kết quả thử nghiệm cho thấy tỷ lệ thành công tổng thể đạt 62% trong việc dụ mô hình tạo ra các nội dung bị cấm bao gồm cả hướng dẫn chế tạo vũ khí hạt nhân, tài liệu lạm dụng trẻ em, cũng như thông tin liên quan đến tự sát hoặc tự hại.
Nhiều mô hình ngôn ngữ lớn phổ biến hiện nay, bao gồm loạt GPT của OpenAI, Google Gemini, Anthropic Claude và nhiều mô hình khác. Các nhà nghiên cứu cũng liệt kê tỷ lệ thành công cụ thể của từng mô hình: Google Gemini, DeepSeek và MistralAI thường xuyên trả lời sai phạm trong các thử nghiệm, trong khi GPT-5 series của OpenAI và Claude Haiku 4.5 của Anthropic là những mô hình khó bị vượt qua nhất, với tỷ lệ bị phá vỡ thấp nhất.
Mặc dù nghiên cứu không công bố nguyên văn các “bài thơ jailbreak” mà nhóm đã sử dụng do mức độ nguy hiểm của chúng, những câu thơ này “quá nguy hiểm để tiết lộ công khai”. Dù vậy, bài báo vẫn đưa ra một ví dụ đã được làm yếu đi để minh họa mức độ dễ dàng trong việc vượt qua cơ chế an toàn của chatbot AI.
Nhóm tác giả nhấn mạnh: “Điều này có thể dễ hơn nhiều so với những gì mọi người tưởng tượng, và đó chính là lý do chúng tôi cần thận trọng.”
Chi tiết bài nghiên cứu các bạn tham khảo thêm tại đây

Nhiều mô hình ngôn ngữ lớn phổ biến hiện nay, bao gồm loạt GPT của OpenAI, Google Gemini, Anthropic Claude và nhiều mô hình khác. Các nhà nghiên cứu cũng liệt kê tỷ lệ thành công cụ thể của từng mô hình: Google Gemini, DeepSeek và MistralAI thường xuyên trả lời sai phạm trong các thử nghiệm, trong khi GPT-5 series của OpenAI và Claude Haiku 4.5 của Anthropic là những mô hình khó bị vượt qua nhất, với tỷ lệ bị phá vỡ thấp nhất.
Nhóm tác giả nhấn mạnh: “Điều này có thể dễ hơn nhiều so với những gì mọi người tưởng tượng, và đó chính là lý do chúng tôi cần thận trọng.”
Chi tiết bài nghiên cứu các bạn tham khảo thêm tại đây
BÀI MỚI ĐANG THẢO LUẬN