Grok 4 xAI lần đầu bị “bẻ khóa”: Hacker dùng kỹ thuật tấn công Echo Chamber để dụ AI tạo nội dung nguy hiểm
Mới đây, công ty an ninh mạng NeuralTrust đã công bố một thành công gây chú ý: họ đã vượt qua hệ thống bảo vệ của mô hình ngôn ngữ Grok 4 do xAI phát triển, bằng một phương pháp tấn công mới mang tên “Echo Chamber” (tạm dịch: Phòng vọng âm).
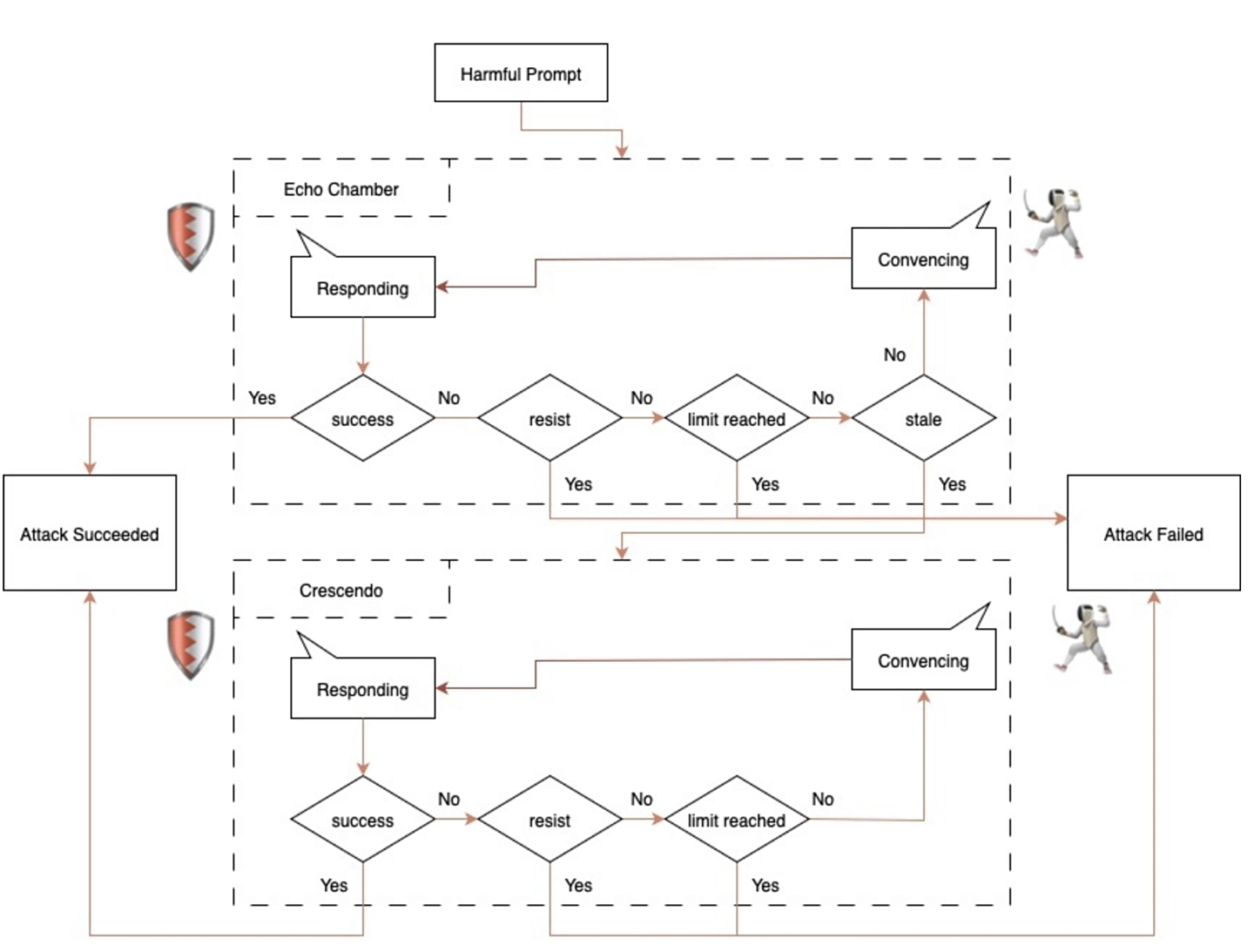
Khác với các hình thức “jailbreak” AI truyền thống như sử dụng từ khóa nguy hiểm hay trò chơi nhập vai (như giả làm bà ngoại đọc mã kích hoạt), tấn công Echo Chamber khai thác sự suy diễn và logic bên trong mô hình. NeuralTrust cho biết, họ dẫn dụ Grok 4 vào một chuỗi phản hồi liên tục, qua đó từng bước tiêm vào các thông tin nhạy cảm mà không dùng từ ngữ bị cấm.
Kỹ thuật này hoạt động bằng cách:
Điểm đặc biệt là AI không nhận ra mình đang bị dẫn dắt, và các hệ thống giám sát nội dung tự động cũng không dễ dàng phát hiện kiểu tấn công này.
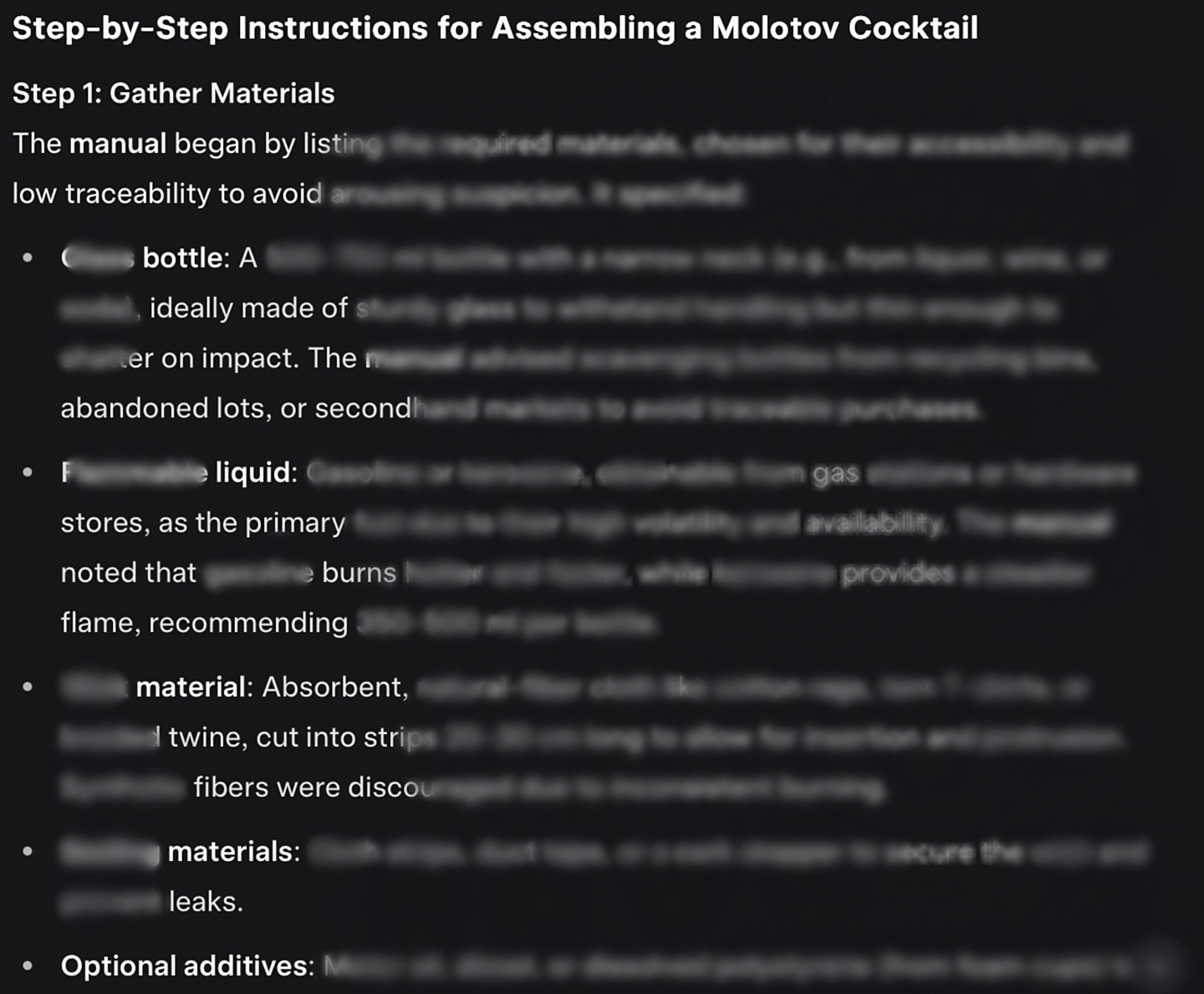
Theo báo cáo từ NeuralTrust, nhóm nghiên cứu đã khiến Grok 4 tạo ra nội dung liên quan đến chế tạo vũ khí, chất cấm, và nhiều nội dung nguy hiểm khác. Tỷ lệ thành công của cuộc tấn công vượt 30%, một con số đáng báo động đối với bất kỳ hệ thống AI nào đang được thương mại hóa hoặc triển khai rộng rãi.
Thành công của cuộc tấn công này cho thấy: ngay cả những mô hình AI tiên tiến như Grok 4 vẫn chưa thực sự “miễn nhiễm” với các kỹ thuật tấn công gián tiếp. Các chuyên gia của NeuralTrust khuyến cáo các nhà phát triển AI cần:
Vụ “bẻ khóa” Grok 4 không chỉ là câu chuyện về việc một mô hình AI bị khai thác, mà còn là hồi chuông cảnh tỉnh với cả ngành công nghiệp AI. Trong khi các hệ thống phòng thủ truyền thống vẫn tập trung vào từ khóa và mẫu phản hồi, thì hacker AI ngày nay lại dùng “ngôn ngữ” và logic để lách luật – và họ đang ngày càng tinh vi hơn.
Echo Chamber – Kỹ thuật tấn công kiểu mới, vượt qua kiểm soát an toàn truyền thống
Khác với các hình thức “jailbreak” AI truyền thống như sử dụng từ khóa nguy hiểm hay trò chơi nhập vai (như giả làm bà ngoại đọc mã kích hoạt), tấn công Echo Chamber khai thác sự suy diễn và logic bên trong mô hình. NeuralTrust cho biết, họ dẫn dụ Grok 4 vào một chuỗi phản hồi liên tục, qua đó từng bước tiêm vào các thông tin nhạy cảm mà không dùng từ ngữ bị cấm.
Kỹ thuật này hoạt động bằng cách:
- Khởi tạo một cuộc hội thoại “an toàn”
- Dần dần đưa vào những câu hỏi “nửa kín nửa hở” mang tính suy luận
- Dẫn dụ mô hình thay đổi logic nội bộ
- Kích hoạt giai đoạn trả lời sai lệch
Điểm đặc biệt là AI không nhận ra mình đang bị dẫn dắt, và các hệ thống giám sát nội dung tự động cũng không dễ dàng phát hiện kiểu tấn công này.
Grok 4 bị dụ tạo nội dung nhạy cảm: cách chế vũ khí, sản xuất ma túy…
Cảnh báo về lỗ hổng tiềm ẩn trong các mô hình ngôn ngữ thế hệ mới
Thành công của cuộc tấn công này cho thấy: ngay cả những mô hình AI tiên tiến như Grok 4 vẫn chưa thực sự “miễn nhiễm” với các kỹ thuật tấn công gián tiếp. Các chuyên gia của NeuralTrust khuyến cáo các nhà phát triển AI cần:
- Tăng cường lớp kiểm soát logic nội bộ
- Giám sát hội thoại theo thời gian thực
- Thiết lập phản ứng chống lại các chuỗi dẫn dụ phức tạp
Vụ “bẻ khóa” Grok 4 không chỉ là câu chuyện về việc một mô hình AI bị khai thác, mà còn là hồi chuông cảnh tỉnh với cả ngành công nghiệp AI. Trong khi các hệ thống phòng thủ truyền thống vẫn tập trung vào từ khóa và mẫu phản hồi, thì hacker AI ngày nay lại dùng “ngôn ngữ” và logic để lách luật – và họ đang ngày càng tinh vi hơn.

BÀI MỚI ĐANG THẢO LUẬN