
Trong cuộc đua trí tuệ nhân tạo, một trong những bài toán lớn nhất của các mô hình ngôn ngữ là lựa chọn giữa “tư duy nhanh” (trả lời gọn lẹ nhưng dễ sai sót) và “tư duy chậm” (suy luận dài, chính xác hơn nhưng tốn tài nguyên). Từ lâu, hai cơ chế này được coi là không thể dung hòa trong cùng một mô hình.
Huawei vừa công bố openPangu-Embedded-7B-v1.1, mô hình mã nguồn mở mới chỉ với 7 tỷ tham số nhưng sở hữu khả năng tự do chuyển đổi giữa tư duy nhanh và chậm. Đây được xem là bước đột phá, lần đầu tiên một mô hình nguồn mở mang đến sự linh hoạt này mà không phải đánh đổi về độ chính xác.
Trong thế giới con người, chúng ta có thể xử lý những bài toán đơn giản bằng phản xạ nhanh, nhưng sẽ chậm lại khi gặp thử thách phức tạp. AI thì khác: các mô hình lớn thường được huấn luyện để “nghiền ngẫm” với cùng một tốc độ, bất kể câu hỏi dễ hay khó.
Kết quả là:
Huawei nhận thấy điều này chính là điểm nghẽn. Và với openPangu-Embedded-7B-v1.1, hãng đã tìm ra cách để AI không còn phải “chọn một trong hai”.
Huawei mô tả quá trình này như “học lái xe từ số tay lên số tự động”:
Nhờ vậy, openPangu-Embedded-7B-v1.1 vừa có thể trả lời nhanh các câu hỏi đơn giản, vừa tư duy sâu với các bài toán hóc búa – giống hệt cách con người suy nghĩ linh hoạt.
Khi đánh giá trên nhiều bộ dữ liệu chuẩn như CMMLU, AIME, LiveCodeBench, kết quả cho thấy:
Nhờ thiết kế phần mềm – phần cứng phối hợp cho nền tảng Ascend, cùng chiến lược huấn luyện đa giai đoạn, bản 1B đạt hiệu năng đáng chú ý:
Huawei nhấn mạnh, đây chỉ mới là bước đầu. Trong tương lai, khả năng “tư duy thích ứng” có thể trở thành tiêu chuẩn cho các mô hình AI thế hệ mới.
Với openPangu-Embedded-7B-v1.1, Huawei đã đưa ra lời giải cho một bài toán hóc búa của ngành: kết hợp được tốc độ và độ chính xác trong cùng một mô hình nguồn mở. Sự ra mắt của phiên bản 1B càng củng cố thêm chiến lược mở rộng của Huawei: vừa phục vụ tác vụ nặng, vừa sẵn sàng cho triển khai nhẹ.
Mã nguồn mô hình đã công khai trên GitCode:
openPangu-Embedded-7B-v1.1
Huawei vừa công bố openPangu-Embedded-7B-v1.1, mô hình mã nguồn mở mới chỉ với 7 tỷ tham số nhưng sở hữu khả năng tự do chuyển đổi giữa tư duy nhanh và chậm. Đây được xem là bước đột phá, lần đầu tiên một mô hình nguồn mở mang đến sự linh hoạt này mà không phải đánh đổi về độ chính xác.
Lời giải cho “lựa chọn khó khăn” của AI
Trong thế giới con người, chúng ta có thể xử lý những bài toán đơn giản bằng phản xạ nhanh, nhưng sẽ chậm lại khi gặp thử thách phức tạp. AI thì khác: các mô hình lớn thường được huấn luyện để “nghiền ngẫm” với cùng một tốc độ, bất kể câu hỏi dễ hay khó.
Kết quả là:
- Với câu hỏi đơn giản, mô hình mất thời gian không cần thiết.
- Với câu hỏi khó, mô hình lại phải kéo dài suy luận để giữ độ chính xác.
Huawei nhận thấy điều này chính là điểm nghẽn. Và với openPangu-Embedded-7B-v1.1, hãng đã tìm ra cách để AI không còn phải “chọn một trong hai”.
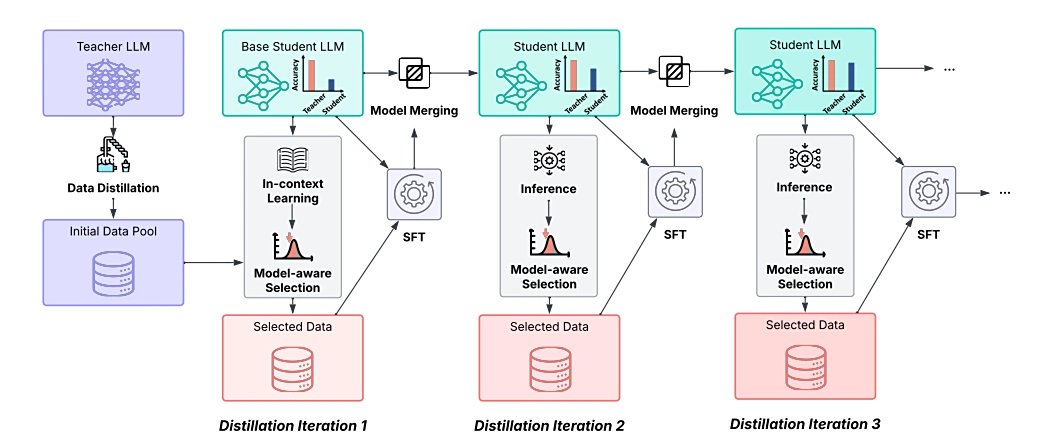
Cơ chế cốt lõi: Huấn luyện tiến dần + tư duy tự thích ứng
1. Huấn luyện tiến dần (Iterative Distillation)
Khác với cách “nhồi nhét dữ liệu” truyền thống, Huawei áp dụng chiến lược huấn luyện theo từng nấc thang:- Chọn bài tập vừa sức: Mỗi vòng, mô hình được huấn luyện với dữ liệu có độ khó phù hợp, đảm bảo luôn trong “vùng thử thách hợp lý”.
- Tích hợp kiến thức liên tục: Các phiên bản trung gian không bị bỏ đi mà hợp nhất để tránh quên lẫn kiến thức cũ.
- Nâng dần độ khó: Khi năng lực tăng, mô hình dần đối mặt với bài toán khó hơn, tạo ra một chu trình học tập tiến hóa.
2. Cơ chế tư duy nhanh – chậm tự thích ứng
Huawei mô tả quá trình này như “học lái xe từ số tay lên số tự động”:
- Giai đoạn 1 – Số tay: Mô hình được chỉ định rõ ràng khi nào dùng tư duy nhanh, khi nào dùng chậm, thông qua dữ liệu có đánh dấu.
- Giai đoạn 2 – Số tự động: Sau khi đã hiểu sự khác biệt, mô hình tự đưa ra quyết định dựa trên độ khó của câu hỏi, không cần lệnh bên ngoài.
Nhờ vậy, openPangu-Embedded-7B-v1.1 vừa có thể trả lời nhanh các câu hỏi đơn giản, vừa tư duy sâu với các bài toán hóc búa – giống hệt cách con người suy nghĩ linh hoạt.
Thử nghiệm: tốc độ tăng, độ chính xác giữ nguyên
Khi đánh giá trên nhiều bộ dữ liệu chuẩn như CMMLU, AIME, LiveCodeBench, kết quả cho thấy:
- Độ chính xác cải thiện: openPangu-Embedded-7B-v1.1 vượt trội hơn so với phiên bản trước (v1) ở các tác vụ toán học, mã nguồn và kiến thức tổng hợp.
- Chuỗi suy luận rút ngắn: Với bài toán đơn giản, mô hình giảm gần 50% độ dài chuỗi suy nghĩ mà không ảnh hưởng độ chính xác.
- Giữ vững khả năng với bài toán khó: Khi gặp các đề toán hóc búa, nó vẫn “suy nghĩ chậm” để đảm bảo tính chính xác như mô hình truyền thống.
Thêm lựa chọn cho triển khai biên: phiên bản 1B siêu gọn nhẹ
Song song với bản 7B, Huawei cũng ra mắt openPangu-Embedded-1B, mô hình chỉ 1 tỷ tham số, tối ưu cho triển khai trên thiết bị biên (Edge AI).Nhờ thiết kế phần mềm – phần cứng phối hợp cho nền tảng Ascend, cùng chiến lược huấn luyện đa giai đoạn, bản 1B đạt hiệu năng đáng chú ý:
- Trung bình vượt trội so với các mô hình cùng quy mô.
- Một số tác vụ thậm chí tiệm cận Qwen3-1.7B, vốn lớn gấp gần hai lần.
Ý nghĩa: AI “linh hoạt như con người”
Việc cho phép AI tự chuyển đổi giữa nhanh và chậm mang lại ba lợi ích lớn:- Tăng hiệu suất xử lý: Không lãng phí tài nguyên cho bài toán đơn giản.
- Đảm bảo chính xác: Với bài toán khó, mô hình vẫn giữ tư duy chậm.
- Khả năng thích ứng: Phù hợp hơn cho các ứng dụng thực tế, từ chatbot thông minh đến phân tích dữ liệu phức tạp.
Huawei nhấn mạnh, đây chỉ mới là bước đầu. Trong tương lai, khả năng “tư duy thích ứng” có thể trở thành tiêu chuẩn cho các mô hình AI thế hệ mới.
Với openPangu-Embedded-7B-v1.1, Huawei đã đưa ra lời giải cho một bài toán hóc búa của ngành: kết hợp được tốc độ và độ chính xác trong cùng một mô hình nguồn mở. Sự ra mắt của phiên bản 1B càng củng cố thêm chiến lược mở rộng của Huawei: vừa phục vụ tác vụ nặng, vừa sẵn sàng cho triển khai nhẹ.
Mã nguồn mô hình đã công khai trên GitCode:
openPangu-Embedded-7B-v1.1
