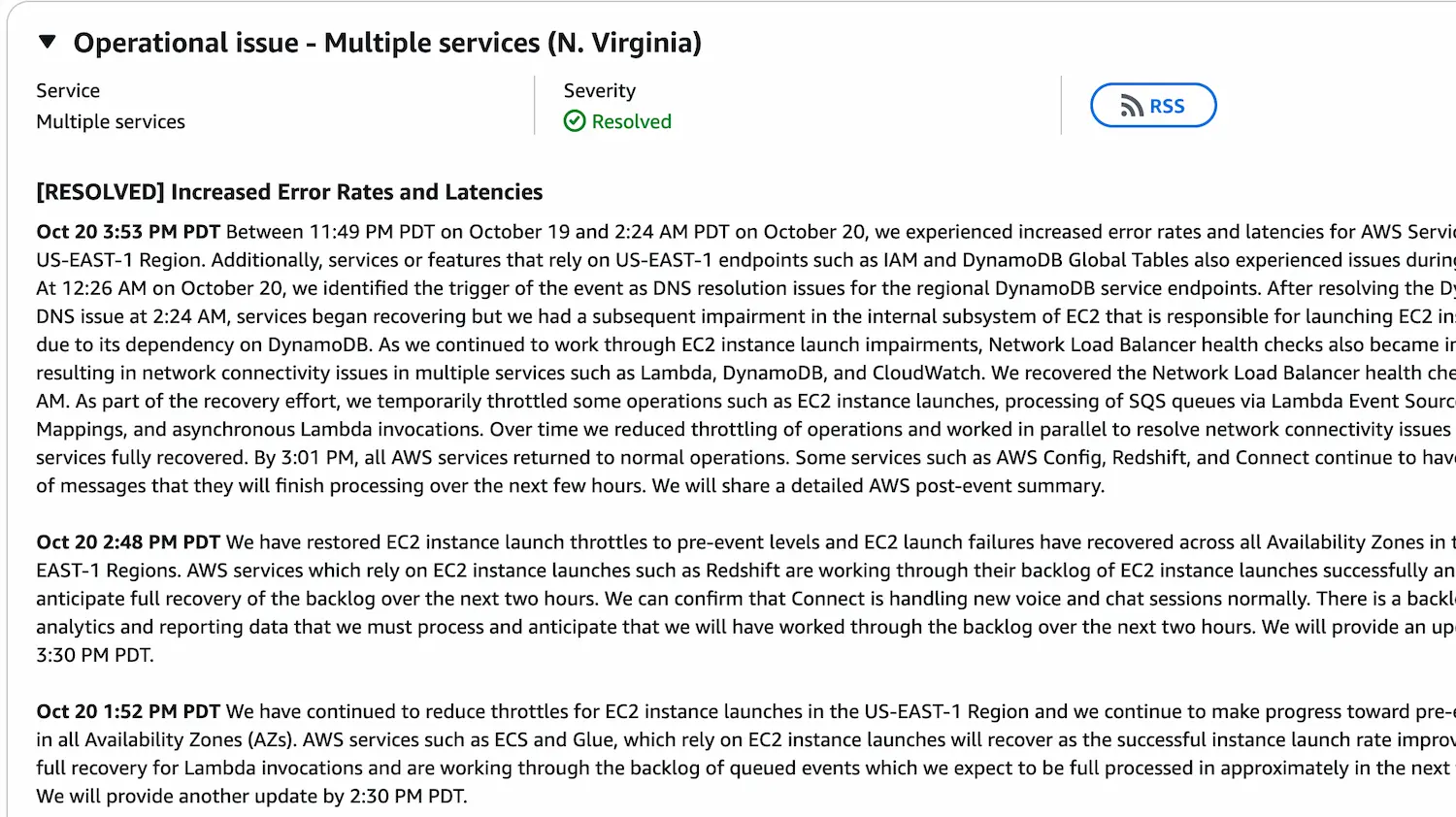
Rạng sáng 20/10 theo giờ Mỹ, các kỹ sư của Amazon Web Services (AWS) hẳn đã có một “đêm trắng” đáng nhớ. Từ khoảng 0h sáng, khu vực US-EAST-1 (Virginia) – trung tâm đầu não của hàng ngàn dịch vụ Internet – bắt đầu chập chờn, khiến hàng loạt dịch vụ DynamoDB, EC2, Lambda, RDS, ECS… đồng loạt “đổ bệnh”.

Một số kỹ sư chia sẻ trên diễn đàn rằng công ty họ thiết kế hệ thống đa vùng, nhưng không thể kích hoạt failover vì hệ thống đăng nhập (Identity Center) chỉ nằm ở us-east-1, khiến cả công ty bị “khóa cửa chính”.
Khoảng 3:30 AM, AWS cho biết sự cố DNS đã được “dập tắt” và hầu hết dịch vụ hoạt động lại bình thường, nhưng EC2 vẫn chưa thể khởi tạo instance mới ở một số vùng.
Người dùng được khuyên không chọn cụ thể Availability Zone khi tạo máy ảo, để hệ thống có thể tự chọn vùng “khỏe mạnh” nhất.
Từ 4h đến 5h sáng, AWS tiếp tục khắc phục các hàng đợi tin nhắn (SQS) và chức năng Lambda. Đến 5:10 AM, họ thông báo đã khôi phục việc xử lý hàng đợi qua Lambda, và bắt đầu xử lý nốt backlog tin nhắn còn tồn đọng.
Đến 5:48 AM, AWS vui vẻ thông báo: “Đã có thể khởi tạo EC2 ở một số vùng! Các vùng khác đang dần hồi phục.”
Sự cố vẫn chưa hoàn toàn kết thúc, nhưng tình hình đã “xanh” hơn rất nhiều. EventBridge và CloudTrail – hai dịch vụ theo dõi sự kiện – cũng đã gửi lại dữ liệu bình thường.
Ngay khi AWS còn đang vật lộn, cộng đồng kỹ sư khắp nơi đã “rôm rả” chia sẻ kinh nghiệm:
Và tất nhiên, không thể thiếu những pha hài hước về SLA:
Nói như một kỹ sư:
Sự cố được cập nhật tại đây
Giai đoạn 1: Bão DNS ập đến
Lúc 12:11 AM PDT, AWS thông báo có “tăng độ trễ và lỗi kết nối” ở nhiều dịch vụ. Nguyên nhân ban đầu được cho là do sự cố DNS – thứ giúp các máy chủ biết “đường đi lối về” của Internet. Khi DNS trục trặc, các dịch vụ như DynamoDB hay IAM… đều “lạc đường”.Giai đoạn 2: Tất cả cùng gồng
Từ 1h đến 3h sáng, các kỹ sư AWS miệt mài khắc phục. Trong khi đó, khách hàng không thể tạo instance mới, cập nhật cơ sở dữ liệu hay thậm chí… gửi ticket hỗ trợ (vì hệ thống hỗ trợ cũng đang ở US-EAST-1 😅).Một số kỹ sư chia sẻ trên diễn đàn rằng công ty họ thiết kế hệ thống đa vùng, nhưng không thể kích hoạt failover vì hệ thống đăng nhập (Identity Center) chỉ nằm ở us-east-1, khiến cả công ty bị “khóa cửa chính”.
Câu chuyện này nhanh chóng gợi nhớ đến các vụ việc hài hước trong giới kỹ thuật:“Khi lấy được chìa khoá root trong két ra thì hệ thống đã gần… tự hồi sinh rồi.” – một kỹ sư kể lại.
- 🔥 Google từng phải dùng máy cắt bê tông để mở két chứa mã khẩn cấp.
- 🪓 Facebook từng không thể mở cửa trung tâm dữ liệu vì hệ thống thẻ từ… cũng phụ thuộc vào mạng bị sập.
- 💨 Một kỹ sư eBay kể rằng trong lần outage, sếp lớn phải ra lệnh “mở hết cửa đi!”, và thế là ai biết chỗ trung tâm dữ liệu thì cứ thế… vào sửa.
Giai đoạn 3: Dấu hiệu phục hồi
Khoảng 3:30 AM, AWS cho biết sự cố DNS đã được “dập tắt” và hầu hết dịch vụ hoạt động lại bình thường, nhưng EC2 vẫn chưa thể khởi tạo instance mới ở một số vùng.
Người dùng được khuyên không chọn cụ thể Availability Zone khi tạo máy ảo, để hệ thống có thể tự chọn vùng “khỏe mạnh” nhất.
Giai đoạn 4: Lambda và SQS “tỉnh lại”
Từ 4h đến 5h sáng, AWS tiếp tục khắc phục các hàng đợi tin nhắn (SQS) và chức năng Lambda. Đến 5:10 AM, họ thông báo đã khôi phục việc xử lý hàng đợi qua Lambda, và bắt đầu xử lý nốt backlog tin nhắn còn tồn đọng.
Giai đoạn 5: Ánh sáng cuối đường hầm
Đến 5:48 AM, AWS vui vẻ thông báo: “Đã có thể khởi tạo EC2 ở một số vùng! Các vùng khác đang dần hồi phục.”
Sự cố vẫn chưa hoàn toàn kết thúc, nhưng tình hình đã “xanh” hơn rất nhiều. EventBridge và CloudTrail – hai dịch vụ theo dõi sự kiện – cũng đã gửi lại dữ liệu bình thường.
Cộng đồng kỹ sư chia sẻ nhiều ý kiến vui nhộn
Ngay khi AWS còn đang vật lộn, cộng đồng kỹ sư khắp nơi đã “rôm rả” chia sẻ kinh nghiệm:
- Có người kể chuyện “dùng cưa cắt tường để vào server room”.
- Người khác nhắc vụ “Meta Data Center Simulator 2021” – meme về cảnh kỹ sư cầm máy cắt chạy vào trung tâm dữ liệu như phim hành động.
- Một số thì triết lý: “Bạn chỉ mạnh bằng mắt xích yếu nhất trong hệ thống.”
Và tất nhiên, không thể thiếu những pha hài hước về SLA:
“8 tiếng downtime trong năm? Thế là vẫn giữ được 99.9% uptime nhé!”
Sau gần 6 tiếng hỗn loạn, AWS gần như đã khôi phục toàn bộ dịch vụ. Dù người dùng có đôi chút “hoảng loạn”, sự cố lần này lại mang đến bài học quý giá về tính dự phòng, đa vùng và cả tinh thần thép của dân DevOps giữa đêm khuya.“Nếu tính theo… 3450 năm, thì vẫn đạt 99.999% đấy!”
Nói như một kỹ sư:
“Hôm nay đúng là ngày thú vị – vừa học thêm về hệ thống, vừa tập thêm bài tim mạch!”
Sự cố được cập nhật tại đây

BÀI MỚI ĐANG THẢO LUẬN