4o-mini chỉ có 8B, o1 cũng chỉ 300B, tài liệu của Microsoft vô tình tiết lộ bí mật cốt lõi của GPT.
Khi Nvidia phát hành B200 vào đầu năm 2024, thông tin cho thấy mô hình GPT-4 sử dụng kiến trúc 1,8 nghìn tỷ tham số MoE (Mixture of Experts). Tuy nhiên, theo số liệu của Microsoft, con số chính xác hơn là 1,76 nghìn tỷ tham số.

Có vẻ như Microsoft lại vô tình làm rò rỉ bí mật OpenAI? ? Trong một tài liệu của Microsoft có đoạn viết rõ ràng:
"o1-preview khoảng 300B thông số, GPT-4o khoảng 200B, GPT-4o-mini khoảng 8B..."
Ngoài ra, trong bài nghiên cứu cũng đề cập đến các mô hình dòng mini của OpenAI và Claude 3.5 Sonnet, kèm theo số lượng tham số. Dưới đây là tóm tắt:
• o1-preview: khoảng 300 tỷ tham số
• o1-mini: khoảng 100 tỷ tham số
• GPT-4o: khoảng 200 tỷ tham số
• GPT-4o-mini: khoảng 8 tỷ tham số
• Claude 3.5 Sonnet phiên bản ngày 22/10/2024: khoảng 175 tỷ tham số
• Mô hình của Microsoft, Phi-3-7B, không cần ước lượng, chính xác là 7 tỷ tham số.
Mặc dù có tuyên bố từ chối trách nhiệm ở cuối bài viết: "Con số chính xác chưa được công bố và hầu hết các con số ở đây chỉ là ước tính."
Nhưng vẫn có nhiều người cảm thấy mọi chuyện không hề đơn giản như vậy.
Ví dụ: tại sao không bao gồm các ước tính tham số của mô hình Google Gemini? Có lẽ họ vẫn còn niềm tin vào con số mình đưa ra.
Một số người cũng tin rằng hầu hết các mẫu máy đều chạy trên GPU NVIDIA nên có thể ước tính chúng bằng tốc độ tạo mã thông báo.
Chỉ có model Google chạy trên TPU nên khó ước tính.
Và đây không phải là lần đầu tiên Microsoft làm điều này.
Vào tháng 10 năm 2023, Microsoft “vô tình” để lộ thông số 20B của mẫu GPT-3.5-Turbo trong một bài báo và xóa thông tin này trong các phiên bản tiếp theo của bài báo.
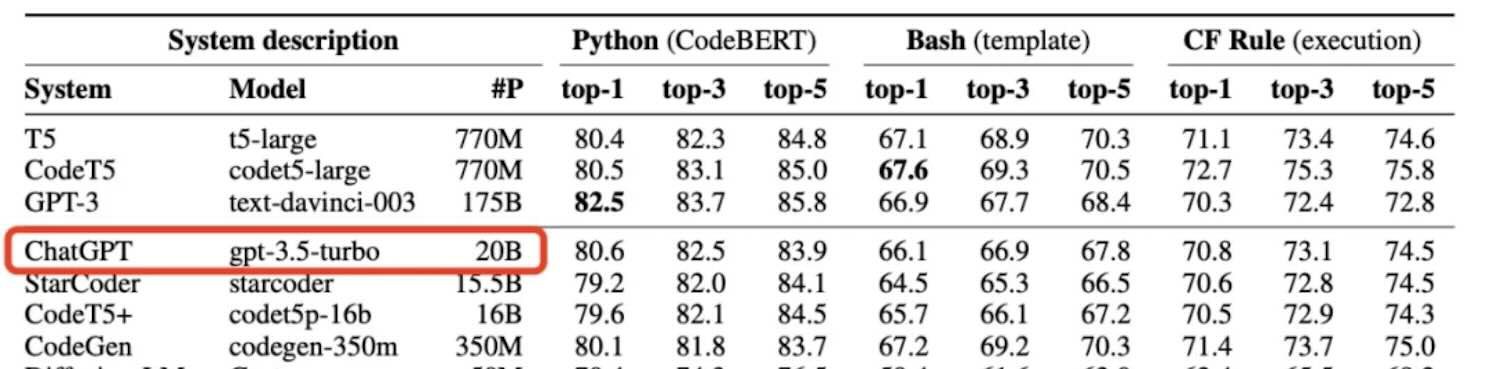
Bài nghiên cứu của Microsoft thực chất giới thiệu một tiêu chuẩn benchmark mới liên quan đến lĩnh vực y học có tên là MEDEC.

• MEDEC được thiết kế để đánh giá khả năng áp dụng của các mô hình ngôn ngữ lớn (LLM) trong các tác vụ liên quan đến y tế. Đây là một tiêu chuẩn đo lường hiệu suất trong lĩnh vực khá chuyên biệt và mang tính ứng dụng cao.
• Bài nghiên cứu đã được công bố vào ngày 26 tháng 12, nhưng vì đây là một chủ đề trong lĩnh vực hẹp (y học), nên không thu hút được sự chú ý ngay lập tức.
• Sau kỳ nghỉ Tết Dương Lịch, bài viết mới được các “thám tử internet” phát hiện và chia sẻ rộng rãi hơn.
Sự kiện này thu hút nhiều sự chú ý, không chỉ vì tiêu chuẩn MEDEC, mà còn vì các thông tin được tiết lộ trong bài nghiên cứu liên quan đến các mô hình AI như GPT và Claude. Những chi tiết này cung cấp cái nhìn sâu sắc hơn về những tiến bộ và chiến lược của Microsoft trong lĩnh vực AI, đặc biệt là ứng dụng y tế.
Nghiên cứxuất phát từ một khảo sát của các tổ chức y tế Hoa Kỳ, cho thấy 1/5 số bệnh nhân cho biết đã tìm thấy sai sót khi đọc ghi chú lâm sàng và 40% tin rằng những sai sót này có thể ảnh hưởng đến việc chăm sóc của họ.
Mặt khác, LLM (Mô hình ngôn ngữ lớn) ngày càng được sử dụng nhiều cho các nhiệm vụ tài liệu y tế (chẳng hạn như tạo ra các phương pháp chẩn đoán và điều trị).
Vì vậy, lần này MEDEC có hai nhiệm vụ. Một là xác định và tìm ra những sai sót trong ghi chú lâm sàng; hai là sửa chúng.
Vì mục đích của nghiên cứu, bộ dữ liệu MEDEC chứa 3848 văn bản lâm sàng, bao gồm 488 ghi chú lâm sàng từ ba hệ thống bệnh viện Hoa Kỳ mà trước đây chưa từng có LLM nào nhìn thấy.
Nó bao gồm năm loại lỗi (chẩn đoán, quản lý, điều trị, dùng thuốc và tác nhân gây bệnh) được lựa chọn bằng cách phân tích các loại câu hỏi phổ biến nhất trong các bài kiểm tra của hội đồng y tế và chú thích lỗi của 8 chuyên gia y tế.
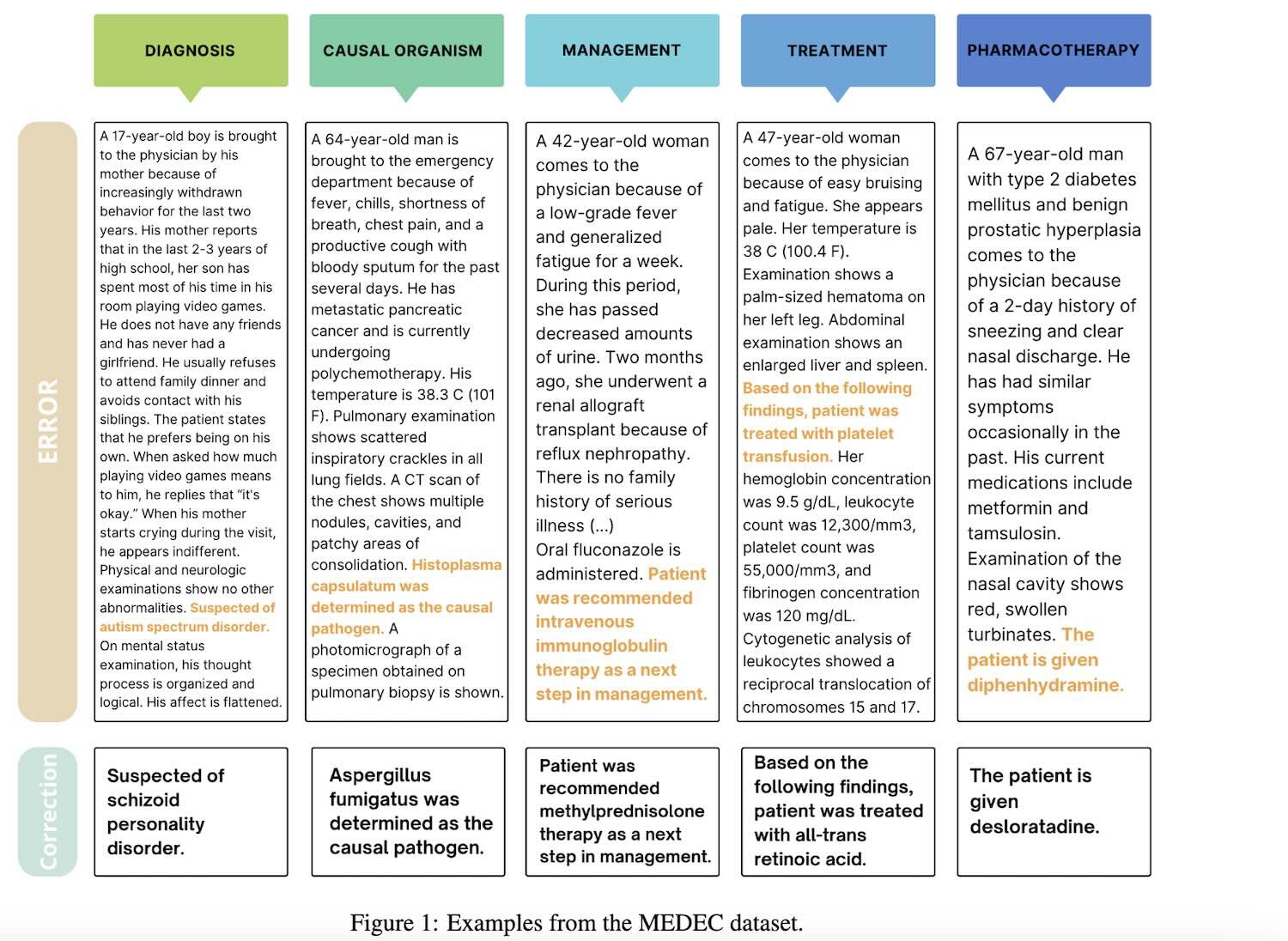
Sự rò rỉ thông số đã xảy ra trong giai đoạn thực nghiệm.
Theo thiết kế thí nghiệm, các nhà nghiên cứu sẽ lựa chọn các mô hình lớn và mô hình nhỏ phổ biến gần đây để tham gia vào việc nhận diện và sửa lỗi các ghi chú lâm sàng.
Tuy nhiên, khi giới thiệu các mô hình cuối cùng được chọn, các thông số mô hình và thời gian phát hành đã vô tình bị công khai.

Bỏ qua các bước trung gian, nghiên cứu này kết luận rằng Claude 3.5 Sonnet vượt trội hơn các phương pháp LLM khác trong việc phát hiện lỗi, với điểm số đạt 70.16. Đứng thứ hai là o1-mini.
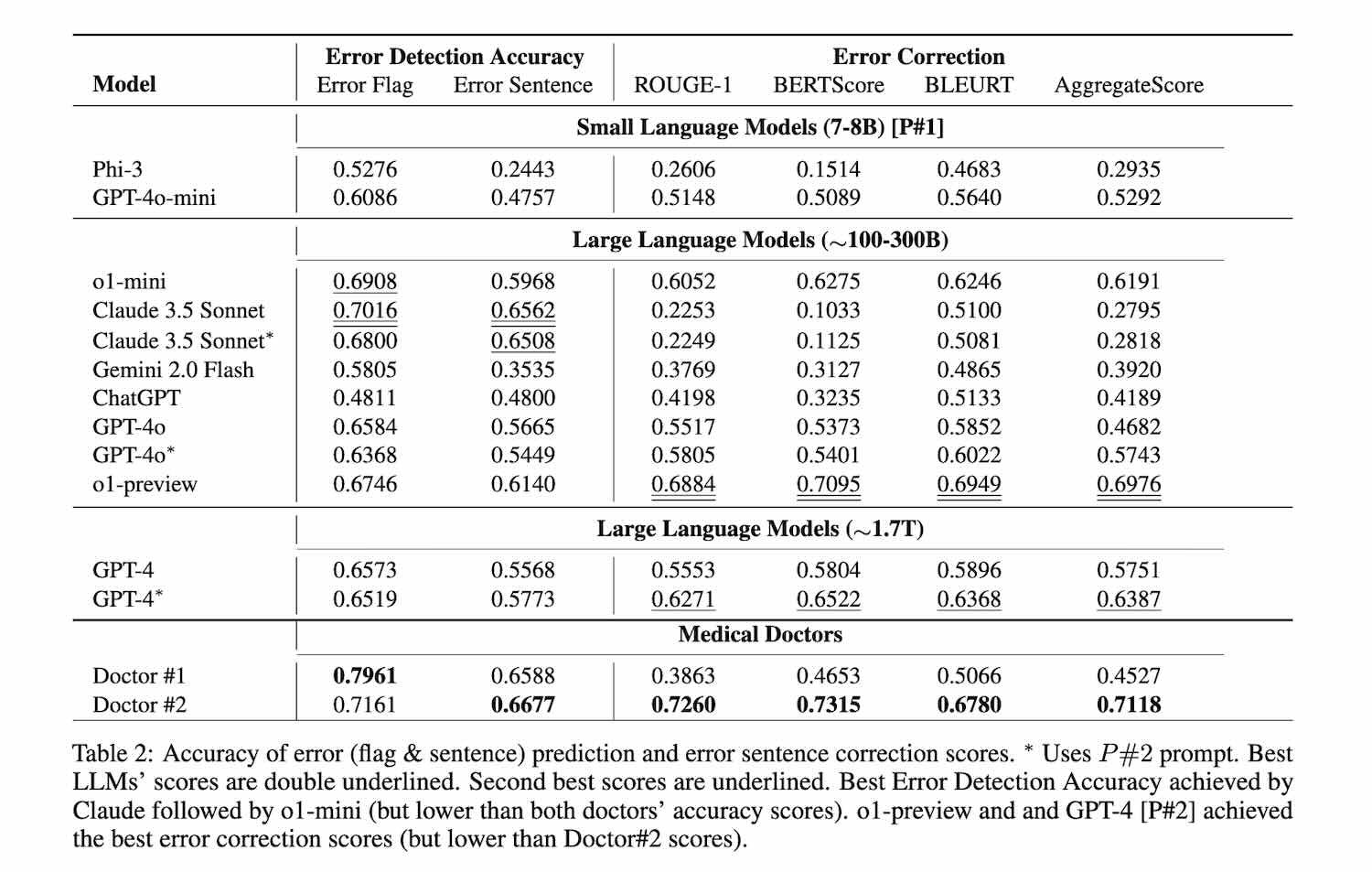
Mỗi lần kiến trúc và thông số mô hình liên quan đến ChatGPT bị rò rỉ đều gây náo động, và lần này cũng không ngoại lệ.
Vào tháng 10 năm 2023, khi tờ báo của Microsoft khẳng định GPT-3.5-Turbo chỉ có thông số 20B, một số người đã than thở: Thảo nào OpenAI lại lo lắng về các mô hình nguồn mở đến vậy.
Vào tháng 3 năm 2024, NVIDIA xác nhận rằng GPT-4 là 1,8T MoE và khi 2.000 chiếc B200 có thể được huấn luyện trong vòng 90 ngày, mọi người đều cảm thấy rằng MoE đã, đang và sẽ vẫn là một xu hướng trong kiến trúc mô hình lớn.
Lần này, dựa trên dữ liệu ước tính của Microsoft, cư dân mạng có một số mối quan tâm chính:
Nếu Claude 3.5 Sonnet thực sự nhỏ hơn GPT-4o thì nhóm Anthropic có lợi thế về mặt kỹ thuật. Và đừng tin rằng GPT-4o-mini chỉ có 8B nhỏ như vậy.
Một số người trước đây đã tính toán dựa trên chi phí suy luận rằng giá của 4o-mini là 40% của 3,5-turbo. Nếu con số 20B của 3,5-turbo là chính xác thì 4o-mini chính xác là khoảng 8B. Tuy nhiên, 8B ở đây cũng đề cập đến các tham số kích hoạt của mô hình MoE.
Cuối cùng thì OpenAI có lẽ sẽ không công bố con số chính xác.
Altman trước đây đã đưa ra các nghị quyết cho Năm mới cho năm 2024 và danh sách cuối cùng cũng bao gồm “nguồn mở”. Ở phiên bản mới nhất năm 2025, mã nguồn mở đã bị loại bỏ.
"o1-preview khoảng 300B thông số, GPT-4o khoảng 200B, GPT-4o-mini khoảng 8B..."
Ngoài ra, trong bài nghiên cứu cũng đề cập đến các mô hình dòng mini của OpenAI và Claude 3.5 Sonnet, kèm theo số lượng tham số. Dưới đây là tóm tắt:
• o1-preview: khoảng 300 tỷ tham số
• o1-mini: khoảng 100 tỷ tham số
• GPT-4o: khoảng 200 tỷ tham số
• GPT-4o-mini: khoảng 8 tỷ tham số
• Claude 3.5 Sonnet phiên bản ngày 22/10/2024: khoảng 175 tỷ tham số
• Mô hình của Microsoft, Phi-3-7B, không cần ước lượng, chính xác là 7 tỷ tham số.
Mặc dù có tuyên bố từ chối trách nhiệm ở cuối bài viết: "Con số chính xác chưa được công bố và hầu hết các con số ở đây chỉ là ước tính."
Nhưng vẫn có nhiều người cảm thấy mọi chuyện không hề đơn giản như vậy.
Ví dụ: tại sao không bao gồm các ước tính tham số của mô hình Google Gemini? Có lẽ họ vẫn còn niềm tin vào con số mình đưa ra.
Một số người cũng tin rằng hầu hết các mẫu máy đều chạy trên GPU NVIDIA nên có thể ước tính chúng bằng tốc độ tạo mã thông báo.
Chỉ có model Google chạy trên TPU nên khó ước tính.
Và đây không phải là lần đầu tiên Microsoft làm điều này.
Vào tháng 10 năm 2023, Microsoft “vô tình” để lộ thông số 20B của mẫu GPT-3.5-Turbo trong một bài báo và xóa thông tin này trong các phiên bản tiếp theo của bài báo.
Bài nghiên cứu của Microsoft thực chất giới thiệu một tiêu chuẩn benchmark mới liên quan đến lĩnh vực y học có tên là MEDEC.
• Bài nghiên cứu đã được công bố vào ngày 26 tháng 12, nhưng vì đây là một chủ đề trong lĩnh vực hẹp (y học), nên không thu hút được sự chú ý ngay lập tức.
• Sau kỳ nghỉ Tết Dương Lịch, bài viết mới được các “thám tử internet” phát hiện và chia sẻ rộng rãi hơn.
Sự kiện này thu hút nhiều sự chú ý, không chỉ vì tiêu chuẩn MEDEC, mà còn vì các thông tin được tiết lộ trong bài nghiên cứu liên quan đến các mô hình AI như GPT và Claude. Những chi tiết này cung cấp cái nhìn sâu sắc hơn về những tiến bộ và chiến lược của Microsoft trong lĩnh vực AI, đặc biệt là ứng dụng y tế.
Nghiên cứxuất phát từ một khảo sát của các tổ chức y tế Hoa Kỳ, cho thấy 1/5 số bệnh nhân cho biết đã tìm thấy sai sót khi đọc ghi chú lâm sàng và 40% tin rằng những sai sót này có thể ảnh hưởng đến việc chăm sóc của họ.
Mặt khác, LLM (Mô hình ngôn ngữ lớn) ngày càng được sử dụng nhiều cho các nhiệm vụ tài liệu y tế (chẳng hạn như tạo ra các phương pháp chẩn đoán và điều trị).
Vì vậy, lần này MEDEC có hai nhiệm vụ. Một là xác định và tìm ra những sai sót trong ghi chú lâm sàng; hai là sửa chúng.
Vì mục đích của nghiên cứu, bộ dữ liệu MEDEC chứa 3848 văn bản lâm sàng, bao gồm 488 ghi chú lâm sàng từ ba hệ thống bệnh viện Hoa Kỳ mà trước đây chưa từng có LLM nào nhìn thấy.
Nó bao gồm năm loại lỗi (chẩn đoán, quản lý, điều trị, dùng thuốc và tác nhân gây bệnh) được lựa chọn bằng cách phân tích các loại câu hỏi phổ biến nhất trong các bài kiểm tra của hội đồng y tế và chú thích lỗi của 8 chuyên gia y tế.
Sự rò rỉ thông số đã xảy ra trong giai đoạn thực nghiệm.
Theo thiết kế thí nghiệm, các nhà nghiên cứu sẽ lựa chọn các mô hình lớn và mô hình nhỏ phổ biến gần đây để tham gia vào việc nhận diện và sửa lỗi các ghi chú lâm sàng.
Tuy nhiên, khi giới thiệu các mô hình cuối cùng được chọn, các thông số mô hình và thời gian phát hành đã vô tình bị công khai.
Mỗi lần kiến trúc và thông số mô hình liên quan đến ChatGPT bị rò rỉ đều gây náo động, và lần này cũng không ngoại lệ.
Vào tháng 10 năm 2023, khi tờ báo của Microsoft khẳng định GPT-3.5-Turbo chỉ có thông số 20B, một số người đã than thở: Thảo nào OpenAI lại lo lắng về các mô hình nguồn mở đến vậy.
Vào tháng 3 năm 2024, NVIDIA xác nhận rằng GPT-4 là 1,8T MoE và khi 2.000 chiếc B200 có thể được huấn luyện trong vòng 90 ngày, mọi người đều cảm thấy rằng MoE đã, đang và sẽ vẫn là một xu hướng trong kiến trúc mô hình lớn.
Lần này, dựa trên dữ liệu ước tính của Microsoft, cư dân mạng có một số mối quan tâm chính:
Nếu Claude 3.5 Sonnet thực sự nhỏ hơn GPT-4o thì nhóm Anthropic có lợi thế về mặt kỹ thuật. Và đừng tin rằng GPT-4o-mini chỉ có 8B nhỏ như vậy.
Một số người trước đây đã tính toán dựa trên chi phí suy luận rằng giá của 4o-mini là 40% của 3,5-turbo. Nếu con số 20B của 3,5-turbo là chính xác thì 4o-mini chính xác là khoảng 8B. Tuy nhiên, 8B ở đây cũng đề cập đến các tham số kích hoạt của mô hình MoE.
Cuối cùng thì OpenAI có lẽ sẽ không công bố con số chính xác.
Altman trước đây đã đưa ra các nghị quyết cho Năm mới cho năm 2024 và danh sách cuối cùng cũng bao gồm “nguồn mở”. Ở phiên bản mới nhất năm 2025, mã nguồn mở đã bị loại bỏ.

BÀI MỚI ĐANG THẢO LUẬN
