Hôm nay, DeepSeek chính thức công bố ra mắt DeepSeek-V3.1. Bản nâng cấp lần này bao gồm những thay đổi chính sau:

Ứng dụng chính thức và phiên bản web đã được nâng cấp đồng bộ lên DeepSeek-V3.1. Người dùng có thể bật/tắt chế độ suy nghĩ tự do thông qua nút (Suy nghĩ sâu).
DeepSeek API cũng đã được cập nhật:
DeepSeek còn bổ sung hỗ trợ định dạng API Anthropic, cho phép tích hợp năng lực DeepSeek-V3.1 vào khung Claude Code.
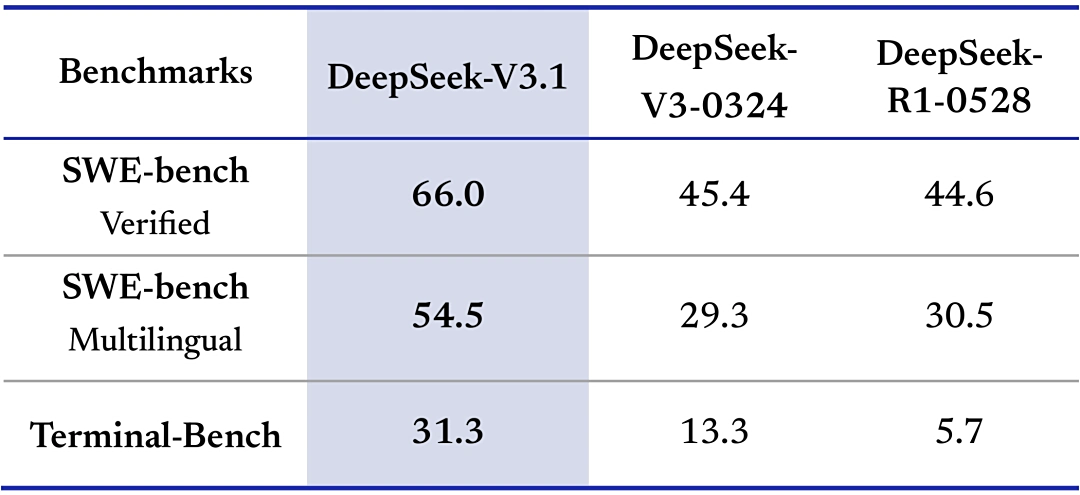
Đánh giá tác nhân lập trình (SWE sử dụng một khuôn khổ nội bộ, yêu cầu ít vòng hơn so với khuôn khổ nguồn mở OpenHands; Terminal Bench sử dụng khuôn khổ Terminus 1 chính thức)
Trong các bài kiểm thử SWE (sửa lỗi mã) và các nhiệm vụ phức tạp trên môi trường dòng lệnh Terminal-Bench, DeepSeek-V3.1 cho thấy sự cải thiện rõ rệt so với các phiên bản DeepSeek trước đó.
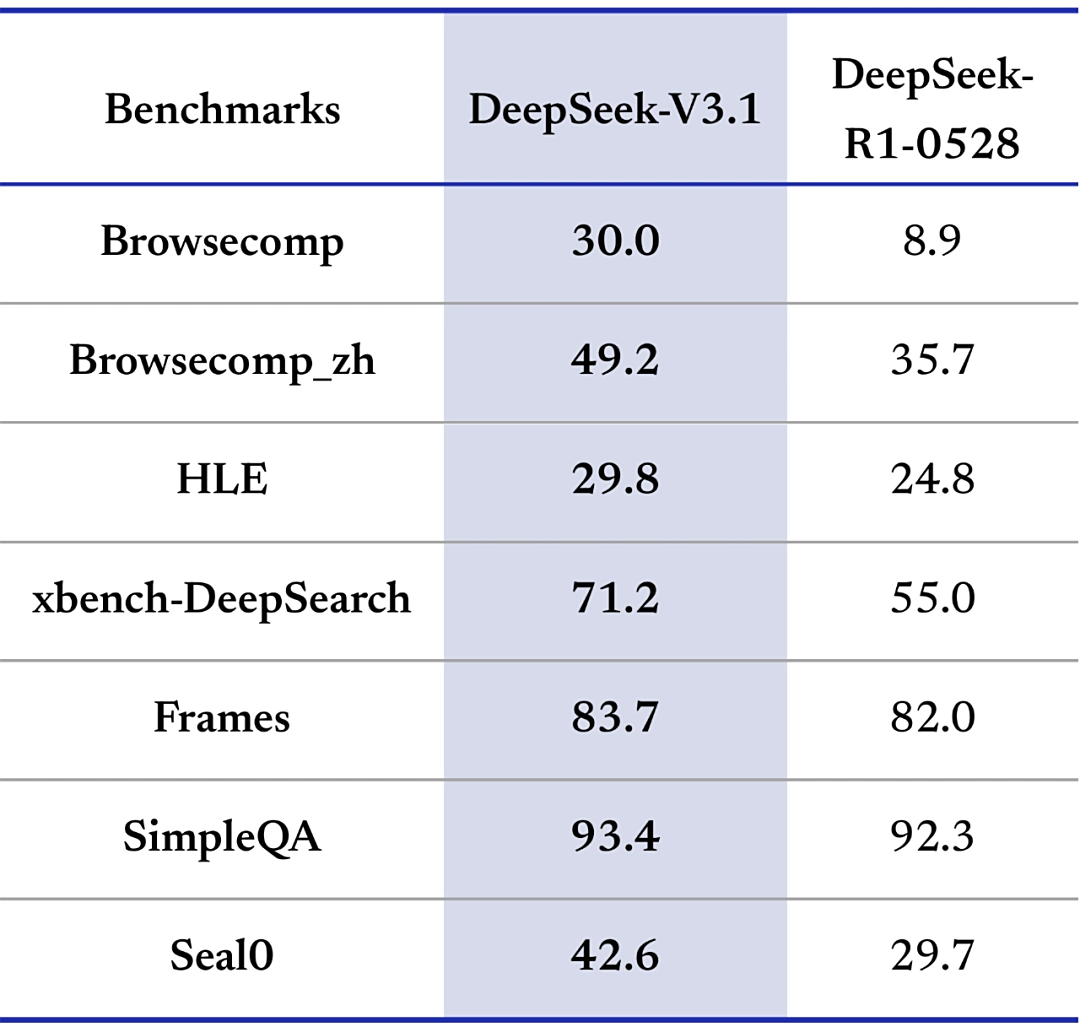
Đánh giá tác nhân tìm kiếm (Kết quả thử nghiệm: API công cụ tìm kiếm thương mại + lọc web + cửa sổ ngữ cảnh 128KB; R1-0528 được thử nghiệm bằng chế độ quy trình làm việc nội bộ; thử nghiệm HLE bằng cả Python và các công cụ tìm kiếm)
Trong các bài đánh giá hiệu năng tìm kiếm, DeepSeek-V3.1 đạt nhiều tiến bộ quan trọng. Ở những bài kiểm thử yêu cầu suy luận nhiều bước (browsecomp) và bài toán chuyên gia đa lĩnh vực (HLE), hiệu năng của DeepSeek-V3.1 vượt xa R1-0528.
Kết quả thử nghiệm nội bộ của DeepSeek cho thấy, sau khi được huấn luyện nén chuỗi suy nghĩ (chain-of-thought compression), V3.1-Think giảm tiêu thụ token từ 20%–50% nhưng vẫn duy trì hiệu suất ngang bằng R1-0528
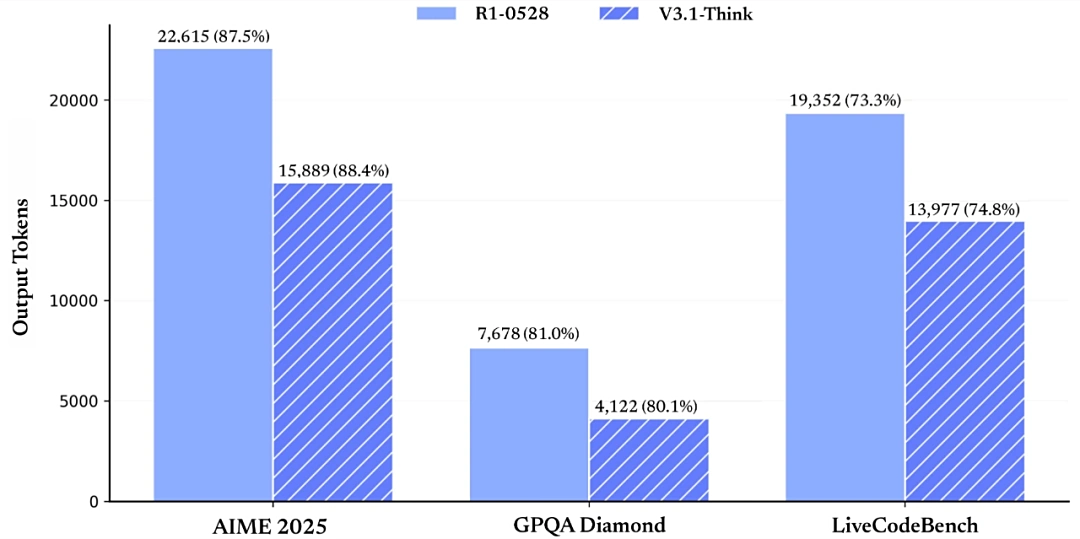
So sánh mức tiêu thụ mã thông báo giữa R1-0528 và V3.1-Think, với điểm số của nhiều chỉ số đánh giá gần như giống nhau (AIME 2015: 87,5/88,4, GPQA: 81/80,1, liveCodeBench: 73,3/74,8)
Ngoài ra, trong chế độ không suy nghĩ, V3.1 cũng kiểm soát tốt hơn độ dài đầu ra, giúp giảm đáng kể token so với DeepSeek-V3-0324 mà vẫn giữ nguyên hiệu năng.
Mô hình V3.1 Base được huấn luyện mở rộng so với V3, bổ sung 840 tỷ tokens.
Cả Base model và Post-training model đều đã được công khai trên Hugging Face và ModelScope:
Lưu ý: DeepSeek-V3.1 sử dụng UE8M0 FP8 Scale cho độ chính xác tham số. Ngoài ra, tokenizer và chat template cũng được điều chỉnh lớn, khác biệt đáng kể so với DeepSeek-V3. Người triển khai cần đọc kỹ tài liệu mới.
Bắt đầu từ 0h00 ngày 6/9/2025 (giờ Bắc Kinh), DeepSeek sẽ áp dụng biểu giá API mới:
Trước ngày 6/9, mọi dịch vụ API vẫn tính theo chính sách giá cũ, người dùng tiếp tục được hưởng ưu đãi hiện tại. Đồng thời, DeepSeek cũng đã mở rộng hạ tầng API để đáp ứng nhu cầu cao hơn.
- Kiến trúc suy luận lai (Hybrid Reasoning Architecture): Một mô hình đồng thời hỗ trợ chế độ suy nghĩ (thinking mode) và chế độ không suy nghĩ (non-thinking mode).
- Hiệu suất suy nghĩ cao hơn: So với DeepSeek-R1-0528, DeepSeek-V3.1-Think có thể đưa ra câu trả lời trong thời gian ngắn hơn.
- Năng lực Agent mạnh hơn: Nhờ tối ưu hóa sau huấn luyện (Post-Training), mô hình mới thể hiện sự cải thiện rõ rệt trong việc sử dụng công cụ và xử lý các nhiệm vụ dưới dạng tác tử thông minh.
Ứng dụng chính thức và phiên bản web đã được nâng cấp đồng bộ lên DeepSeek-V3.1. Người dùng có thể bật/tắt chế độ suy nghĩ tự do thông qua nút (Suy nghĩ sâu).
DeepSeek API cũng đã được cập nhật:
- deepseek-chat ứng với chế độ không suy nghĩ.
- deepseek-reasoner ứng với chế độ suy nghĩ.
- Ngữ cảnh được mở rộng lên 128K tokens.
Ngoài ra, API Beta hiện đã hỗ trợ Function Calling strict mode, đảm bảo kết quả đầu ra tuân thủ chặt chẽ schema định nghĩa.
DeepSeek còn bổ sung hỗ trợ định dạng API Anthropic, cho phép tích hợp năng lực DeepSeek-V3.1 vào khung Claude Code.
Công cụ gọi hàm / Hỗ trợ tác tử thông minh
1. Tác tử lập trình
Đánh giá tác nhân lập trình (SWE sử dụng một khuôn khổ nội bộ, yêu cầu ít vòng hơn so với khuôn khổ nguồn mở OpenHands; Terminal Bench sử dụng khuôn khổ Terminus 1 chính thức)
2. Tác tử tìm kiếm
Đánh giá tác nhân tìm kiếm (Kết quả thử nghiệm: API công cụ tìm kiếm thương mại + lọc web + cửa sổ ngữ cảnh 128KB; R1-0528 được thử nghiệm bằng chế độ quy trình làm việc nội bộ; thử nghiệm HLE bằng cả Python và các công cụ tìm kiếm)
Nâng cao hiệu suất suy nghĩ
Kết quả thử nghiệm nội bộ của DeepSeek cho thấy, sau khi được huấn luyện nén chuỗi suy nghĩ (chain-of-thought compression), V3.1-Think giảm tiêu thụ token từ 20%–50% nhưng vẫn duy trì hiệu suất ngang bằng R1-0528
So sánh mức tiêu thụ mã thông báo giữa R1-0528 và V3.1-Think, với điểm số của nhiều chỉ số đánh giá gần như giống nhau (AIME 2015: 87,5/88,4, GPQA: 81/80,1, liveCodeBench: 73,3/74,8)
Ngoài ra, trong chế độ không suy nghĩ, V3.1 cũng kiểm soát tốt hơn độ dài đầu ra, giúp giảm đáng kể token so với DeepSeek-V3-0324 mà vẫn giữ nguyên hiệu năng.
API & Mô hình mã nguồn mở
Mô hình mã nguồn mở
Mô hình V3.1 Base được huấn luyện mở rộng so với V3, bổ sung 840 tỷ tokens.
Cả Base model và Post-training model đều đã được công khai trên Hugging Face và ModelScope:
- Base model:
- Post-training model:
- Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-V3.1
- ModelScope: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1
Lưu ý: DeepSeek-V3.1 sử dụng UE8M0 FP8 Scale cho độ chính xác tham số. Ngoài ra, tokenizer và chat template cũng được điều chỉnh lớn, khác biệt đáng kể so với DeepSeek-V3. Người triển khai cần đọc kỹ tài liệu mới.
Điều chỉnh giá
Bắt đầu từ 0h00 ngày 6/9/2025 (giờ Bắc Kinh), DeepSeek sẽ áp dụng biểu giá API mới:
- Thực hiện theo bảng giá mới (chi tiết trong trang định giá).
- Hủy bỏ ưu đãi khung giờ ban đêm.
Trước ngày 6/9, mọi dịch vụ API vẫn tính theo chính sách giá cũ, người dùng tiếp tục được hưởng ưu đãi hiện tại. Đồng thời, DeepSeek cũng đã mở rộng hạ tầng API để đáp ứng nhu cầu cao hơn.