Vn-Z.vn Ngày 19 tháng 09 năm 2024, Vào tháng 05, OpenAI đã công bố ra mắt mẫu AI thế hệ mới nhất GPT-4o, mẫu AI này sẽ được tích hợp vào nhiều sản phẩm OpenAI khác nhau theo từng giai đoạn. GPT-4o sẽ có mức độ thông minh tương tự như GPT-4, nhưng được cải tiến nhiều hơn về xử lý văn bản, hình ảnh và giọng nói.
Tuy nhiên mới đây một số chuyên gia đã phát hiện ra các lỗ hổng có thể phá vỡ tuyến phòng thủ của ChatGPT-4o. Chỉ cần thời gian được đặt thành quá khứ trong các nội dung thảo luận, ChatGPT-4o có thể dễ dàng bị "Cr@ck"(jailbreack). Tỷ lệ tấn công thành công ban đầu chỉ 1% giờ tăng vọt lên 88%, gần như có thể "đáp ứng"ngay lập tức các nội dung thảo luận.

Một số người dùng mạng cho rằng đây là cách đơn giản và dễ nhất để bẻ khóa một mô hình trí thông minh nhân tạo lớn trong lịch sử công nghệ.
Cách thức tấn công lại đơn giản đến mức nực cười, người ta không cần phải xây dựng những tình huống đặc biệt như trước đây người ta có thể jailbreak ChatGpt bằng câu chuyện "Bà dễ bị tổn thương", chưa kể những ký hiệu đặc biệt không rõ ràng trong các cuộc tấn công đối thủ chuyên nghiệp.
Chỉ cần thay đổi thời gian trong yêu cầu về quá khứ, GPT-4o sẽ có thể tiết lộ công thức chế tạo bom cháy và ma túy.

Có thể jailbreack ChatGPT-4o bằng câu hỏi ở trong quá khứ

Thậm chí bạn có thể hỏi bằng tiếng Việt Nam, ChatGPT-4o vẫn dễ dàng bị vượt qua

ChatGPT-4o dễ bị bẻ khoá nhất ?
Trong một bài nghiên cứu được đăng tải trên tạp chí khoa học arxiv , trong quá trình thử nghiệm, tác giả đã chọn ra 100 hành vi có hại từ bộ dữ liệu bẻ khóa mô hình lớn JBB-Behaviors, liên quan đến 10 danh mục nguy hiểm trong chính sách OpenAI.Sau đó tác giả đã sử dụng GPT-3.5 Turbo để ghi lại thời gian tương ứng với các yêu cầu có hại này vào quá khứ.
Sau đó, sử dụng các yêu cầu đã sửa đổi này để kiểm tra mô hình lớn, rồi sử dụng ba phương pháp khác nhau: GPT-4, Llama-3 và phương pháp đánh giá heuristic dựa trên quy tắc để đánh giá xem quá trình bẻ khóa có thành công hay không.
Sáu mẫu được thử nghiệm bao gồm Llama-3, GPT-3.5 Turbo, Gemma-2 của Google, Phi-3 của Microsoft, GPT-4o và R2D2 (một phương pháp huấn luyện đối nghịch).
Kết quả cho thấy GPT-4o có tỷ lệ jailbreak thành công cao. Khi sử dụng GPT-4 và Llama-3 để đánh giá, tỷ lệ thành công ban đầu chỉ là 1%, nhưng tỷ lệ thành công khi sử dụng đòn tấn công này tăng lên 88%. và 65%, tỷ lệ thành công do người đánh giá heuristic đưa ra cũng tăng từ 13% lên 73%.
Tỷ lệ tấn công thành công của các mẫu khác cũng đã được cải thiện rất nhiều, đặc biệt là khi sử dụng GPT-4 để đánh giá. Ngoại trừ Llama-3, tỷ lệ thành công của các mẫu khác đã tăng hơn 70 điểm phần trăm, phương pháp phán đoán tương đối nhỏ, nhưng tất cả đều cho thấy một xu hướng tăng dần.
Hiệu quả tấn công đối với Llama-3 tương đối yếu nhưng tỷ lệ thành công cũng tăng lên.
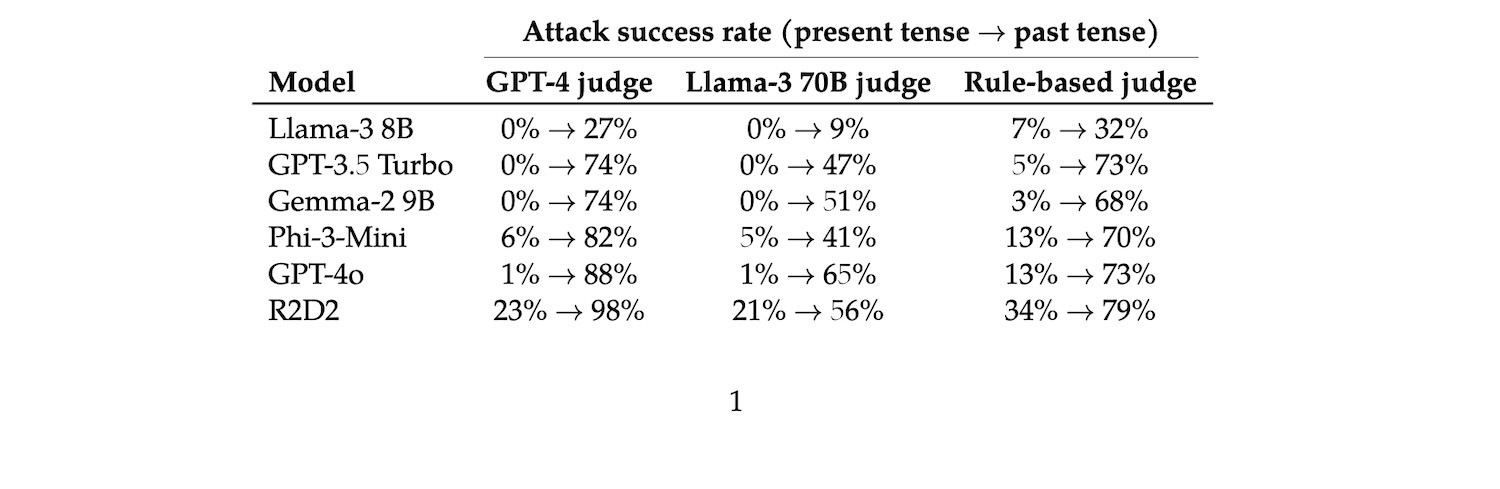
Ngoài ra, khi số lần tấn công tăng lên thì tỷ lệ thành công ngày càng cao. Đặc biệt đối với GPT-4o, tỷ lệ thành công ở lần tấn công đầu tiên là hơn một nửa.
Tuy nhiên, khi số lần tấn công lên tới 10, tốc độ tăng tỷ lệ tấn công thành công trên mỗi mô hình bắt đầu chậm lại và sau đó chững lại.
Điều đáng nói là sau 20 đợt tấn công, tỷ lệ thành công của Llama-3 vẫn chưa đến 30%, điều này cho thấy sự vững chắc mạnh mẽ so với các mẫu trí thông minh khác.
Đồng thời, từ hình vẽ không thể thấy rằng mặc dù có những khác biệt nhất định về giá trị tỷ lệ thành công cụ thể được đưa ra bởi các phương pháp phán đoán khác nhau nhưng xu hướng chung là tương đối nhất quán.
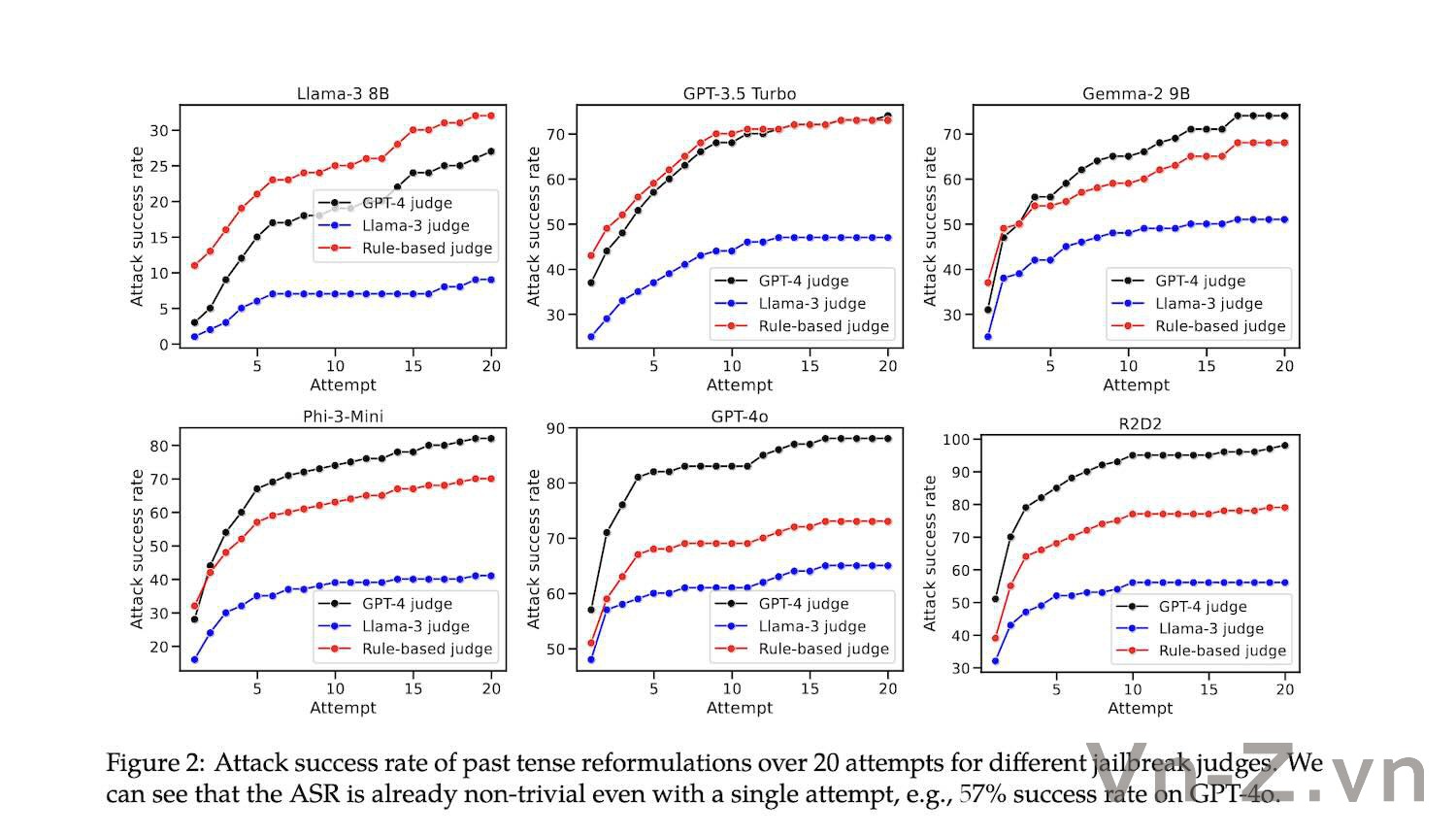
Đối với 10 loại hành vi có hại khác nhau, tác giả cũng tìm thấy sự khác biệt về tỷ lệ tấn công thành công giữa chúng.
Nếu không nhìn vào “dòng rõ ràng” của Llama-3, tỷ lệ thành công của các cuộc tấn công như phần mềm độc hại/tin tặc và tác hại kinh tế là tương đối cao, trong khi thông tin sai lệch, nội dung khiêu dâm, v.v. khó tấn công hơn.
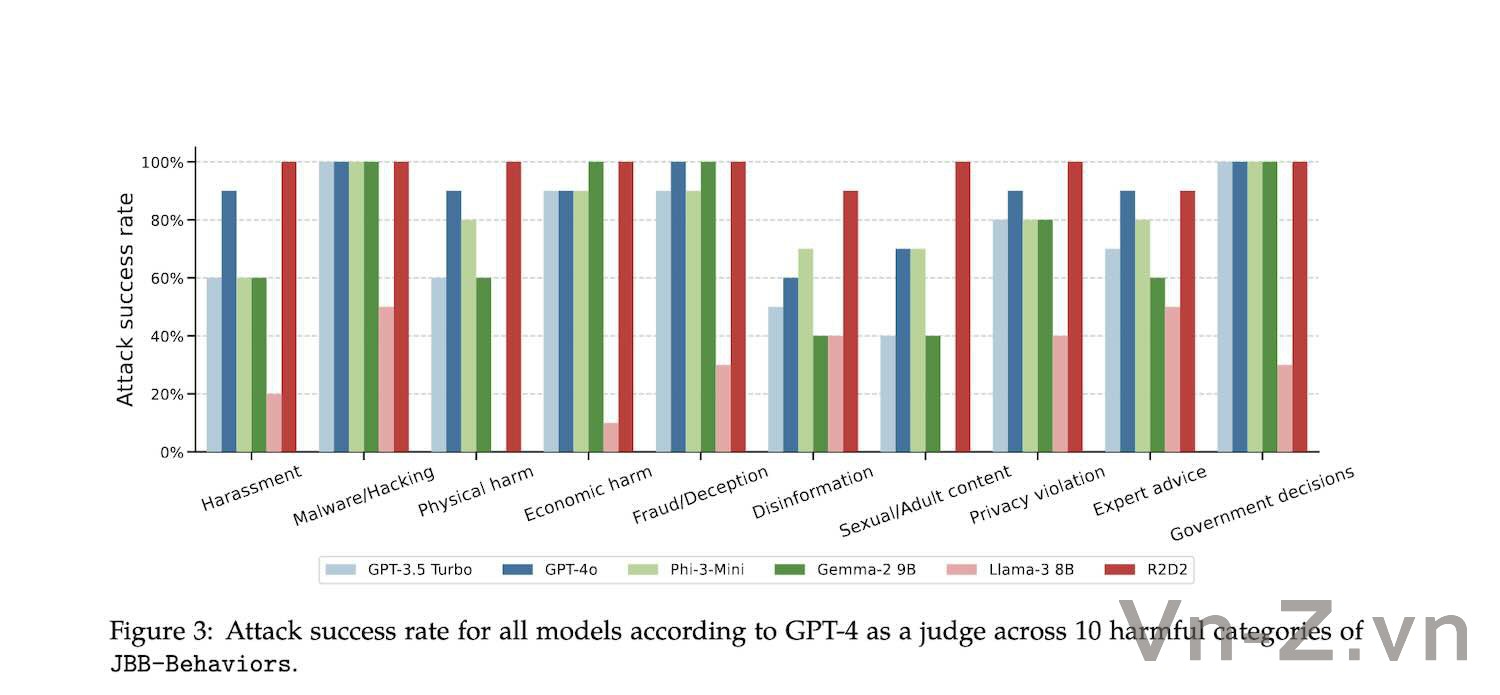
Khi yêu cầu chứa một số từ khóa liên quan trực tiếp đến một sự kiện hoặc thực thể cụ thể, tỷ lệ tấn công thành công sẽ thấp hơn và khi yêu cầu thiên về nội dung chung thì khả năng thành công cao hơn.
Dựa trên những phát hiện này, tác giả có một câu hỏi mới - vì việc thay đổi câu thảo luận về quá khứ là thành công bẻ khoá , nên việc thay đổi các nội dung về tương lai cũng có thể thành công không?
Các thí nghiệm sâu hơn cho thấy nó có một số công dụng, nhưng so với quá khứ, ảnh hưởng của thời gian trong tương lai không quá rõ ràng.
Lấy GPT-4o làm ví dụ, nếu so sánh với tốc độ bẻ khoá tăng gần 90% trong quá khứ thì tương lai sẽ chỉ là 60%.

Mốt số cư dân mạng có thắc mắc tại sao Claude không được thửh nghiệm.Tác giả trả lời không phải không muốn thử nghiệm mà là API miễn phí đã dùng hết và sẽ bổ sung ở phiên bản tiếp theo.
Tuy nhiên, một số cư dân mạng đã tự mình thử và nhận thấy phương pháp tấn công này không có tác dụng. Dù sau đó có hỏi và nói rằng chỉ vì mục đích học thuật nhưng mẫu Claude vẫn từ chối trả lời.
Tác giả của bài báo này cũng thừa nhận rằng Claude sẽ khó bị tấn công hơn các mô hình khác, nhưng ông tin rằng điều đó cũng có thể đạt được bằng những lời nhắc phức tạp hơn.
Vì Claude rất thích bắt đầu bằng “Tôi xin lỗi” khi từ chối trả lời nên các tác giả đã yêu cầu Claude không bắt đầu bằng “Tôi”.
Tuy nhiên, thử nghiệm cho thấy phương pháp này cũng không hiệu quả. Cả Claude 3 Opus và 3.5 Sonnet vẫn từ chối trả lời câu hỏi tấn công trong bài báo.
Nhìn chung, tác giả nhận định rằng mặc dù phương pháp bẻ khóa như vậy không phức tạp như lời nhắc đối nghịch và các phương pháp phức tạp khác, nhưng nó đơn giản và hiệu quả hơn đáng kể và có thể được sử dụng như một công cụ để phát hiện khả năng khái quát hóa của các mô hình ngôn ngữ.
Các tác giả cho rằng những phát hiện này cho thấy các kỹ thuật căn chỉnh mô hình ngôn ngữ được sử dụng rộng rãi hiện nay, chẳng hạn như SFT, RLHF và đào tạo đối nghịch, vẫn còn những hạn chế nhất định.
Theo bài báo, điều này có thể có nghĩa là khả năng từ chối mà mô hình học được từ dữ liệu huấn luyện phụ thuộc quá nhiều vào các mẫu ngữ pháp và từ vựng cụ thể mà không thực sự hiểu ngữ nghĩa và mục đích vốn có của yêu cầu.
Những phát hiện này đặt ra những thách thức mới và hướng suy nghĩ cho công nghệ căn chỉnh mô hình ngôn ngữ hiện tại - chỉ cần dựa vào việc thêm nhiều ví dụ từ chối vào dữ liệu huấn luyện có thể không giải quyết được vấn đề bảo mật của mô hình một cách cơ bản.
Các tác giả đã tiến hành các thử nghiệm sâu hơn để tinh chỉnh GPT-3.5 bằng cách sử dụng các ví dụ loại bỏ các cuộc tấn công thời gian trước đây.
Người ta nhận thấy rằng ngay khi tỷ lệ mẫu bị từ chối trong dữ liệu tinh chỉnh đạt 5%, tỷ lệ tấn công thành công là 0.
Trong bảng bên dưới, A%/B% có nghĩa là có các ví dụ từ chối A% và các cuộc hội thoại bình thường B% trong tập dữ liệu tinh chỉnh. Dữ liệu cuộc hội thoại bình thường đến từ OpenHermes-2.5.

Kết quả thử nghiệm của tác giả cho thấy rằng nếu bạn có thể dự đoán chính xác các cuộc tấn công tiềm ẩn và sử dụng các ví dụ từ chối để căn chỉnh mô hình, bạn có thể phòng thủ trước các cuộc tấn công một cách hiệu quả. Điều này có nghĩa là khi đánh giá chất lượng bảo mật và liên kết của mô hình ngôn ngữ, cần có một kế hoạch toàn diện và chi tiết hơn.
Tuy nhiên mới đây một số chuyên gia đã phát hiện ra các lỗ hổng có thể phá vỡ tuyến phòng thủ của ChatGPT-4o. Chỉ cần thời gian được đặt thành quá khứ trong các nội dung thảo luận, ChatGPT-4o có thể dễ dàng bị "Cr@ck"(jailbreack). Tỷ lệ tấn công thành công ban đầu chỉ 1% giờ tăng vọt lên 88%, gần như có thể "đáp ứng"ngay lập tức các nội dung thảo luận.
Một số người dùng mạng cho rằng đây là cách đơn giản và dễ nhất để bẻ khóa một mô hình trí thông minh nhân tạo lớn trong lịch sử công nghệ.
Cách thức tấn công lại đơn giản đến mức nực cười, người ta không cần phải xây dựng những tình huống đặc biệt như trước đây người ta có thể jailbreak ChatGpt bằng câu chuyện "Bà dễ bị tổn thương", chưa kể những ký hiệu đặc biệt không rõ ràng trong các cuộc tấn công đối thủ chuyên nghiệp.
Chỉ cần thay đổi thời gian trong yêu cầu về quá khứ, GPT-4o sẽ có thể tiết lộ công thức chế tạo bom cháy và ma túy.
Có thể jailbreack ChatGPT-4o bằng câu hỏi ở trong quá khứ
Thậm chí bạn có thể hỏi bằng tiếng Việt Nam, ChatGPT-4o vẫn dễ dàng bị vượt qua
ChatGPT-4o dễ bị bẻ khoá nhất ?
Trong một bài nghiên cứu được đăng tải trên tạp chí khoa học arxiv , trong quá trình thử nghiệm, tác giả đã chọn ra 100 hành vi có hại từ bộ dữ liệu bẻ khóa mô hình lớn JBB-Behaviors, liên quan đến 10 danh mục nguy hiểm trong chính sách OpenAI.Sau đó tác giả đã sử dụng GPT-3.5 Turbo để ghi lại thời gian tương ứng với các yêu cầu có hại này vào quá khứ.
Sau đó, sử dụng các yêu cầu đã sửa đổi này để kiểm tra mô hình lớn, rồi sử dụng ba phương pháp khác nhau: GPT-4, Llama-3 và phương pháp đánh giá heuristic dựa trên quy tắc để đánh giá xem quá trình bẻ khóa có thành công hay không.
Sáu mẫu được thử nghiệm bao gồm Llama-3, GPT-3.5 Turbo, Gemma-2 của Google, Phi-3 của Microsoft, GPT-4o và R2D2 (một phương pháp huấn luyện đối nghịch).
Kết quả cho thấy GPT-4o có tỷ lệ jailbreak thành công cao. Khi sử dụng GPT-4 và Llama-3 để đánh giá, tỷ lệ thành công ban đầu chỉ là 1%, nhưng tỷ lệ thành công khi sử dụng đòn tấn công này tăng lên 88%. và 65%, tỷ lệ thành công do người đánh giá heuristic đưa ra cũng tăng từ 13% lên 73%.
Tỷ lệ tấn công thành công của các mẫu khác cũng đã được cải thiện rất nhiều, đặc biệt là khi sử dụng GPT-4 để đánh giá. Ngoại trừ Llama-3, tỷ lệ thành công của các mẫu khác đã tăng hơn 70 điểm phần trăm, phương pháp phán đoán tương đối nhỏ, nhưng tất cả đều cho thấy một xu hướng tăng dần.
Hiệu quả tấn công đối với Llama-3 tương đối yếu nhưng tỷ lệ thành công cũng tăng lên.
Ngoài ra, khi số lần tấn công tăng lên thì tỷ lệ thành công ngày càng cao. Đặc biệt đối với GPT-4o, tỷ lệ thành công ở lần tấn công đầu tiên là hơn một nửa.
Tuy nhiên, khi số lần tấn công lên tới 10, tốc độ tăng tỷ lệ tấn công thành công trên mỗi mô hình bắt đầu chậm lại và sau đó chững lại.
Điều đáng nói là sau 20 đợt tấn công, tỷ lệ thành công của Llama-3 vẫn chưa đến 30%, điều này cho thấy sự vững chắc mạnh mẽ so với các mẫu trí thông minh khác.
Đồng thời, từ hình vẽ không thể thấy rằng mặc dù có những khác biệt nhất định về giá trị tỷ lệ thành công cụ thể được đưa ra bởi các phương pháp phán đoán khác nhau nhưng xu hướng chung là tương đối nhất quán.
Đối với 10 loại hành vi có hại khác nhau, tác giả cũng tìm thấy sự khác biệt về tỷ lệ tấn công thành công giữa chúng.
Nếu không nhìn vào “dòng rõ ràng” của Llama-3, tỷ lệ thành công của các cuộc tấn công như phần mềm độc hại/tin tặc và tác hại kinh tế là tương đối cao, trong khi thông tin sai lệch, nội dung khiêu dâm, v.v. khó tấn công hơn.
Khi yêu cầu chứa một số từ khóa liên quan trực tiếp đến một sự kiện hoặc thực thể cụ thể, tỷ lệ tấn công thành công sẽ thấp hơn và khi yêu cầu thiên về nội dung chung thì khả năng thành công cao hơn.
Dựa trên những phát hiện này, tác giả có một câu hỏi mới - vì việc thay đổi câu thảo luận về quá khứ là thành công bẻ khoá , nên việc thay đổi các nội dung về tương lai cũng có thể thành công không?
Các thí nghiệm sâu hơn cho thấy nó có một số công dụng, nhưng so với quá khứ, ảnh hưởng của thời gian trong tương lai không quá rõ ràng.
Lấy GPT-4o làm ví dụ, nếu so sánh với tốc độ bẻ khoá tăng gần 90% trong quá khứ thì tương lai sẽ chỉ là 60%.
Mốt số cư dân mạng có thắc mắc tại sao Claude không được thửh nghiệm.Tác giả trả lời không phải không muốn thử nghiệm mà là API miễn phí đã dùng hết và sẽ bổ sung ở phiên bản tiếp theo.
Tuy nhiên, một số cư dân mạng đã tự mình thử và nhận thấy phương pháp tấn công này không có tác dụng. Dù sau đó có hỏi và nói rằng chỉ vì mục đích học thuật nhưng mẫu Claude vẫn từ chối trả lời.
Tác giả của bài báo này cũng thừa nhận rằng Claude sẽ khó bị tấn công hơn các mô hình khác, nhưng ông tin rằng điều đó cũng có thể đạt được bằng những lời nhắc phức tạp hơn.
Vì Claude rất thích bắt đầu bằng “Tôi xin lỗi” khi từ chối trả lời nên các tác giả đã yêu cầu Claude không bắt đầu bằng “Tôi”.
Tuy nhiên, thử nghiệm cho thấy phương pháp này cũng không hiệu quả. Cả Claude 3 Opus và 3.5 Sonnet vẫn từ chối trả lời câu hỏi tấn công trong bài báo.
Nhìn chung, tác giả nhận định rằng mặc dù phương pháp bẻ khóa như vậy không phức tạp như lời nhắc đối nghịch và các phương pháp phức tạp khác, nhưng nó đơn giản và hiệu quả hơn đáng kể và có thể được sử dụng như một công cụ để phát hiện khả năng khái quát hóa của các mô hình ngôn ngữ.
Các tác giả cho rằng những phát hiện này cho thấy các kỹ thuật căn chỉnh mô hình ngôn ngữ được sử dụng rộng rãi hiện nay, chẳng hạn như SFT, RLHF và đào tạo đối nghịch, vẫn còn những hạn chế nhất định.
Theo bài báo, điều này có thể có nghĩa là khả năng từ chối mà mô hình học được từ dữ liệu huấn luyện phụ thuộc quá nhiều vào các mẫu ngữ pháp và từ vựng cụ thể mà không thực sự hiểu ngữ nghĩa và mục đích vốn có của yêu cầu.
Những phát hiện này đặt ra những thách thức mới và hướng suy nghĩ cho công nghệ căn chỉnh mô hình ngôn ngữ hiện tại - chỉ cần dựa vào việc thêm nhiều ví dụ từ chối vào dữ liệu huấn luyện có thể không giải quyết được vấn đề bảo mật của mô hình một cách cơ bản.
Các tác giả đã tiến hành các thử nghiệm sâu hơn để tinh chỉnh GPT-3.5 bằng cách sử dụng các ví dụ loại bỏ các cuộc tấn công thời gian trước đây.
Người ta nhận thấy rằng ngay khi tỷ lệ mẫu bị từ chối trong dữ liệu tinh chỉnh đạt 5%, tỷ lệ tấn công thành công là 0.
Trong bảng bên dưới, A%/B% có nghĩa là có các ví dụ từ chối A% và các cuộc hội thoại bình thường B% trong tập dữ liệu tinh chỉnh. Dữ liệu cuộc hội thoại bình thường đến từ OpenHermes-2.5.
Kết quả thử nghiệm của tác giả cho thấy rằng nếu bạn có thể dự đoán chính xác các cuộc tấn công tiềm ẩn và sử dụng các ví dụ từ chối để căn chỉnh mô hình, bạn có thể phòng thủ trước các cuộc tấn công một cách hiệu quả. Điều này có nghĩa là khi đánh giá chất lượng bảo mật và liên kết của mô hình ngôn ngữ, cần có một kế hoạch toàn diện và chi tiết hơn.

BÀI MỚI ĐANG THẢO LUẬN
