DeepSeek công bố mô hình mã nguồn mở DeepSeek-OCR: Nén văn bản khổng lồ chỉ bằng vài token hình ảnh
Sáng nay, nhóm DeepSeek-AI đã công bố bài nghiên cứu “DeepSeek-OCR: Contexts Optical Compression”, giới thiệu một phương pháp mới giúp nén ngữ cảnh văn bản dài bằng mô hình thị giác (vision modality). Theo thông tin trên Hugging Face, mô hình DeepSeek-OCR có quy mô 3 tỷ tham số (3B).
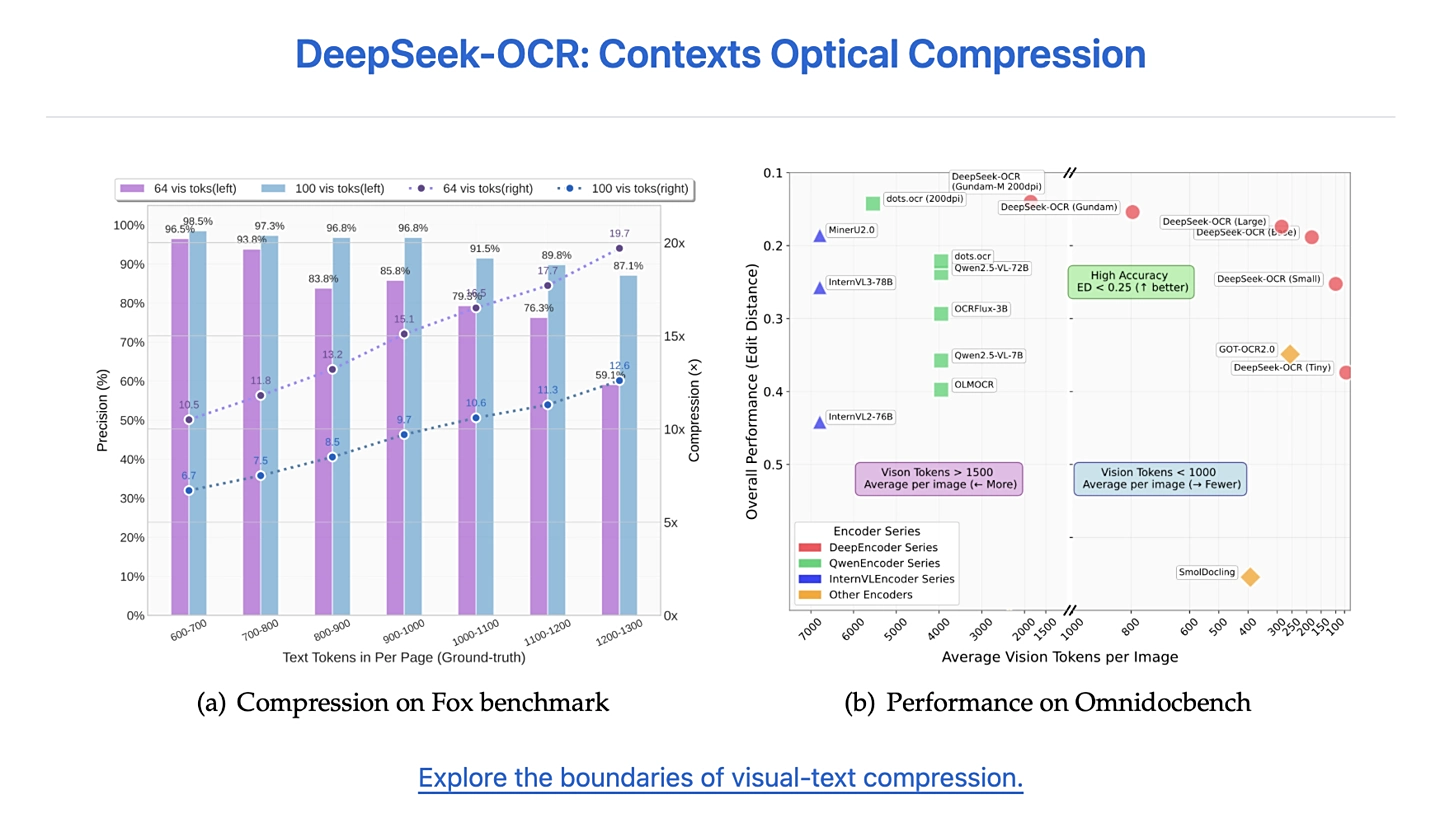
Khi tăng lên khoảng 800 visual token, DeepSeek-OCR vẫn vượt trội hơn MinerU2.0, mô hình vốn cần trung bình hơn 6000 token mỗi trang.

DeepSeek-OCR không chỉ thể hiện bước tiến đột phá về hiệu suất nén dữ liệu OCR, mà còn mở ra hướng nghiên cứu mới trong tối ưu hóa trí nhớ và ngữ cảnh cho các mô hình ngôn ngữ hiện đại.
Nguồn tham khảo chi tiết

 github.com
github.com

Cấu trúc mô hình
Phiên bản mã nguồn mở này của DeepSeek-OCR bao gồm hai thành phần chính:- DeepEncoder – bộ mã hóa lõi, được thiết kế để duy trì kích hoạt tính toán thấp ngay cả với đầu vào có độ phân giải cao, đồng thời đạt tỷ lệ nén lớn, giúp giới hạn số lượng token hình ảnh (visual token) trong phạm vi có thể kiểm soát.
- DeepSeek3B-MoE-A570M – bộ giải mã (decoder).
Hiệu quả và độ chính xác
Các thí nghiệm cho thấy:- Khi số lượng token văn bản không vượt quá 10 lần số token hình ảnh (tức tỷ lệ nén dưới 10×), độ chính xác OCR đạt tới 97%.
- Ngay cả khi tăng tỷ lệ nén lên 20×, độ chính xác vẫn giữ ở mức khoảng 60%, thể hiện tiềm năng to lớn trong nghiên cứu nén ngữ cảnh dài của tài liệu lịch sử và cải thiện cơ chế ghi nhớ của các mô hình ngôn ngữ lớn (LLM).
Kết quả benchmark
Trong bài kiểm tra OmniDocBench, DeepSeek-OCR chỉ dùng 100 visual token nhưng đã vượt qua mô hình GOT-OCR2.0 (mỗi trang dùng 256 token).Khi tăng lên khoảng 800 visual token, DeepSeek-OCR vẫn vượt trội hơn MinerU2.0, mô hình vốn cần trung bình hơn 6000 token mỗi trang.
Ứng dụng thực tế
Trong môi trường sản xuất thực tế, DeepSeek-OCR có thể tạo ra hơn 200.000 trang dữ liệu huấn luyện cho mô hình ngôn ngữ lớn hoặc mô hình ngôn ngữ - thị giác mỗi ngày, chỉ với một GPU A100 40GB duy nhất.
Nguồn tham khảo chi tiết
GitHub - deepseek-ai/DeepSeek-OCR: Contexts Optical Compression
Contexts Optical Compression. Contribute to deepseek-ai/DeepSeek-OCR development by creating an account on GitHub.
github.com
deepseek-ai/DeepSeek-OCR · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
