BBT-Neutron: Mô Hình AI Tính Toán Khoa Học Mã Nguồn Mở Đầu Tiên Giúp Vượt Qua Rào Cản Phân Tích Dữ Liệu Khoa Học
Vn-Z.vn Ngày 26 tháng 12 năm 2024, Liệu các mô hình ngôn ngữ lớn (LLM) có thể giải quyết những hạn chế của các mô hình truyền thống trong phân tích dữ liệu số quy mô lớn, đồng thời hỗ trợ cộng đồng khoa học trong thiết kế các thiết bị khoa học lớn và tính toán khoa học trong lĩnh vực vật lý năng lượng cao hay không?
Vật lý năng lượng cao là một lĩnh vực khoa học tiên tiến, khám phá cấu trúc cơ bản của vũ trụ và các quy luật chi phối nó. Lĩnh vực này nghiên cứu sự tương tác của các hạt trong điều kiện năng lượng cực cao, nhằm làm sáng tỏ nguồn gốc của vũ trụ, vật chất tối và năng lượng tối cùng nhiều bí ẩn chưa được giải quyết.
Các thí nghiệm vật lý năng lượng cao (như thí nghiệm va chạm hạt, nghiên cứu vật chất tối và năng lượng tối) tạo ra một khối lượng dữ liệu khổng lồ và phức tạp. Các phương pháp phân tích dữ liệu truyền thống gặp khó khăn trong việc xử lý dữ liệu lớn và cấu trúc vật lý phức tạp, dẫn đến những nút thắt trong tính toán.
Gần đây, một bài báo có tiêu đề “Scaling Particle Collision Data Analysis” đã được công bố trên arXiv. Bài báo khám phá ứng dụng mới của các mô hình ngôn ngữ lớn trong phân tích dữ liệu từ các thiết bị khoa học lớn và tính toán khoa học.
Cụ thể, nhóm nghiên cứu đã áp dụng mô hình nền tảng khoa học mới nhất của mình, BBT-Neutron, vào các thí nghiệm va chạm hạt. Mô hình này sử dụng phương pháp mã hóa nhị phân (Binary Tokenization) hoàn toàn mới, cho phép huấn luyện đa dạng trên dữ liệu đa phương thức (bao gồm dữ liệu số từ các thí nghiệm quy mô lớn, văn bản và hình ảnh).
Bài báo so sánh kết quả thực nghiệm giữa kiến trúc mô hình tổng quát của BBT-Neutron và các mô hình chuyên dụng tiên tiến nhất như ParticleNet và Particle Transformer trong nhiệm vụ phân loại nguồn gốc Jet (Jet Origin Identification - JoI) trong lĩnh vực vật lý hạt nhân.
Kết quả nhận diện phân loại hạt (hình 1-3) cho thấy hiệu suất của kiến trúc mô hình tổng quát tương đương với các mô hình chuyên biệt. Điều này cũng khẳng định khả năng của kiến trúc dựa trên decoder-only sequence-to-sequence trong việc học và hiểu các quy luật vật lý.
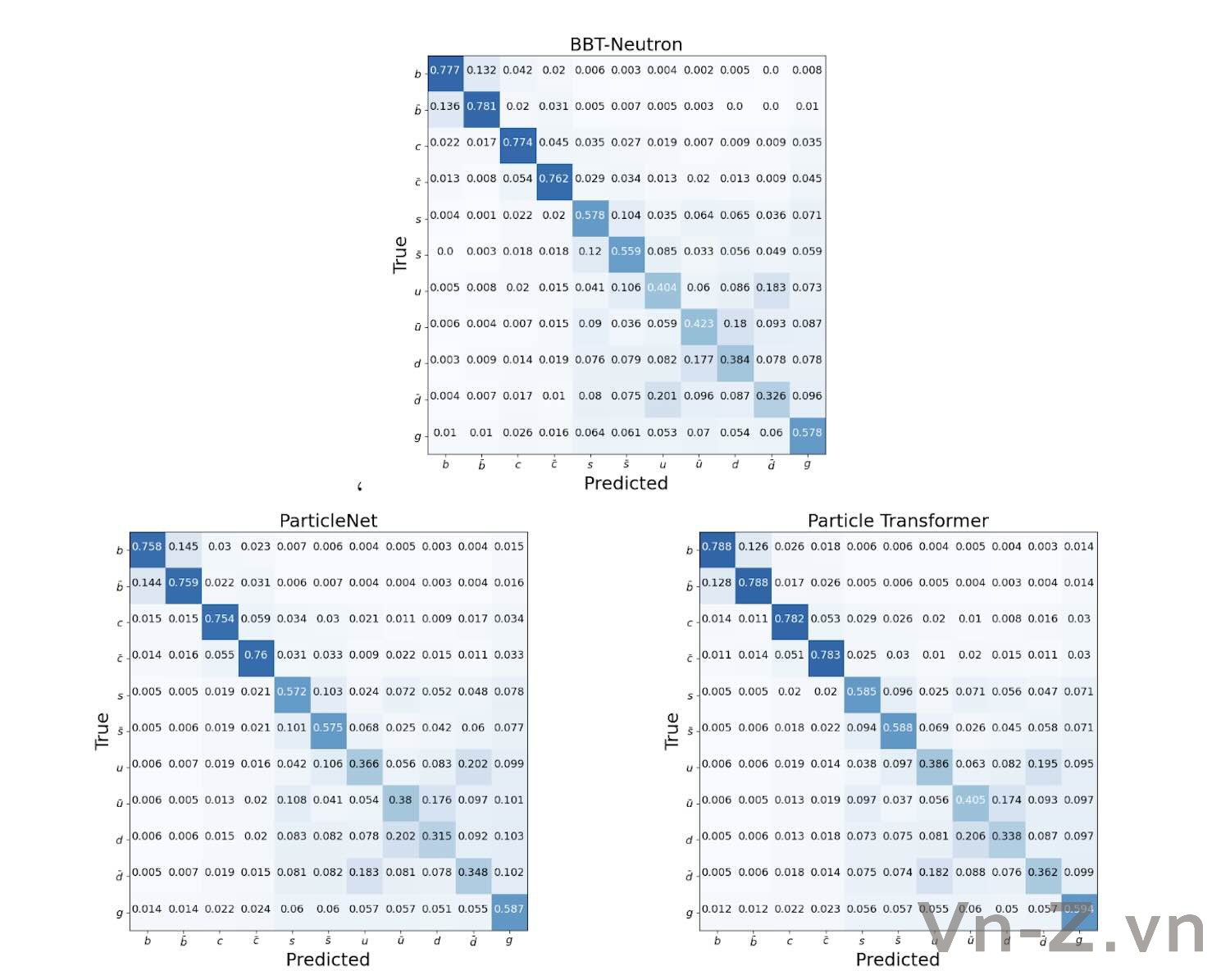
Hình 1: Kết quả nhận dạng 11 loại nguồn phun hạt sử dụng mô hình BBT-Neutron - Nhóm công nghệ siêu đối xứng
Hình 2: Kết quả xác định 11 loại nguồn phun hạt trong mô hình ParticleNet - được cung cấp bởi cộng tác viên trên giấy và nhóm phát triển ParticleNet (nhóm của Ruan Manqi tại Viện Năng lượng cao)
Hình 3: Kết quả xác định 11 loại nguồn phun hạt trong mô hình Máy biến đổi hạt - được cung cấp bởi cộng tác viên trên giấy và nhóm phát triển Máy biến áp hạt (nhóm CERN Qu Huilin)
Các mô hình này đều cho thấy hiệu suất được cải thiện khi kích thước tập dữ liệu được mở rộng, với các chỉ số như Jet Flavor Tagging Efficiency và Charge Flip Rate hình thành đường cong chữ S.
Tuy nhiên, hành vi mở rộng giữa BBT-Neutron và các mô hình chuyên biệt có sự khác biệt rõ rệt. Các ngưỡng dữ liệu quan trọng trên đường cong chữ S cho thấy hiện tượng nổi bật đã xuất hiện trong BBT-Neutron (nhưng không xảy ra ở các kiến trúc chuyên biệt). Điều này không chỉ phá vỡ quan niệm truyền thống rằng kiến trúc này không phù hợp để mô hình hóa các đặc trưng vật lý liên tục mà còn khẳng định khả năng mở rộng của mô hình tổng quát trong các nhiệm vụ tính toán khoa học quy mô lớn.
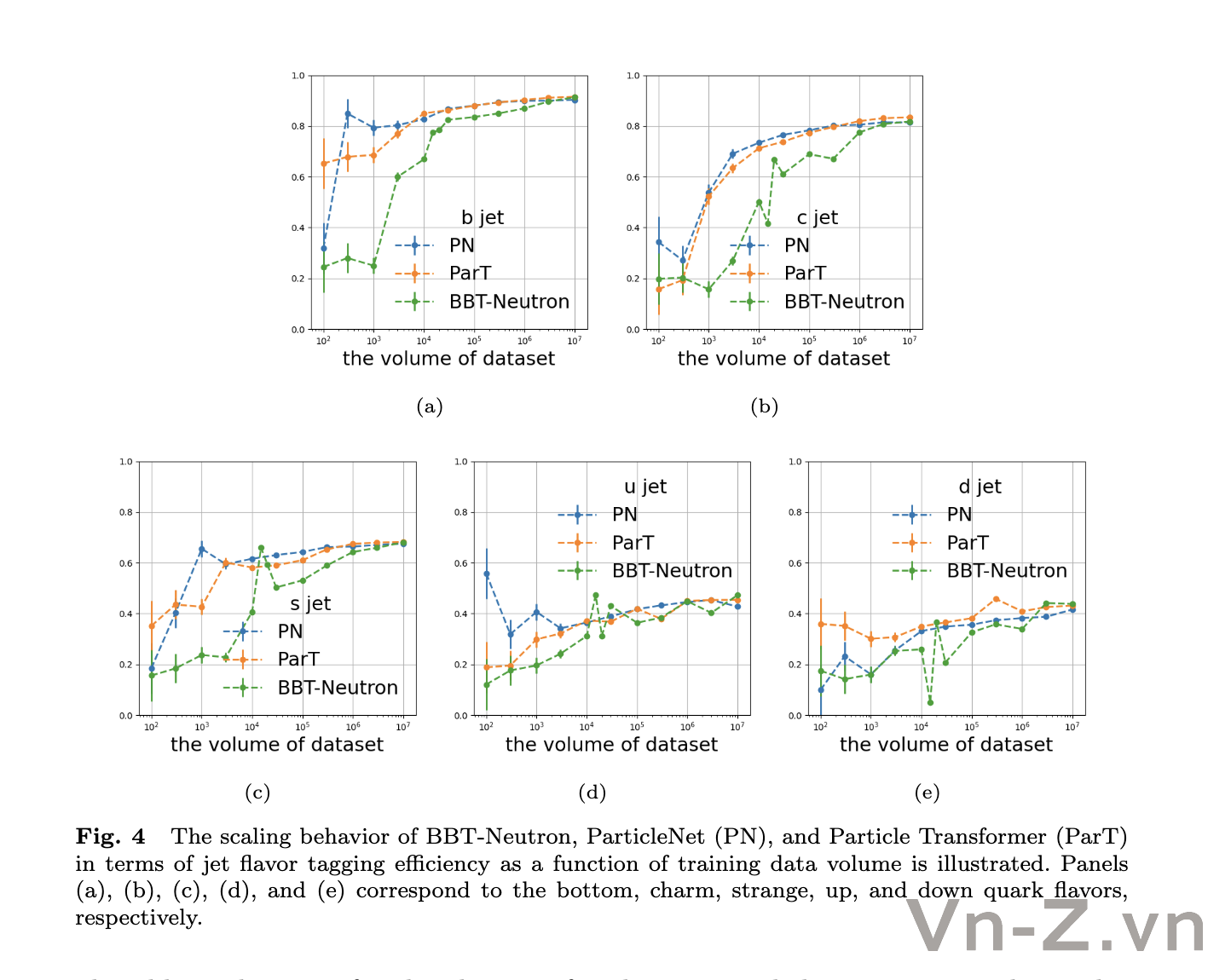
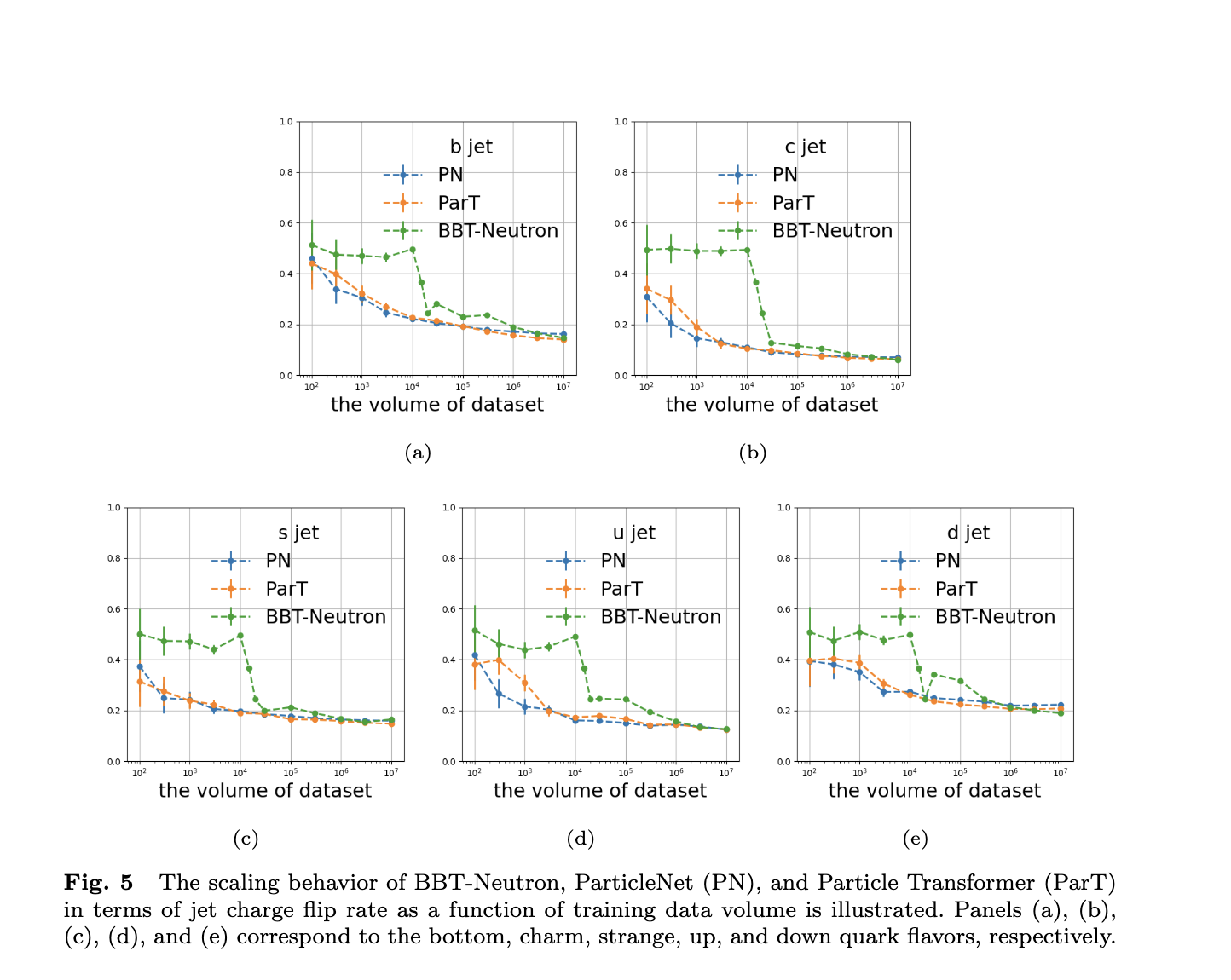
Mối quan hệ giữa độ chính xác nhận dạng hương vị phun (hình 4) và tỷ lệ đánh giá sai phí (hình 5) và lượng dữ liệu huấn luyện
Phân từ nhị phân: Hợp nhất xử lý dữ liệu đa phương thức, phá vỡ giới hạn phân tích dữ liệu số
Trong những năm gần đây, các mô hình ngôn ngữ lớn đã đạt được những tiến bộ đáng kể trong xử lý văn bản, trả lời câu hỏi thông thường và các nhiệm vụ khác. Tuy nhiên, chúng vẫn đối mặt với thách thức trong việc xử lý dữ liệu số quy mô lớn.
Phương pháp phân từ BPE truyền thống khi phân tách các số có thể dẫn đến sự mơ hồ và không nhất quán, đặc biệt trong các lĩnh vực như vật lý năng lượng cao và quan sát thiên văn, nơi việc phân tích dữ liệu thực nghiệm phức tạp đã trở thành một nút thắt cổ chai.
Để giúp các mô hình lớn thích nghi tốt hơn với các kịch bản tính toán khoa học, nghiên cứu này đã giới thiệu một phương pháp phân từ nhị phân sáng tạo (Binary Tokenization), sử dụng biểu diễn nhị phân trong lưu trữ máy tính để biểu diễn dữ liệu. Phương pháp này hợp nhất dữ liệu số với văn bản, hình ảnh và các dữ liệu đa phương thức khác.
Điều này cho phép phân từ nhị phân xử lý thống nhất tất cả các loại dữ liệu mà không cần tiền xử lý bổ sung, giúp đơn giản hóa quy trình và đảm bảo tính nhất quán của dữ liệu đầu vào.
Nhóm nghiên cứu đã trình bày chi tiết trong bài báo cách khắc phục các giới hạn của phương pháp BPE truyền thống và quy trình xử lý dữ liệu.
Hạn chế của phương pháp BPE
Sự mơ hồ và không nhất quán
BPE là một phương pháp token hóa dựa trên tần suất, nó phân tách các số thành các đơn vị con khác nhau dựa trên ngữ cảnh, có thể dẫn đến cách phân tách khác nhau cho cùng một số.
Ví dụ, số 12345 trong một ngữ cảnh có thể được phân tách thành “12”, “34”, và “5”, trong khi ở ngữ cảnh khác lại phân tách thành “1”, “23”, và “45”. Điều này làm mất đi ý nghĩa vốn có của số nguyên bản, phá vỡ tính toàn vẹn và quan hệ của số liệu.
Tính không liên tục của mã token ID
BPE có thể dẫn đến mã token ID của các số không liên tục. Ví dụ, mã token ID của số “7” và “8” có thể được phân phối lần lượt là 4779 và 5014.
Sự không liên tục này làm cho việc quản lý và xử lý dữ liệu số trở nên phức tạp hơn. Đặc biệt, khi cần các mã token ID theo thứ tự hoặc có tính mô hình hóa, sự không liên tục này sẽ ảnh hưởng đến khả năng phân tích và xử lý dữ liệu số của mô hình.
Vấn đề token hóa số đơn lẻ
Mặc dù phương pháp token hóa số đơn lẻ rất đơn giản và trực quan, nhưng nó cũng gây ra vấn đề mã token ID không liên tục với các số nhiều chữ số. Ví dụ, số 15 có thể bị phân tách thành các token độc lập “1” và “5”, mỗi token được ánh xạ tới một mã token ID riêng.
Sự phân tách này có thể phá vỡ tính liên tục của thông tin số, làm cho mô hình khó nắm bắt được cấu trúc và mối quan hệ nội tại của các số nhiều chữ số.
Phương pháp xử lý dữ liệu số
• Đối với dữ liệu văn bản: Sử dụng mã hóa UTF-8 để chuyển đổi các ký tự thành chuỗi byte.
• Đối với dữ liệu số: Áp dụng hai chiến lược:
1. Nếu cần giữ nguyên định dạng chính xác của số, bao gồm cả các số 0 quan trọng ở đầu, số được xử lý như một chuỗi và mã hóa bằng UTF-8.
2. Khi thực hiện các phép toán số học hoặc xử lý số liệu quan trọng, số được chuyển đổi thành dạng số (ví dụ, số nguyên) và sau đó thành mảng byte. Phương pháp này đảm bảo khả năng xử lý nhất quán và hiệu quả cho các loại dữ liệu khác nhau.
• Đối với công thức hoặc ký hiệu khoa học: Các biểu thức phức tạp được phân tích và chuỗi hóa thành chuỗi byte, đảm bảo nắm bắt được cấu trúc và nội dung của công thức. Ví dụ, công thức được mã hóa thành mảng byte [69, 61, 109, 99, 94, 50], đại diện cho cấu trúc và các biến của công thức.
• Đối với dữ liệu hình ảnh: Sử dụng phương pháp patch để chia nhỏ hình ảnh thành các mảnh, nâng cao hiệu quả xử lý dữ liệu điểm ảnh dày đặc.
Kiến trúc mô hình BBT-Neutron: Nắm bắt hiệu quả mối quan hệ số liệu và thích nghi đa nhiệm
Kiến trúc mô hình BBT-Neutron bao gồm ba phần chính: Patch Embedding, Patch Self-Attention, và LM Head. Mô hình này có khả năng chuyển đổi chuỗi đầu vào thông qua phân từ nhị phân thành vector không gian cao, từ đó thực hiện các nhiệm vụ như phân loại và hồi quy.
Patch Embedding
Bao gồm hai lớp tuyến tính:
• Lớp đầu tiên chiếu mảnh đầu vào lên không gian cao hơn.
• Lớp thứ hai tinh chỉnh biểu diễn này, tạo ra vector nhúng cuối cùng.
Patch Self-Attention
Cơ chế tự chú ý tại cấp độ patch thực hiện các phép toán chú ý trên mỗi patch, cho phép trao đổi thông tin giữa các patch và bên trong từng patch.
LM Head
Đầu ra có kích thước được định nghĩa bởi Patch Size × 257, trong đó 257 là tổng số giá trị byte từ 0 đến 255, cộng thêm ID điền 256. Thiết kế này giúp mô hình dự đoán độc lập từng patch một cách hiệu quả và chính xác.
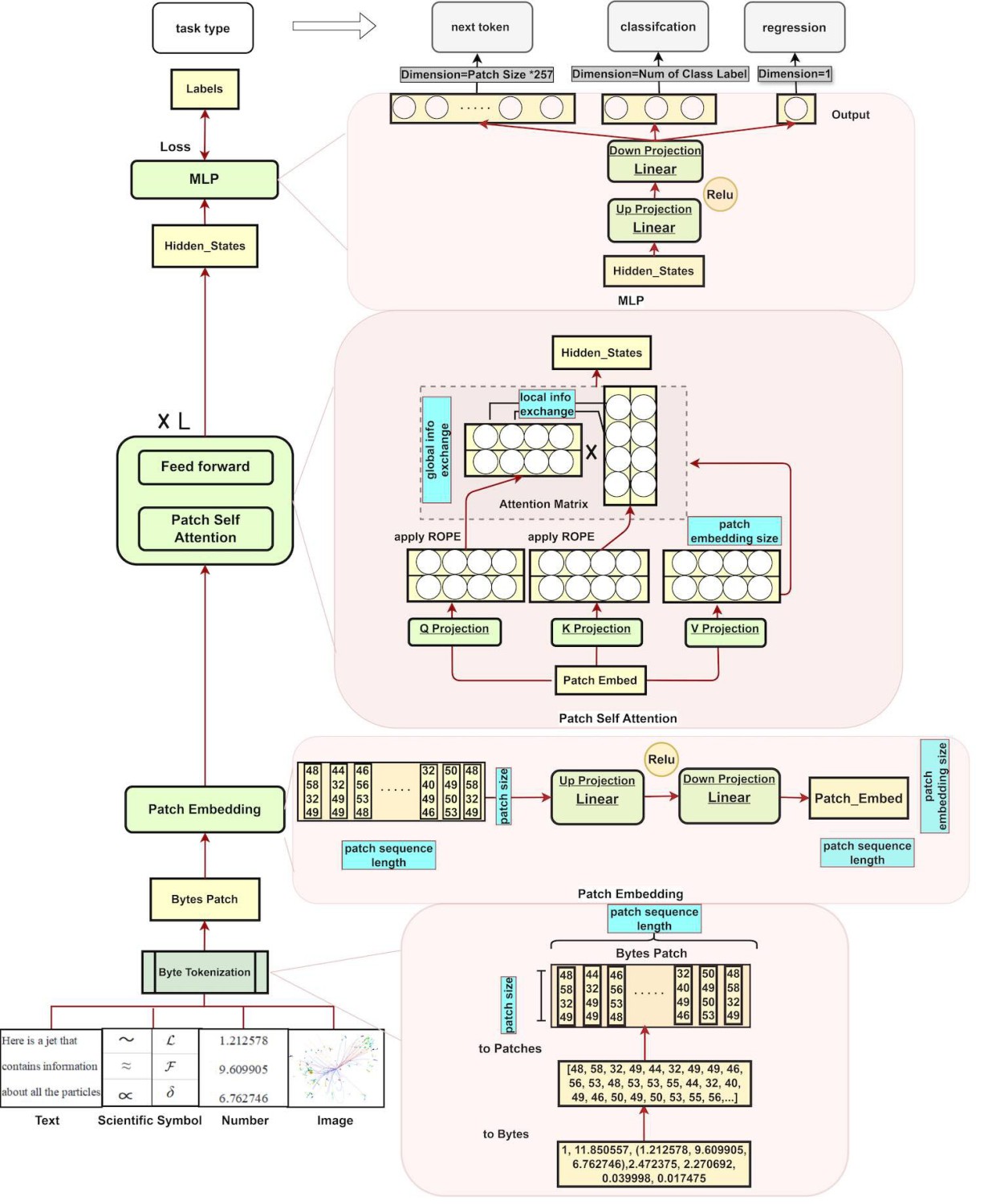
Sơ đồ kiến trúc mô hình BBT-Neutron
Ứng dụng trong phân tích dữ liệu va chạm vật lý hạt: Hiệu năng kiến trúc phổ quát đạt mức SOTA trong lĩnh vực chuyên môn
Nhóm phát triển đã công bố kết quả thực nghiệm đầu tiên của kiến trúc phổ quát BBT-Neutron trong bài báo khoa học, áp dụng cho một nhiệm vụ trọng yếu trong vật lý hạt - nhận dạng nguồn gốc của tia phun (Jet Origin Identification, JoI) - và đạt được những đột phá đáng kể.
Nhận dạng nguồn gốc của tia phun (JoI): Một thách thức cốt lõi trong vật lý năng lượng cao
Trong các thí nghiệm vật lý năng lượng cao, nhận dạng nguồn gốc của tia phun là một trong những thách thức lớn nhất. Nhiệm vụ này nhằm phân biệt các tia phun được tạo ra từ các quark khác nhau hoặc từ gluon.
• Trong các vụ va chạm năng lượng cao, quark hoặc gluon sinh ra ngay lập tức hình thành một chùm hạt - chủ yếu là hadron - di chuyển theo cùng một hướng.
• Chùm hạt này, thường được gọi là tia phun, là đối tượng đo lường quan trọng trong các thí nghiệm va chạm.
Việc xác định nguồn gốc của tia phun có vai trò quan trọng đối với nhiều phân tích vật lý, đặc biệt là trong nghiên cứu các boson Higgs, W và Z - các boson này gần như 70% sẽ phân rã trực tiếp thành hai tia phun.
Ngoài ra, tia phun còn là nền tảng để hiểu về sắc động lực học lượng tử (Quantum Chromodynamics - QCD), một lý thuyết mô tả cơ chế tương tác giữa các hạt mang màu như quark và gluon trong hạt nhân nguyên tử.
Thách thức trong nhận dạng tia phun
Các tia phun được sinh ra từ các hạt mang màu khác nhau chỉ có những khác biệt nhỏ trong các đại lượng quan sát được. Điều này làm cho việc nhận dạng chính xác nguồn gốc của tia phun trở nên cực kỳ khó khăn.
Kiến trúc BBT-Neutron đã chứng minh khả năng giải quyết các thách thức này, đạt hiệu năng ngang tầm hoặc vượt qua các phương pháp tiên tiến nhất trong lĩnh vực chuyên môn (SOTA).
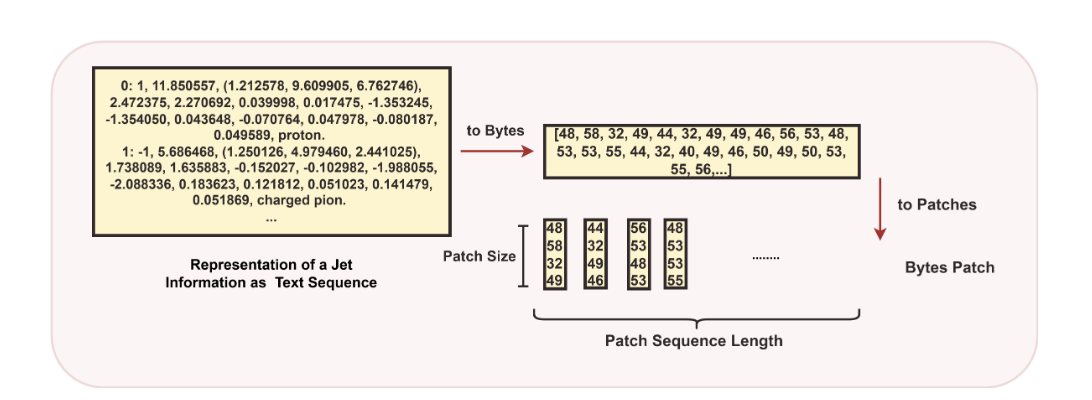
Phương pháp phân đoạn từ nhị phân với luồng dữ liệu vật lý hạt xử lý bản vá
Kết quả thí nghiệm cho thấy, nghiên cứu này đạt hiệu năng ngang bằng với các mô hình chuyên ngành tiên tiến nhất (như Particle Transformer và ParticleNet, vốn tích hợp các định luật vật lý chuyên ngành vào thiết kế kiến trúc GNN), đạt mức SOTA trong ngành (Hình 1-3).
Kết quả này xác nhận rằng kiến trúc phổ quát dựa trên seq2seq và mô hình decoder-only có khả năng học các quy luật vật chất và vật lý ngang bằng với các mô hình chuyên ngành.
Quan niệm truyền thống cho rằng seq2seq không phù hợp với việc mô hình hóa các thực tại vật lý có tính liên tục như thời gian, không gian, và năng lượng, mà chỉ phù hợp với việc mô hình hóa các ký hiệu rời rạc như ngôn ngữ của con người. Ngoài ra, cách học từ trái sang phải với tính chất tuyến tính vị trí không phù hợp với các cấu trúc vật lý có tính đối xứng thời gian và không gian. Để mô hình học được các định luật vật lý chuyên ngành, cần tích hợp các cấu trúc chuyên ngành của lĩnh vực đó vào kiến trúc mô hình.
Kết quả nghiên cứu này đã chứng minh giới hạn của quan niệm trên, đồng thời cung cấp một phương pháp hiệu quả để biểu diễn các đại lượng cơ bản trong vật lý như thời gian, không gian và năng lượng. Nó cũng đặt nền tảng cho việc xây dựng một mô hình thống nhất trong các lĩnh vực khoa học chuyên ngành như vật lý và hóa học.
Phân tích tỷ lệ: Khám phá hành vi mới nổi
Bằng cách so sánh hành vi chia tỷ lệ của ParticleNet và Particle Transformer trong nhiệm vụ JoI, bài viết tiến hành phân tích chuyên sâu về hành vi chia tỷ lệ khi kích thước dữ liệu tăng lên.
Các bộ dữ liệu huấn luyện này có phạm vi từ 1 triệu đến 10 triệu sự kiện và kết quả thử nghiệm được đo bằng ba số liệu chính: ma trận nhầm lẫn, hiệu suất gắn thẻ hương vị máy bay phản lực và hiệu suất mô hình điện tích.
Ma trận nhầm lẫn (Ma trận nhầm lẫn) sử dụng ma trận nhầm lẫn 11 chiều M11 để phân loại từng lần tiêm và phân loại vào danh mục tương ứng theo điểm dự đoán cao nhất. Các khối được chéo thành các khối 2×2 và mỗi khối tương ứng với một khối cụ thể. Các loại quark Ma trận nhầm lẫn cung cấp cái nhìn tổng quan toàn diện về hiệu suất phân loại của mô hình, nêu bật các dự đoán đúng và sai trong các danh mục tiêm khác nhau.
Hiệu suất gắn thẻ hương vị phản lực được định nghĩa bằng một nửa tổng các giá trị trong mỗi khối, không phân biệt giữa các tia được tạo ra bởi quark và phản quark.
Tốc độ lật điện tích được định nghĩa là tỷ lệ của các phần tử ngoài đường chéo trong khối với tổng các khối và biểu thị xác suất xác định sai sự phóng điện do quark và phản quark tạo ra.
Nhóm phát triển chỉ ra rằng đã xuất hiện các hành vi mở rộng khác biệt giữa mô hình này và các mô hình chuyên biệt.
Trên đường cong S của BBT-Neutron, các ngưỡng dữ liệu quan trọng, đặc biệt là dữ liệu của Tỷ lệ đảo chiều điện tích (Charge Flip Rate), đã cho thấy sự biến đổi hiệu suất đột ngột, biểu hiện rõ rệt hiện tượng nổi bật (Model Emergence). Tuy nhiên, hiện tượng này không được quan sát thấy trong ParticleNet hay Particle Transformer.
Nguyên nhân có thể là do các mô hình chuyên biệt đã tích hợp các đặc điểm cấu trúc thuộc lĩnh vực cụ thể, sử dụng kiến trúc thiết kế riêng để mô tả sự tương tác và phân loại hạt, điều này có thể khiến hiệu suất nhanh chóng đạt ngưỡng bão hòa khi quy mô dữ liệu tăng.
Ngược lại, mô hình kiến trúc chung trong nghiên cứu này sử dụng cách biểu diễn dữ liệu thống nhất để xử lý mọi cấu trúc vật lý. Các mô hình chuyên biệt đạt tính bất biến hoán vị (permutative invariance) thông qua việc loại bỏ mã hóa vị trí hoặc các thao tác liên quan, trong khi BBT-Neutron không dựa vào tính bất biến hoán vị mà áp dụng đầu vào tuần tự từ trái sang phải, tương đồng với quy trình seq2seq trong các mô hình ngôn ngữ.
Dù phương pháp này đòi hỏi tập dữ liệu lớn hơn để suy luận, nhưng một khi vượt qua ngưỡng dữ liệu quan trọng, mô hình có thể đạt được bước nhảy vọt đáng kể về hiệu suất. Điều này cho thấy, dù không tích hợp rõ ràng tính bất biến hoán vị trong thiết kế kiến trúc như các mô hình chuyên biệt, BBT-Neutron vẫn có thể học được tính đối xứng không gian thông qua việc huấn luyện trên một lượng dữ liệu đủ lớn.
Hiểu một cách đơn giản, khi quy mô dữ liệu tăng dần, mô hình này đã có sự chuyển đổi hiệu suất rõ rệt. Phát hiện này xác nhận khả năng mở rộng của mô hình chung trong các nhiệm vụ tính toán khoa học quy mô lớn, cho thấy mô hình này có tiềm năng trở thành nền tảng tính toán khoa học đa lĩnh vực.
Nghiên cứu này đánh dấu tiềm năng to lớn của các mô hình lớn trong xử lý dữ liệu đa phương thức và nhiệm vụ tính toán khoa học. Với sự kết hợp sâu sắc giữa công nghệ trí tuệ nhân tạo và các thiết bị khoa học lớn, trong tương lai, có thể đẩy nhanh việc triển khai các dự án nghiên cứu tiên phong như máy gia tốc CEPC của Trung Quốc.
Thành viên nhóm CEPC, ông Nguyễn Mạn Kỳ, từng nhận xét: *“Công nghệ trí tuệ nhân tạo sẽ hỗ trợ thiết kế và phát triển các thiết bị khoa học lớn, giúp tăng cường đáng kể khả năng khám phá khoa học của chúng, từ đó hỗ trợ tốt hơn trong việc khám phá các bí ẩn của thế giới và mở rộng ranh giới tri thức của nhân loại.
Ngược lại, thông qua việc tổng hợp và so sánh sự khác biệt hiệu suất AI được quan sát trong các vấn đề khoa học cụ thể, chúng ta cũng có thể hiểu sâu hơn về bản thân công nghệ AI, từ đó thúc đẩy sự phát triển của công nghệ này.”*
Quá trình phát triển mô hình BBT:

 github.com
github.com
Vật lý năng lượng cao là một lĩnh vực khoa học tiên tiến, khám phá cấu trúc cơ bản của vũ trụ và các quy luật chi phối nó. Lĩnh vực này nghiên cứu sự tương tác của các hạt trong điều kiện năng lượng cực cao, nhằm làm sáng tỏ nguồn gốc của vũ trụ, vật chất tối và năng lượng tối cùng nhiều bí ẩn chưa được giải quyết.
Các thí nghiệm vật lý năng lượng cao (như thí nghiệm va chạm hạt, nghiên cứu vật chất tối và năng lượng tối) tạo ra một khối lượng dữ liệu khổng lồ và phức tạp. Các phương pháp phân tích dữ liệu truyền thống gặp khó khăn trong việc xử lý dữ liệu lớn và cấu trúc vật lý phức tạp, dẫn đến những nút thắt trong tính toán.
Gần đây, một bài báo có tiêu đề “Scaling Particle Collision Data Analysis” đã được công bố trên arXiv. Bài báo khám phá ứng dụng mới của các mô hình ngôn ngữ lớn trong phân tích dữ liệu từ các thiết bị khoa học lớn và tính toán khoa học.
Cụ thể, nhóm nghiên cứu đã áp dụng mô hình nền tảng khoa học mới nhất của mình, BBT-Neutron, vào các thí nghiệm va chạm hạt. Mô hình này sử dụng phương pháp mã hóa nhị phân (Binary Tokenization) hoàn toàn mới, cho phép huấn luyện đa dạng trên dữ liệu đa phương thức (bao gồm dữ liệu số từ các thí nghiệm quy mô lớn, văn bản và hình ảnh).
Bài báo so sánh kết quả thực nghiệm giữa kiến trúc mô hình tổng quát của BBT-Neutron và các mô hình chuyên dụng tiên tiến nhất như ParticleNet và Particle Transformer trong nhiệm vụ phân loại nguồn gốc Jet (Jet Origin Identification - JoI) trong lĩnh vực vật lý hạt nhân.
Kết quả nhận diện phân loại hạt (hình 1-3) cho thấy hiệu suất của kiến trúc mô hình tổng quát tương đương với các mô hình chuyên biệt. Điều này cũng khẳng định khả năng của kiến trúc dựa trên decoder-only sequence-to-sequence trong việc học và hiểu các quy luật vật lý.
Hình 1: Kết quả nhận dạng 11 loại nguồn phun hạt sử dụng mô hình BBT-Neutron - Nhóm công nghệ siêu đối xứng
Hình 2: Kết quả xác định 11 loại nguồn phun hạt trong mô hình ParticleNet - được cung cấp bởi cộng tác viên trên giấy và nhóm phát triển ParticleNet (nhóm của Ruan Manqi tại Viện Năng lượng cao)
Hình 3: Kết quả xác định 11 loại nguồn phun hạt trong mô hình Máy biến đổi hạt - được cung cấp bởi cộng tác viên trên giấy và nhóm phát triển Máy biến áp hạt (nhóm CERN Qu Huilin)
Các mô hình này đều cho thấy hiệu suất được cải thiện khi kích thước tập dữ liệu được mở rộng, với các chỉ số như Jet Flavor Tagging Efficiency và Charge Flip Rate hình thành đường cong chữ S.
Tuy nhiên, hành vi mở rộng giữa BBT-Neutron và các mô hình chuyên biệt có sự khác biệt rõ rệt. Các ngưỡng dữ liệu quan trọng trên đường cong chữ S cho thấy hiện tượng nổi bật đã xuất hiện trong BBT-Neutron (nhưng không xảy ra ở các kiến trúc chuyên biệt). Điều này không chỉ phá vỡ quan niệm truyền thống rằng kiến trúc này không phù hợp để mô hình hóa các đặc trưng vật lý liên tục mà còn khẳng định khả năng mở rộng của mô hình tổng quát trong các nhiệm vụ tính toán khoa học quy mô lớn.
Mối quan hệ giữa độ chính xác nhận dạng hương vị phun (hình 4) và tỷ lệ đánh giá sai phí (hình 5) và lượng dữ liệu huấn luyện
Phân từ nhị phân: Hợp nhất xử lý dữ liệu đa phương thức, phá vỡ giới hạn phân tích dữ liệu số
Trong những năm gần đây, các mô hình ngôn ngữ lớn đã đạt được những tiến bộ đáng kể trong xử lý văn bản, trả lời câu hỏi thông thường và các nhiệm vụ khác. Tuy nhiên, chúng vẫn đối mặt với thách thức trong việc xử lý dữ liệu số quy mô lớn.
Phương pháp phân từ BPE truyền thống khi phân tách các số có thể dẫn đến sự mơ hồ và không nhất quán, đặc biệt trong các lĩnh vực như vật lý năng lượng cao và quan sát thiên văn, nơi việc phân tích dữ liệu thực nghiệm phức tạp đã trở thành một nút thắt cổ chai.
Để giúp các mô hình lớn thích nghi tốt hơn với các kịch bản tính toán khoa học, nghiên cứu này đã giới thiệu một phương pháp phân từ nhị phân sáng tạo (Binary Tokenization), sử dụng biểu diễn nhị phân trong lưu trữ máy tính để biểu diễn dữ liệu. Phương pháp này hợp nhất dữ liệu số với văn bản, hình ảnh và các dữ liệu đa phương thức khác.
Điều này cho phép phân từ nhị phân xử lý thống nhất tất cả các loại dữ liệu mà không cần tiền xử lý bổ sung, giúp đơn giản hóa quy trình và đảm bảo tính nhất quán của dữ liệu đầu vào.
Nhóm nghiên cứu đã trình bày chi tiết trong bài báo cách khắc phục các giới hạn của phương pháp BPE truyền thống và quy trình xử lý dữ liệu.
Hạn chế của phương pháp BPE
Sự mơ hồ và không nhất quán
BPE là một phương pháp token hóa dựa trên tần suất, nó phân tách các số thành các đơn vị con khác nhau dựa trên ngữ cảnh, có thể dẫn đến cách phân tách khác nhau cho cùng một số.
Ví dụ, số 12345 trong một ngữ cảnh có thể được phân tách thành “12”, “34”, và “5”, trong khi ở ngữ cảnh khác lại phân tách thành “1”, “23”, và “45”. Điều này làm mất đi ý nghĩa vốn có của số nguyên bản, phá vỡ tính toàn vẹn và quan hệ của số liệu.
Tính không liên tục của mã token ID
BPE có thể dẫn đến mã token ID của các số không liên tục. Ví dụ, mã token ID của số “7” và “8” có thể được phân phối lần lượt là 4779 và 5014.
Sự không liên tục này làm cho việc quản lý và xử lý dữ liệu số trở nên phức tạp hơn. Đặc biệt, khi cần các mã token ID theo thứ tự hoặc có tính mô hình hóa, sự không liên tục này sẽ ảnh hưởng đến khả năng phân tích và xử lý dữ liệu số của mô hình.
Vấn đề token hóa số đơn lẻ
Mặc dù phương pháp token hóa số đơn lẻ rất đơn giản và trực quan, nhưng nó cũng gây ra vấn đề mã token ID không liên tục với các số nhiều chữ số. Ví dụ, số 15 có thể bị phân tách thành các token độc lập “1” và “5”, mỗi token được ánh xạ tới một mã token ID riêng.
Sự phân tách này có thể phá vỡ tính liên tục của thông tin số, làm cho mô hình khó nắm bắt được cấu trúc và mối quan hệ nội tại của các số nhiều chữ số.
Phương pháp xử lý dữ liệu số
• Đối với dữ liệu văn bản: Sử dụng mã hóa UTF-8 để chuyển đổi các ký tự thành chuỗi byte.
• Đối với dữ liệu số: Áp dụng hai chiến lược:
1. Nếu cần giữ nguyên định dạng chính xác của số, bao gồm cả các số 0 quan trọng ở đầu, số được xử lý như một chuỗi và mã hóa bằng UTF-8.
2. Khi thực hiện các phép toán số học hoặc xử lý số liệu quan trọng, số được chuyển đổi thành dạng số (ví dụ, số nguyên) và sau đó thành mảng byte. Phương pháp này đảm bảo khả năng xử lý nhất quán và hiệu quả cho các loại dữ liệu khác nhau.
• Đối với công thức hoặc ký hiệu khoa học: Các biểu thức phức tạp được phân tích và chuỗi hóa thành chuỗi byte, đảm bảo nắm bắt được cấu trúc và nội dung của công thức. Ví dụ, công thức được mã hóa thành mảng byte [69, 61, 109, 99, 94, 50], đại diện cho cấu trúc và các biến của công thức.
• Đối với dữ liệu hình ảnh: Sử dụng phương pháp patch để chia nhỏ hình ảnh thành các mảnh, nâng cao hiệu quả xử lý dữ liệu điểm ảnh dày đặc.
Kiến trúc mô hình BBT-Neutron: Nắm bắt hiệu quả mối quan hệ số liệu và thích nghi đa nhiệm
Kiến trúc mô hình BBT-Neutron bao gồm ba phần chính: Patch Embedding, Patch Self-Attention, và LM Head. Mô hình này có khả năng chuyển đổi chuỗi đầu vào thông qua phân từ nhị phân thành vector không gian cao, từ đó thực hiện các nhiệm vụ như phân loại và hồi quy.
Patch Embedding
Bao gồm hai lớp tuyến tính:
• Lớp đầu tiên chiếu mảnh đầu vào lên không gian cao hơn.
• Lớp thứ hai tinh chỉnh biểu diễn này, tạo ra vector nhúng cuối cùng.
Patch Self-Attention
Cơ chế tự chú ý tại cấp độ patch thực hiện các phép toán chú ý trên mỗi patch, cho phép trao đổi thông tin giữa các patch và bên trong từng patch.
LM Head
Đầu ra có kích thước được định nghĩa bởi Patch Size × 257, trong đó 257 là tổng số giá trị byte từ 0 đến 255, cộng thêm ID điền 256. Thiết kế này giúp mô hình dự đoán độc lập từng patch một cách hiệu quả và chính xác.
Sơ đồ kiến trúc mô hình BBT-Neutron
Ứng dụng trong phân tích dữ liệu va chạm vật lý hạt: Hiệu năng kiến trúc phổ quát đạt mức SOTA trong lĩnh vực chuyên môn
Nhóm phát triển đã công bố kết quả thực nghiệm đầu tiên của kiến trúc phổ quát BBT-Neutron trong bài báo khoa học, áp dụng cho một nhiệm vụ trọng yếu trong vật lý hạt - nhận dạng nguồn gốc của tia phun (Jet Origin Identification, JoI) - và đạt được những đột phá đáng kể.
Nhận dạng nguồn gốc của tia phun (JoI): Một thách thức cốt lõi trong vật lý năng lượng cao
Trong các thí nghiệm vật lý năng lượng cao, nhận dạng nguồn gốc của tia phun là một trong những thách thức lớn nhất. Nhiệm vụ này nhằm phân biệt các tia phun được tạo ra từ các quark khác nhau hoặc từ gluon.
• Trong các vụ va chạm năng lượng cao, quark hoặc gluon sinh ra ngay lập tức hình thành một chùm hạt - chủ yếu là hadron - di chuyển theo cùng một hướng.
• Chùm hạt này, thường được gọi là tia phun, là đối tượng đo lường quan trọng trong các thí nghiệm va chạm.
Việc xác định nguồn gốc của tia phun có vai trò quan trọng đối với nhiều phân tích vật lý, đặc biệt là trong nghiên cứu các boson Higgs, W và Z - các boson này gần như 70% sẽ phân rã trực tiếp thành hai tia phun.
Ngoài ra, tia phun còn là nền tảng để hiểu về sắc động lực học lượng tử (Quantum Chromodynamics - QCD), một lý thuyết mô tả cơ chế tương tác giữa các hạt mang màu như quark và gluon trong hạt nhân nguyên tử.
Thách thức trong nhận dạng tia phun
Các tia phun được sinh ra từ các hạt mang màu khác nhau chỉ có những khác biệt nhỏ trong các đại lượng quan sát được. Điều này làm cho việc nhận dạng chính xác nguồn gốc của tia phun trở nên cực kỳ khó khăn.
Kiến trúc BBT-Neutron đã chứng minh khả năng giải quyết các thách thức này, đạt hiệu năng ngang tầm hoặc vượt qua các phương pháp tiên tiến nhất trong lĩnh vực chuyên môn (SOTA).
Phương pháp phân đoạn từ nhị phân với luồng dữ liệu vật lý hạt xử lý bản vá
Kết quả thí nghiệm cho thấy, nghiên cứu này đạt hiệu năng ngang bằng với các mô hình chuyên ngành tiên tiến nhất (như Particle Transformer và ParticleNet, vốn tích hợp các định luật vật lý chuyên ngành vào thiết kế kiến trúc GNN), đạt mức SOTA trong ngành (Hình 1-3).
Kết quả này xác nhận rằng kiến trúc phổ quát dựa trên seq2seq và mô hình decoder-only có khả năng học các quy luật vật chất và vật lý ngang bằng với các mô hình chuyên ngành.
Quan niệm truyền thống cho rằng seq2seq không phù hợp với việc mô hình hóa các thực tại vật lý có tính liên tục như thời gian, không gian, và năng lượng, mà chỉ phù hợp với việc mô hình hóa các ký hiệu rời rạc như ngôn ngữ của con người. Ngoài ra, cách học từ trái sang phải với tính chất tuyến tính vị trí không phù hợp với các cấu trúc vật lý có tính đối xứng thời gian và không gian. Để mô hình học được các định luật vật lý chuyên ngành, cần tích hợp các cấu trúc chuyên ngành của lĩnh vực đó vào kiến trúc mô hình.
Kết quả nghiên cứu này đã chứng minh giới hạn của quan niệm trên, đồng thời cung cấp một phương pháp hiệu quả để biểu diễn các đại lượng cơ bản trong vật lý như thời gian, không gian và năng lượng. Nó cũng đặt nền tảng cho việc xây dựng một mô hình thống nhất trong các lĩnh vực khoa học chuyên ngành như vật lý và hóa học.
Phân tích tỷ lệ: Khám phá hành vi mới nổi
Bằng cách so sánh hành vi chia tỷ lệ của ParticleNet và Particle Transformer trong nhiệm vụ JoI, bài viết tiến hành phân tích chuyên sâu về hành vi chia tỷ lệ khi kích thước dữ liệu tăng lên.
Các bộ dữ liệu huấn luyện này có phạm vi từ 1 triệu đến 10 triệu sự kiện và kết quả thử nghiệm được đo bằng ba số liệu chính: ma trận nhầm lẫn, hiệu suất gắn thẻ hương vị máy bay phản lực và hiệu suất mô hình điện tích.
Ma trận nhầm lẫn (Ma trận nhầm lẫn) sử dụng ma trận nhầm lẫn 11 chiều M11 để phân loại từng lần tiêm và phân loại vào danh mục tương ứng theo điểm dự đoán cao nhất. Các khối được chéo thành các khối 2×2 và mỗi khối tương ứng với một khối cụ thể. Các loại quark Ma trận nhầm lẫn cung cấp cái nhìn tổng quan toàn diện về hiệu suất phân loại của mô hình, nêu bật các dự đoán đúng và sai trong các danh mục tiêm khác nhau.
Hiệu suất gắn thẻ hương vị phản lực được định nghĩa bằng một nửa tổng các giá trị trong mỗi khối, không phân biệt giữa các tia được tạo ra bởi quark và phản quark.
Tốc độ lật điện tích được định nghĩa là tỷ lệ của các phần tử ngoài đường chéo trong khối với tổng các khối và biểu thị xác suất xác định sai sự phóng điện do quark và phản quark tạo ra.
Nhóm phát triển chỉ ra rằng đã xuất hiện các hành vi mở rộng khác biệt giữa mô hình này và các mô hình chuyên biệt.
Trên đường cong S của BBT-Neutron, các ngưỡng dữ liệu quan trọng, đặc biệt là dữ liệu của Tỷ lệ đảo chiều điện tích (Charge Flip Rate), đã cho thấy sự biến đổi hiệu suất đột ngột, biểu hiện rõ rệt hiện tượng nổi bật (Model Emergence). Tuy nhiên, hiện tượng này không được quan sát thấy trong ParticleNet hay Particle Transformer.
Nguyên nhân có thể là do các mô hình chuyên biệt đã tích hợp các đặc điểm cấu trúc thuộc lĩnh vực cụ thể, sử dụng kiến trúc thiết kế riêng để mô tả sự tương tác và phân loại hạt, điều này có thể khiến hiệu suất nhanh chóng đạt ngưỡng bão hòa khi quy mô dữ liệu tăng.
Ngược lại, mô hình kiến trúc chung trong nghiên cứu này sử dụng cách biểu diễn dữ liệu thống nhất để xử lý mọi cấu trúc vật lý. Các mô hình chuyên biệt đạt tính bất biến hoán vị (permutative invariance) thông qua việc loại bỏ mã hóa vị trí hoặc các thao tác liên quan, trong khi BBT-Neutron không dựa vào tính bất biến hoán vị mà áp dụng đầu vào tuần tự từ trái sang phải, tương đồng với quy trình seq2seq trong các mô hình ngôn ngữ.
Dù phương pháp này đòi hỏi tập dữ liệu lớn hơn để suy luận, nhưng một khi vượt qua ngưỡng dữ liệu quan trọng, mô hình có thể đạt được bước nhảy vọt đáng kể về hiệu suất. Điều này cho thấy, dù không tích hợp rõ ràng tính bất biến hoán vị trong thiết kế kiến trúc như các mô hình chuyên biệt, BBT-Neutron vẫn có thể học được tính đối xứng không gian thông qua việc huấn luyện trên một lượng dữ liệu đủ lớn.
Hiểu một cách đơn giản, khi quy mô dữ liệu tăng dần, mô hình này đã có sự chuyển đổi hiệu suất rõ rệt. Phát hiện này xác nhận khả năng mở rộng của mô hình chung trong các nhiệm vụ tính toán khoa học quy mô lớn, cho thấy mô hình này có tiềm năng trở thành nền tảng tính toán khoa học đa lĩnh vực.
Nghiên cứu này đánh dấu tiềm năng to lớn của các mô hình lớn trong xử lý dữ liệu đa phương thức và nhiệm vụ tính toán khoa học. Với sự kết hợp sâu sắc giữa công nghệ trí tuệ nhân tạo và các thiết bị khoa học lớn, trong tương lai, có thể đẩy nhanh việc triển khai các dự án nghiên cứu tiên phong như máy gia tốc CEPC của Trung Quốc.
Thành viên nhóm CEPC, ông Nguyễn Mạn Kỳ, từng nhận xét: *“Công nghệ trí tuệ nhân tạo sẽ hỗ trợ thiết kế và phát triển các thiết bị khoa học lớn, giúp tăng cường đáng kể khả năng khám phá khoa học của chúng, từ đó hỗ trợ tốt hơn trong việc khám phá các bí ẩn của thế giới và mở rộng ranh giới tri thức của nhân loại.
Ngược lại, thông qua việc tổng hợp và so sánh sự khác biệt hiệu suất AI được quan sát trong các vấn đề khoa học cụ thể, chúng ta cũng có thể hiểu sâu hơn về bản thân công nghệ AI, từ đó thúc đẩy sự phát triển của công nghệ này.”*
Quá trình phát triển mô hình BBT:
- Năm 2022: Ra mắt BBT-1, mô hình ngôn ngữ tài chính tiền huấn luyện với 1 tỷ tham số;
- Năm 2023: Ra mắt BBT-2, mô hình ngôn ngữ lớn đa năng với 12 tỷ tham số;
- Năm 2024: Ra mắt BBT-Neutron, mô hình ngôn ngữ lớn khoa học với 1,4 tỷ tham số, đạt được huấn luyện tiền xử lý thống nhất trên dữ liệu văn bản, số liệu và hình ảnh.
GitHub - supersymmetry-technologies/bbt-neutron
Contribute to supersymmetry-technologies/bbt-neutron development by creating an account on GitHub.
github.com

BÀI MỚI ĐANG THẢO LUẬN