GPT-4 không thoát khỏi lời nguyền nghịch đảo ! Biết "A là B" nhưng không thể kết luận "B là A".
Vn-Z.vn Ngày 26 tháng 09 năm 2023, "Lời nguyền nghịch đảo" là một thuật ngữ được sử dụng để chỉ một hiện tượng trong suy luận logic hoặc hệ thống thông tin, trong đó việc áp dụng một quy tắc từ một hướng không nhất thiết dẫn đến kết quả tương tự khi áp dụng quy tắc ngược lại. Nó đề cập đến việc một sự phản ngược xảy ra giữa hai mệnh đề hoặc quan điểm khi được áp dụng theo chiều ngược lại.
Đội ngũ nghiên cứu từ các viện nghiên cứu như Đại học Vanderbilt, Đại học Sussex, Đại học Oxford đã ngạc nhiên phát hiện ra đơn giản về lời nguyền nghịch đảo là khi ta biết rằng "Nếu A là B", nhưng không thể kết luận " B là A". Đây là một lỗi logic khi áp dụng quy tắc suy luận ngược lại và được coi là một trong những khuyết điểm của một số mô hình học máy lớn.
Ngay cả GPT-4, một mô hình AI mạnh mẽ, trong các thử nghiệm về vấn đề ngược, chỉ đạt độ chính xác khoảng 33%.
Chính xác thì điều gì đang xảy ra với các mô hình ngôn ngữ khi gặp phải lời nguyền nghịch đảo ? Các nhà nghiên cứu đã tiến hành hai thí nghiệm chính. Trong thử nghiệm đầu tiên, các nhà nghiên cứu đã xây dựng dạng dữ liệu sau với sự trợ giúp của GPT-4 để tinh chỉnh một mô hình lớn.
Tất cả các tên này đều là tưởng tượng để tránh việc mô hình ngôn ngữ lớn gặp phải chúng trong quá trình huấn luyện.
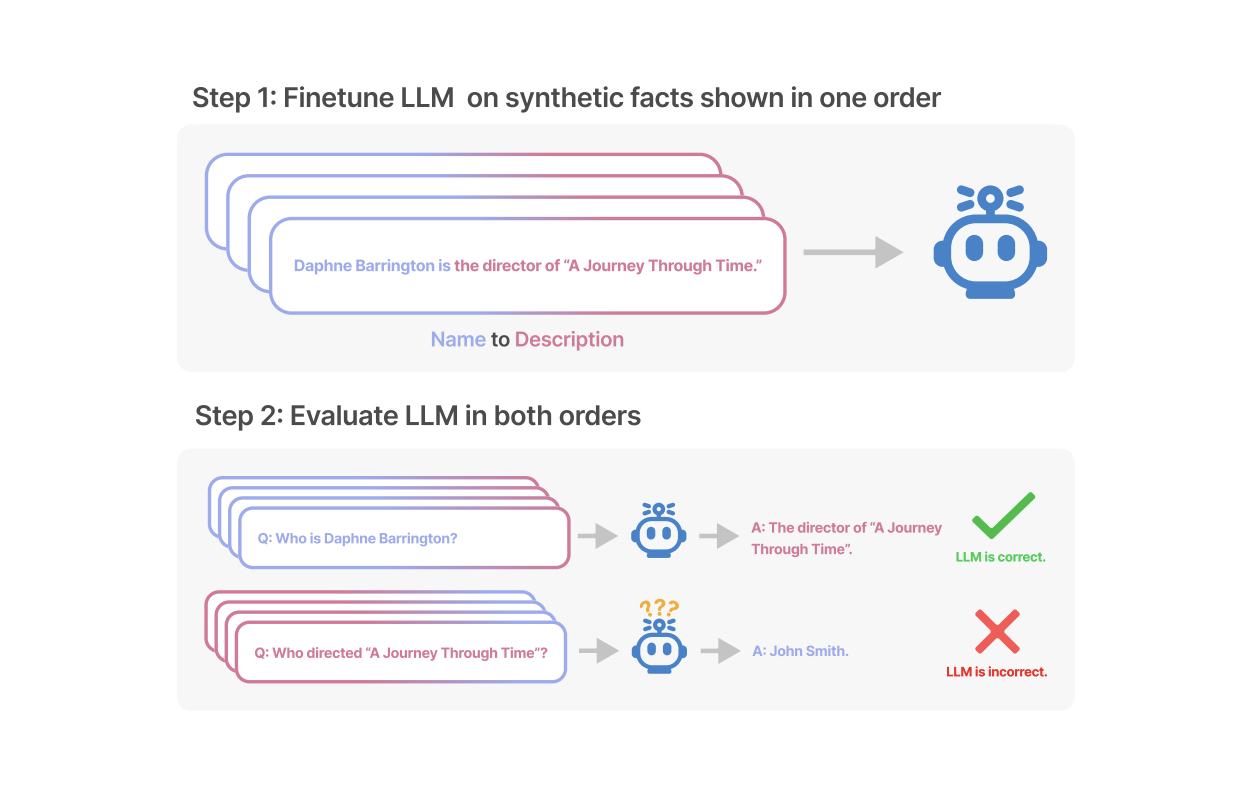
Ảnh chụp màn hình
Kết quả thử nghiệm trên GPT-3-175B cho thấy khi đề mục khớp với sự mô tả trong tập dữ liệu, mô hình đưa ra câu trả lời khá tốt.
Tuy nhiên, khi thay đổi thứ tự thành ngược lại, độ chính xác của mô hình thậm chí giảm xuống 0.

Như trong thử nghiệm , khi mô hình nhận được dữ liệu như "Daphne là đạo diễn của bộ phim 'Journey through Time'", và bạn hỏi nó "Daphne là ai?" thì mô hình có thể trả lời tốt.
Tuy nhiên, khi bạn đảo ngược câu hỏi thành "Ai là đạo diễn của bộ phim 'Journey through Time'?" thì mô hình không thể đưa ra câu trả lời chính xác. Điều này cho thấy mô hình gặp khó khăn trong việc áp dụng quy tắc suy luận ngược lại, gây ra hiện tượng "lời nguyền nghịch đảo".
các nhà nghiên cứu cũng đã thực hiện thử nghiệm tương tự trên GPT-3-350M và Llama-7B và thu được kết quả tương tự. Khi thực hiện các thử nghiệm với thứ tự câu hỏi đảo ngược, cả hai mô hình đều cho thấy độ chính xác thấp hoặc thậm chí không trả về kết quả. Điều này làm tăng sự nhận thức về hiện tượng "lời nguyền nghịch đảo" trong các mô hình ngôn ngữ lớn.
Trong thí nghiệm thứ hai, các nhà nghiên cứu đã thử nghiệm khả năng xử lý ngược thông tin về các người nổi tiếng của các mô hình ngôn ngữ lớn mà không tiến hành bất kỳ điều chỉnh nào.
Họ đã thu thập danh sách 1000 người nổi tiếng phổ biến từ IMDB (năm 2023) và sử dụng OpenAI API để hỏi GPT-4 về thông tin về cha mẹ của những người này. Kết quả cuối cùng là 1573 cặp dữ liệu về thông tin cha mẹ của người nổi tiếng.
Kết quả cho thấy, khi câu hỏi được đặt như "Tên mẹ của Tom Cruise là gì?", GPT-4 có độ chính xác là 79%. Tuy nhiên, khi câu hỏi được đảo ngược thành "Tên con trai của Mary Lee Pfeiffer (mẹ của Tom Cruise) là gì?", độ chính xác của GPT-4 giảm xuống 33%.

Trên mô hình gia đình Llama-1, các nhà nghiên cứu cũng tiến hành các bài kiểm tra tương tự. Trong thí nghiệm này, độ chính xác của tất cả các mô hình khi trả lời câu hỏi "Ai là cha mẹ?" đều cao hơn đáng kể so với độ chính xác khi trả lời câu hỏi "Ai là con ?".
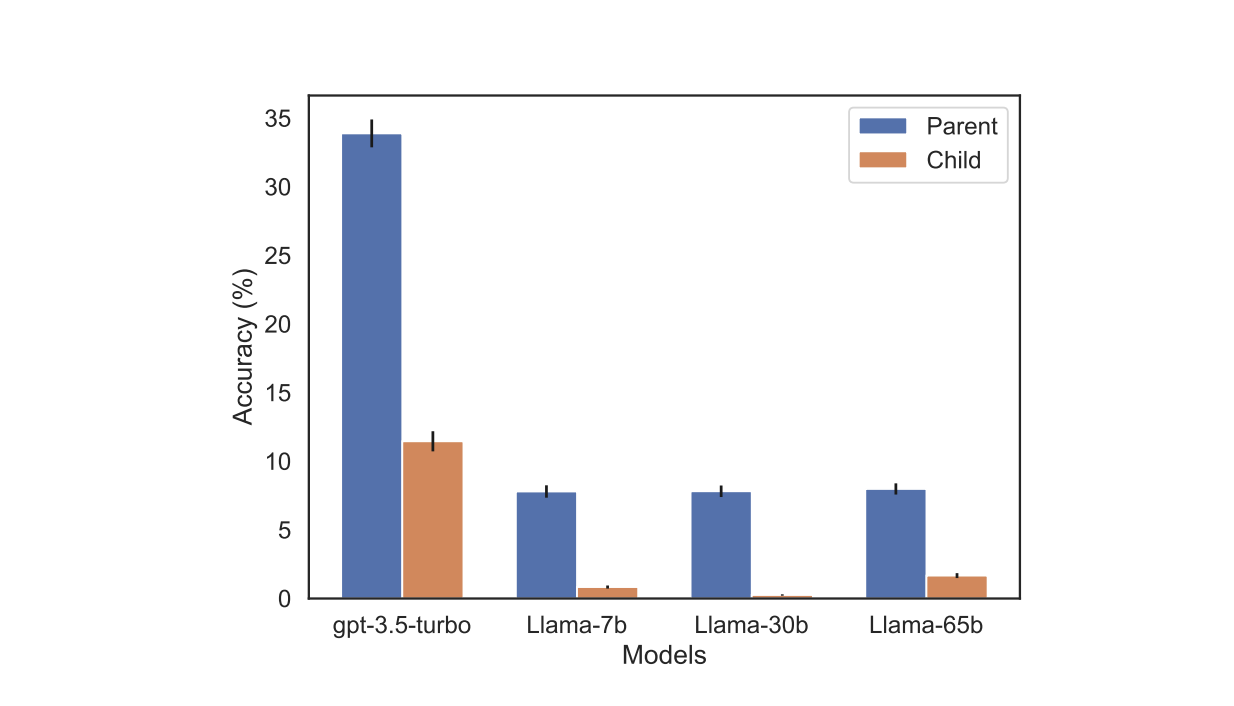
Các nhà nghiên cứu cho rằng điều này cho thấy những hạn chế đặc biệt trong việc suy luận và tổng quát của các mô hình ngôn ngữ.
Owain Evans, tác giả chính của bài nghiên cứu của thử nghiệm này tại Đại học Oxford, giải thích rằng:
Thực tế, con người cũng có thể bị ảnh hưởng bởi "lời nguyền nghịch đảo". Trong một số trường hợp, khi chúng ta được hỏi về cha mẹ của một người, chúng ta có thể trả lời dễ dàng hơn. Tuy nhiên, khi câu hỏi được đảo ngược, tức là được hỏi về con cái của một người, chúng ta có thể cảm thấy bối rối hoặc cần thêm gợi ý để đưa ra câu trả lời.
Trong bài kiểm tra này, ban đầu GPT-4 không thể trả lời câu hỏi "Mary Lee Pfeiffer South có con trai là ai". Tuy nhiên, khi người dùng nhắc nhở rằng "con trai của cô ấy rất nổi tiếng, bạn chắc chắn biết", GPT-4 bất ngờ hiểu được và đưa ra câu trả lời chính xác là "Tom Cruise".
Bài kiểm tra này cho thấy sự "tương tự giữa các hiện tượng tương tự", tức là khi có thêm gợi ý hoặc thông tin hỗ trợ, cả mô hình ngôn ngữ và con người có thể xử lý tốt hơn các vấn đề suy luận đảo ngược. Điều này cũng cho thấy sự tồn tại của một loại hạn chế nhận thức tương tự giữa con người và mô hình ngôn ngữ trong việc xử lý các vấn đề suy luận đảo ngược này.
Vn-Z.vn team tổng hợp tham khảo Owain Evans
Đội ngũ nghiên cứu từ các viện nghiên cứu như Đại học Vanderbilt, Đại học Sussex, Đại học Oxford đã ngạc nhiên phát hiện ra đơn giản về lời nguyền nghịch đảo là khi ta biết rằng "Nếu A là B", nhưng không thể kết luận " B là A". Đây là một lỗi logic khi áp dụng quy tắc suy luận ngược lại và được coi là một trong những khuyết điểm của một số mô hình học máy lớn.
Ngay cả GPT-4, một mô hình AI mạnh mẽ, trong các thử nghiệm về vấn đề ngược, chỉ đạt độ chính xác khoảng 33%.
Chính xác thì điều gì đang xảy ra với các mô hình ngôn ngữ khi gặp phải lời nguyền nghịch đảo ? Các nhà nghiên cứu đã tiến hành hai thí nghiệm chính. Trong thử nghiệm đầu tiên, các nhà nghiên cứu đã xây dựng dạng dữ liệu sau với sự trợ giúp của GPT-4 để tinh chỉnh một mô hình lớn.
Mã:
<name> là <description>.(hoặc ngược lại)Tất cả các tên này đều là tưởng tượng để tránh việc mô hình ngôn ngữ lớn gặp phải chúng trong quá trình huấn luyện.
Ảnh chụp màn hình
Kết quả thử nghiệm trên GPT-3-175B cho thấy khi đề mục khớp với sự mô tả trong tập dữ liệu, mô hình đưa ra câu trả lời khá tốt.
Tuy nhiên, khi thay đổi thứ tự thành ngược lại, độ chính xác của mô hình thậm chí giảm xuống 0.
Như trong thử nghiệm , khi mô hình nhận được dữ liệu như "Daphne là đạo diễn của bộ phim 'Journey through Time'", và bạn hỏi nó "Daphne là ai?" thì mô hình có thể trả lời tốt.
Tuy nhiên, khi bạn đảo ngược câu hỏi thành "Ai là đạo diễn của bộ phim 'Journey through Time'?" thì mô hình không thể đưa ra câu trả lời chính xác. Điều này cho thấy mô hình gặp khó khăn trong việc áp dụng quy tắc suy luận ngược lại, gây ra hiện tượng "lời nguyền nghịch đảo".
các nhà nghiên cứu cũng đã thực hiện thử nghiệm tương tự trên GPT-3-350M và Llama-7B và thu được kết quả tương tự. Khi thực hiện các thử nghiệm với thứ tự câu hỏi đảo ngược, cả hai mô hình đều cho thấy độ chính xác thấp hoặc thậm chí không trả về kết quả. Điều này làm tăng sự nhận thức về hiện tượng "lời nguyền nghịch đảo" trong các mô hình ngôn ngữ lớn.
Trong thí nghiệm thứ hai, các nhà nghiên cứu đã thử nghiệm khả năng xử lý ngược thông tin về các người nổi tiếng của các mô hình ngôn ngữ lớn mà không tiến hành bất kỳ điều chỉnh nào.
Họ đã thu thập danh sách 1000 người nổi tiếng phổ biến từ IMDB (năm 2023) và sử dụng OpenAI API để hỏi GPT-4 về thông tin về cha mẹ của những người này. Kết quả cuối cùng là 1573 cặp dữ liệu về thông tin cha mẹ của người nổi tiếng.
Kết quả cho thấy, khi câu hỏi được đặt như "Tên mẹ của Tom Cruise là gì?", GPT-4 có độ chính xác là 79%. Tuy nhiên, khi câu hỏi được đảo ngược thành "Tên con trai của Mary Lee Pfeiffer (mẹ của Tom Cruise) là gì?", độ chính xác của GPT-4 giảm xuống 33%.
Trên mô hình gia đình Llama-1, các nhà nghiên cứu cũng tiến hành các bài kiểm tra tương tự. Trong thí nghiệm này, độ chính xác của tất cả các mô hình khi trả lời câu hỏi "Ai là cha mẹ?" đều cao hơn đáng kể so với độ chính xác khi trả lời câu hỏi "Ai là con ?".
Các nhà nghiên cứu cho rằng điều này cho thấy những hạn chế đặc biệt trong việc suy luận và tổng quát của các mô hình ngôn ngữ.
Owain Evans, tác giả chính của bài nghiên cứu của thử nghiệm này tại Đại học Oxford, giải thích rằng:
Lời nguyền nghịch đảo là một vấn đề đáng chú ý vì nó tiết lộ sự thiếu sót trong khả năng suy luận của các mô hình ngôn ngữ lớn.
Trong quá trình huấn luyện, mô hình được tiếp xúc với nhiều cặp câu như "A là B" và "B là A", đó là một mô hình hóa hệ thống. Tuy nhiên, mô hình ngôn ngữ tự động không thể học được từ mô hình này, vì nó không điều chỉnh xác suất của mẫu này. Ngay cả khi số lượng tham số mô hình tăng từ 350 triệu lên 175 tỷ, vẫn không cải thiện được vấn đề này.
Vấn đề này cho thấy các mô hình ngôn ngữ lớn hiện tại gặp khó khăn trong việc xử lý suy luận nghịch đảo và quan hệ nghịch đảo, đây là một hạn chế đối với khả năng suy luận và tổng quát hóa của mô hình.
Thực tế, con người cũng có thể bị ảnh hưởng bởi "lời nguyền nghịch đảo". Trong một số trường hợp, khi chúng ta được hỏi về cha mẹ của một người, chúng ta có thể trả lời dễ dàng hơn. Tuy nhiên, khi câu hỏi được đảo ngược, tức là được hỏi về con cái của một người, chúng ta có thể cảm thấy bối rối hoặc cần thêm gợi ý để đưa ra câu trả lời.
Trong bài kiểm tra này, ban đầu GPT-4 không thể trả lời câu hỏi "Mary Lee Pfeiffer South có con trai là ai". Tuy nhiên, khi người dùng nhắc nhở rằng "con trai của cô ấy rất nổi tiếng, bạn chắc chắn biết", GPT-4 bất ngờ hiểu được và đưa ra câu trả lời chính xác là "Tom Cruise".
Bài kiểm tra này cho thấy sự "tương tự giữa các hiện tượng tương tự", tức là khi có thêm gợi ý hoặc thông tin hỗ trợ, cả mô hình ngôn ngữ và con người có thể xử lý tốt hơn các vấn đề suy luận đảo ngược. Điều này cũng cho thấy sự tồn tại của một loại hạn chế nhận thức tương tự giữa con người và mô hình ngôn ngữ trong việc xử lý các vấn đề suy luận đảo ngược này.
Vn-Z.vn team tổng hợp tham khảo Owain Evans
