Qwen3-Thinking-2507: Siêu mô hình suy luận của Alibaba, đột phá ngang ngửa Gemini‑2.5 Pro và O4‑mini
Alibaba tuyên bố ra mắt phiên bản nâng cấp “Thinking” của Qwen3-235B-A22B – mã cụ thể là Qwen3-235B-A22B-Thinking-2507. Đây là mô hình reasoning chuyên biệt, mở nguồn (Apache 2.0), được tối ưu sâu về hiệu năng suy luận và xếp hạng ngang hàng hoặc vượt qua các đối thủ dẫn đầu như OpenAI O4‑mini và Google Gemini‑2.5 Pro .
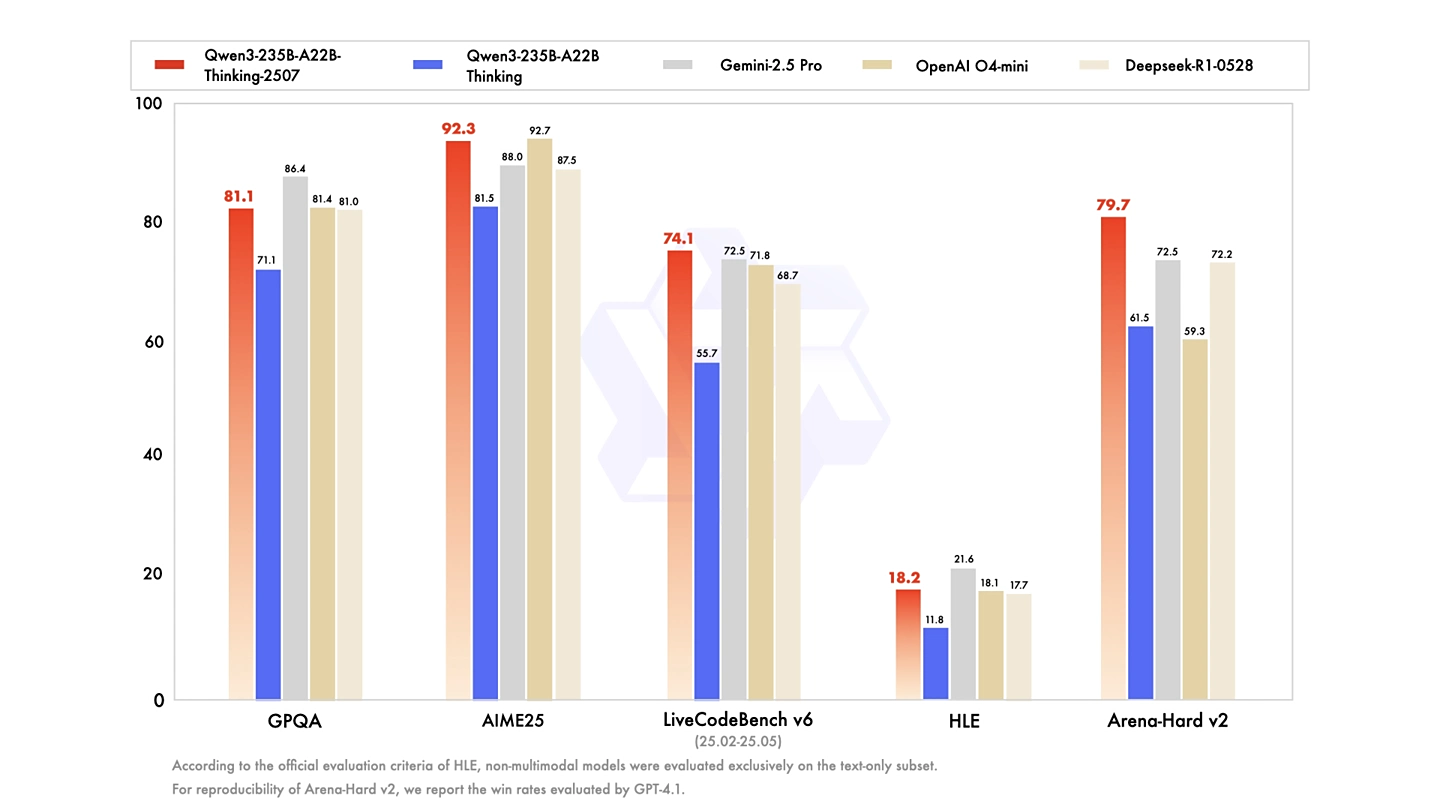
Ngay tại benchmark AIME25, Qwen3‑Thinking‑2507 giành điểm 92.3, xếp sát OpenAI O4‑mini (92.7) và vượt Gemini‑2.5 Pro (88.0) . Trên LiveCodeBench v6 dành cho lập trình, mô hình đạt 74.1, cao hơn Gemini‑2.5 Pro (72.5) và O4‑mini (71.8) , đồng thời điểm CFEval lên đến 2134, dẫn đầu mọi đối thủ .
Không chỉ mạnh về lập trình, Qwen3‑Thinking‑2507 cải thiện đáng kể độ tổng quát: điểm GPQA đạt 81.1, tương đương DeepSeek‑R1‑0528 (81.0); trên benchmark khó hơn SuperGPQA ghi nhận 64.9, vượt trội Gemini‑2.5 Pro (62.3) . Trên chỉ số alignment Arena‑Hard v2, điểm số 79.7, đặt Qwen đứng đầu các model reasoning mở so với DeepSeek‑R1 và các model khác .
Ngoài ra, các bài đánh giá chỉ ra Qwen3‑Thinking‑2507 có khả năng xử lý ngữ cảnh siêu dài đến 256 K token, tức hơn 300 trang A4, giúp xử lý các cuộc hội thoại hoặc tài liệu dài mà các model khác không thể .

Mô hình mới không phải đơn thuần cải tiến: team Qwen tách riêng hoàn toàn hai chế độ suy luận (Thinking) và tương tác nhanh (Instruct), khiến mỗi model có tối ưu riêng biệt và không cần chuyển thủ công khi dùng . Tổng cộng Qwen3 gồm mô hình dense và MoE, với 235 tỷ tham số, trong đó chỉ 22 tỷ kích hoạt mỗi lần inference (activated experts) giúp tiết kiệm tài nguyên nhưng vẫn hiệu quả cao .
Đối thủ đáng gờm là AM‑Thinking‑v1 (32 B), được xây dựng trên Qwen2.5 và đạt điểm rất cao như AIME25 74.4 hay LiveCodeBench 70.3. Tuy vậy, dù là model mid-size, điểm số của AM vẫn không bằng Qwen3‑Thinking‑2507 ở scale lớn hơn .
Ngoài ra, mô hình Skywork‑OR1 (32 B) do nhóm khác phát triển áp dụng reinforcement learning cho reasoning dài, cũng có cú nhảy lớn khi tăng điểm AIME25 từ ~57.8 lên ~72.8, thậm chí vượt cả Qwen3‑32B trong một số bài test .
Qwen3‑235B‑A22B‑Thinking‑2507 là một kỳ tích mới của AI reasoning mở nguồn. Nó không chỉ vượt qua hoặc tiệm cận các model thương mại hàng đầu như Gemini‑2.5 Pro và O4‑mini trên các benchmark quan trọng mà còn có:
Thông tin bạn tham khảo thêm tại đây


 www.modelscope.cn
www.modelscope.cn
Ngay tại benchmark AIME25, Qwen3‑Thinking‑2507 giành điểm 92.3, xếp sát OpenAI O4‑mini (92.7) và vượt Gemini‑2.5 Pro (88.0) . Trên LiveCodeBench v6 dành cho lập trình, mô hình đạt 74.1, cao hơn Gemini‑2.5 Pro (72.5) và O4‑mini (71.8) , đồng thời điểm CFEval lên đến 2134, dẫn đầu mọi đối thủ .
Không chỉ mạnh về lập trình, Qwen3‑Thinking‑2507 cải thiện đáng kể độ tổng quát: điểm GPQA đạt 81.1, tương đương DeepSeek‑R1‑0528 (81.0); trên benchmark khó hơn SuperGPQA ghi nhận 64.9, vượt trội Gemini‑2.5 Pro (62.3) . Trên chỉ số alignment Arena‑Hard v2, điểm số 79.7, đặt Qwen đứng đầu các model reasoning mở so với DeepSeek‑R1 và các model khác .
Ngoài ra, các bài đánh giá chỉ ra Qwen3‑Thinking‑2507 có khả năng xử lý ngữ cảnh siêu dài đến 256 K token, tức hơn 300 trang A4, giúp xử lý các cuộc hội thoại hoặc tài liệu dài mà các model khác không thể .
So sánh với các mô hình khác trong nghiên cứu
Đối thủ đáng gờm là AM‑Thinking‑v1 (32 B), được xây dựng trên Qwen2.5 và đạt điểm rất cao như AIME25 74.4 hay LiveCodeBench 70.3. Tuy vậy, dù là model mid-size, điểm số của AM vẫn không bằng Qwen3‑Thinking‑2507 ở scale lớn hơn .
Ngoài ra, mô hình Skywork‑OR1 (32 B) do nhóm khác phát triển áp dụng reinforcement learning cho reasoning dài, cũng có cú nhảy lớn khi tăng điểm AIME25 từ ~57.8 lên ~72.8, thậm chí vượt cả Qwen3‑32B trong một số bài test .
Qwen3‑235B‑A22B‑Thinking‑2507 là một kỳ tích mới của AI reasoning mở nguồn. Nó không chỉ vượt qua hoặc tiệm cận các model thương mại hàng đầu như Gemini‑2.5 Pro và O4‑mini trên các benchmark quan trọng mà còn có:
- Khả năng xử lý ngữ cảnh cực dài (256K token)
- Mô hình tư duy rõ ràng, suy luận có chain-of-thought tự điều khiển
- Hỗ trợ mã mở hoàn toàn theo Apache 2.0, cộng đồng có thể sử dụng thương mại
Thông tin bạn tham khảo thêm tại đây
Qwen/Qwen3-235B-A22B-Thinking-2507 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
通义千问3-235B-A22B-Thinking-2507
ModelScope——汇聚各领域先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。在这里,共建模型开源社区,发现、学习、定制和分享心仪的模型。
www.modelscope.cn
BÀI MỚI ĐANG THẢO LUẬN