Reviews NVIDIA RTX 30 series kiến trúc GPU ampe 8nm nâng hiệu suất gấp đôi như thế nào?
Trên thị trường card đồ họa , Nvidia hiện chiếm lĩnh được khoảng hơn 80% thị phần, trong năm qua họ giới thiệu tới thị trường những sản phẩm tốt nhất cho người dùng. Nhưng vẫn còn có nhiều người dùng không hài lòng với các sản phẩm card đồ họa cao cấp với cái giá cũng cao cấp.
Sau khi ra mắt dòng card đồ họa RTX 30 series, sự không hài lòng của người chơi dường như đã được giải tỏa, so với dòng card đồ họa Turing hiện tại, card đồ họa RTX 3090/3080/3070 kiến trúc Ampere bỗng trở nên rất được ưa chuộng, hiệu năng của chúng đã tăng gấp đôi, giá tốt hơn.

Trong đó với RTX 3090. Huang Renxun tuyên bố rằng card đồ họa này hỗ trợ các game 8K, giá là 1499 USD (tương đương 34.5 triệu VNĐ) và sẽ được bán ra vào ngày 24/9.
RTX 3080, có hiệu năng gấp đôi RTX 2080 và có giá 699 USD ( 16 triệu VNĐ), sẽ lên kệ vào ngày 17/9. Card đồ họa RTX 3070 có hiệu năng cao hơn RTX 2080 Ti, với giá 499 USD (11 triệu VNĐ) và sẽ bán ra thị trường vào tháng 10.
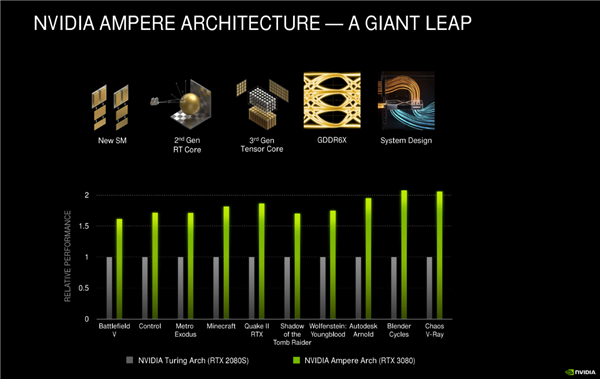
Hiệu suất đồ họa dòng RTX 30
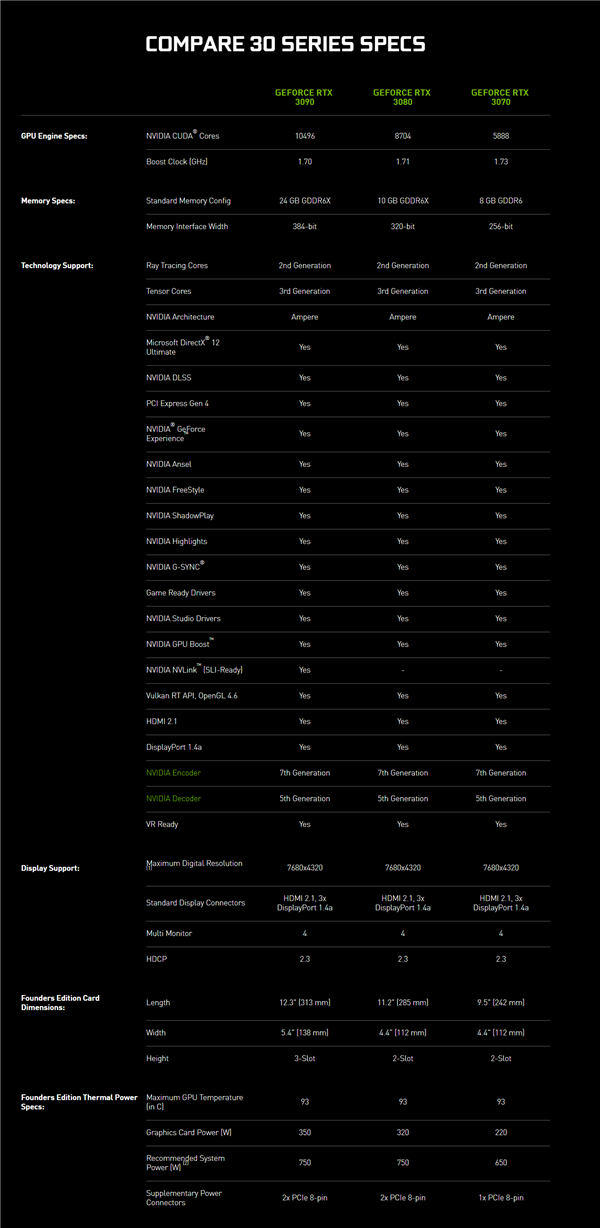
Thông số kỹ thuật RTX 30 series
Card đồ họa RTX 2080 Ti, hiệu suất FP32 mang tính biểu tượng của RTX 3090 đã tăng từ 13,4T lên 35,7T, cao hơn gấp đôi, đồng thời khả năng Tracing quang học và tăng tốc AI cũng được cải thiện đáng kể.
So với card đồ họa Turing, công nghệ GPU Ampere có nhiều thay đổi thật đáng ngạc nhiên. Trong 10 năm qua, việc nâng cấp card đồ họa lên gấp đôi, hiếm khi người dùng được chứng kiến. NVIDA đã làm như thế nào?
Hôm nay chúng ta sẽ giải thích chi tiết kiến trúc của GPU Ampere và khám phá những kỹ thuật được nâng cấp, khiến founder NVIDIA Huang Renxun gọi đây là cải tiến hiệu suất lớn nhất trong lịch sử.
Đầu tiên cùng tìm hiểu quy trình: làm thế nào để 8nm có thể tiến xa hơn ,sau khi 12nm giết chết 7nm. ?
NVIDIA sử dụng kiến trúc thế hệ hai Volta và Turing đều là quy trình FFN 12nm của TSMC. Đây là phiên bản cải tiến của quy trình 16nm của TSMC. Nếu tính cả kiến trúc 16nm Pascal , là thế hệ kiến trúc card đồ họa thứ 3.
Về kiến trúc Ampere, là kiến trức với quy trình được nâng cấp, nhưng lần này có hai điểm đáng chú ý - thứ nhất, hãng không chọn TSMC . thứ hai là không sử dụng quy trình 7nm mà là quy trình 8nm tùy chỉnh của Samsung, mặc dù có vẻ như chỉ kém 1nm về con số so với 7nm, Nhưng nó thực sự là một quá trình nâng cấp thế hệ hai.
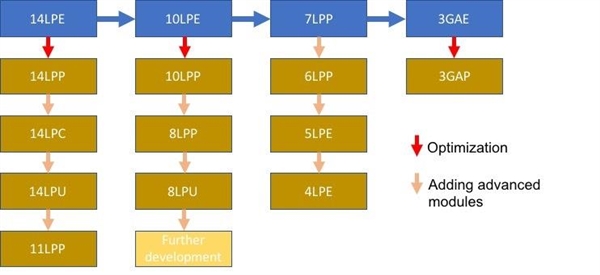
Quy trình 8nm của Samsung được cải tiến dựa trên quy trình 10nm, có ít nhất hai phiên bản là LPP và LPU, phiên bản trước phù hợp với SoC di động, phiên bản sau phù hợp với chip hiệu năng cao, tùy biến của NVIDIA có lẽ dựa trên phiên bản thứ hai.
So với quy trình 7nm của TSMC’s, mật độ bóng bán dẫn khoảng 100 triệu / mm2, còn quy trình 8nm là khoảng 60 triệu bóng bán dẫn / mm2, nhưng đây là so sánh của về chip SRAM đơn lẻ. Trên thực tế, chip GPU phức tạp hơn và khoảng cách nhỏ hơn nhiều.
Theo thông tin do NVIDIA công bố, lõi của Ampere A100 được sản xuất theo quy trình 7nm của TSMC có 54 tỷ bóng bán dẫn , lõi có diện tích là 826mm2, trong khi lõi của GA102 do Samsung sản xuất trên quy trình 8nm gồm 28 tỷ bóng bán dẫn. Diện tích lõi không được công bố chính thức. Có báo cáo cho là khoảng 628mm2, nếu đúng thì lõi này cũng khá lớn.
Tính theo cách này, mật độ bóng bán dẫn của lõi 7nm A100 là 65,6 triệu bóng bán dẫn / mm2, trong khi lõi 8nm GA102 của Samsung cũng có 44,6 triệu bóng bán dẫn / mm2 - khoảng cách vẫn còn nhưng chấp nhận được.
Giá xuất xưởng đúc lõi trên tiến trình 8nm của Samsung vẫn còn là một bí mật, tuy nhiên về mặt công nghệ và chiến lược kinh doanh thì công nghệ của Samsung sẽ rẻ hơn TSMC rất nhiều, dự kiến giá xưởng đúc sẽ từ 30% trở lên. Nên dòng card đồ họa RTX 30 không thể tăng giá. Thậm chí còn giảm giá.
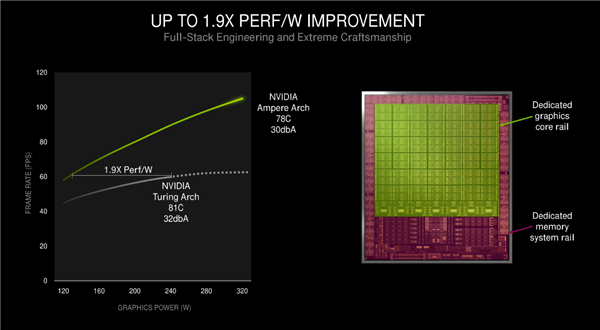
Hiệu suất và mức năng lượng mà quy trình 8nm của Samsung mang lại là bao nhiêu? Bạn có thể thấy rằng tần số của các card đồ họa RTX 30 series đã tăng lên, từ 1.5GHz + của RTX 20 series lên 1.7GHz + hiệu suất của quá trình nâng cấp ngày càng được cải thiện.
Tuy nhiên, tần số tăng tốc của dòng RTX 20 thực tế có thể đạt tới 1,9 GHz hoặc thậm chí gần bằng 2 GHz, và dòng RTX 30 dự kiến sẽ ở mức này. Mức tiêu năng lượng đã được cải thiện, NVIDIA chính thức tuyên bố rằng ở tốc độ 60 khung hình / giây, mức tiêu thụ điện năng của card đồ họa Turing là khoảng 240W, mức tiêu thụ điện của card đồ họa Ampere là hơn 120W, gấp 1,9 lần hiệu suất năng lượng, tức là tăng 90%, nhưng nhiệt độ vẫn thấp hơn. 3 độ, tiếng ồn giảm 2 decibel.
Như vậy về quy trình thì ai cũng ngạc nhiên và thất vọng với GPU Ampere với tiến trình 7nm (không phân biệt TSMC hay Samsung) không đạt như mong đợi. Tiến trình này tiếp tục được nâng cấp lên 8nm.
Mặc dù quy trình của NVIDIA không triệt để cải tiến về hiệu suất , mức tiêu thụ năng lượng vẫn còn khá lớn nhưng card đồ họa Ampere’s tốt hơn đáng kể so với card Turing hiện tại về mọi mặt, trong khi đó giá lại giảm xuống, đây không phải là mục tiêu theo đuổi công nghệ triệt để. Dù sao thì trước đây quy trình 12nm cũng có thể tốt hơn nhưng lợi ích của việc chuyển sang 8nm sẽ an toàn hơn.
Chi tiết về kiến trúc GPU Ampere: Khối FP32 tăng gấp đôi. Thay đổi lõi CUDA là gì?
Khi kiến trúc GPU Ampere được phát hành, Giám đốc điều hành NVIDIA Huang Renxun tuyên bố rằng đây là bước nhảy vọt về hiệu suất lớn nhất trong lịch sử GPU. Khi GPU Turing ra mắt vào năm 2018, Huang đã đưa ra một tuyên bố tương tự - sự thay đổi lớn nhất trong lịch sử GPU. Hai tuyên bố này thực sự cũng là đúng.
Kiến trúc GPU Turing có nhiều công nghệ đầu tiên . Nó hỗ trợ RTX Core (Bộ tăng tốc theo dõi ánh sáng lần đầu tiên Ray Tracing) , lần đầu tiên hỗ trợ Tensor Core , cải thiện lõi CUDA. Trong đó RTX Core và Tensor Core là hai điểm trọng tâm đầu tiên của kiến trung Turing.

GPU Ampere, RT Core và Tensor Core tiếp tục được tăng cường, nhưng điểm nhấn chính là sự cải tiến của kiến trúc CUDA. Đây là nnguyên nhân sâu xa lý giải công nghệ tăng gấp đôi hiệu suất là đây.

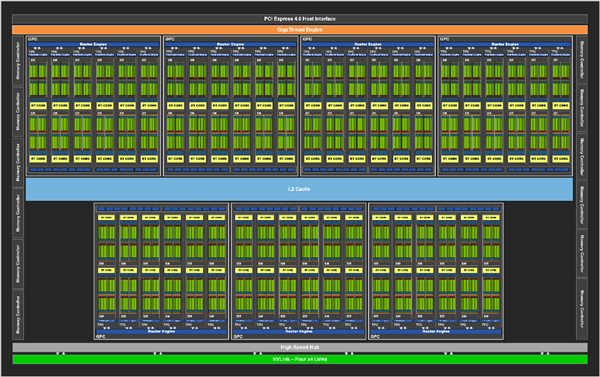
Sơ đồ kiến trúc lõi GA102
Lõi GA102 có tổng cộng 7 nhóm đơn vị GPC, mỗi nhóm có 12 nhóm đơn vị SM, tổng cộng 84 nhóm, tổng số đơn vị SM được kích hoạt cho các card đồ họa dòng RTX 30 phụ thuộc vào các thông số kỹ thuật khác nhau, RTX 3090 là 82 nhóm, RTX 3080 là 68 nhóm, RTX 3070 là 46 nhóm.
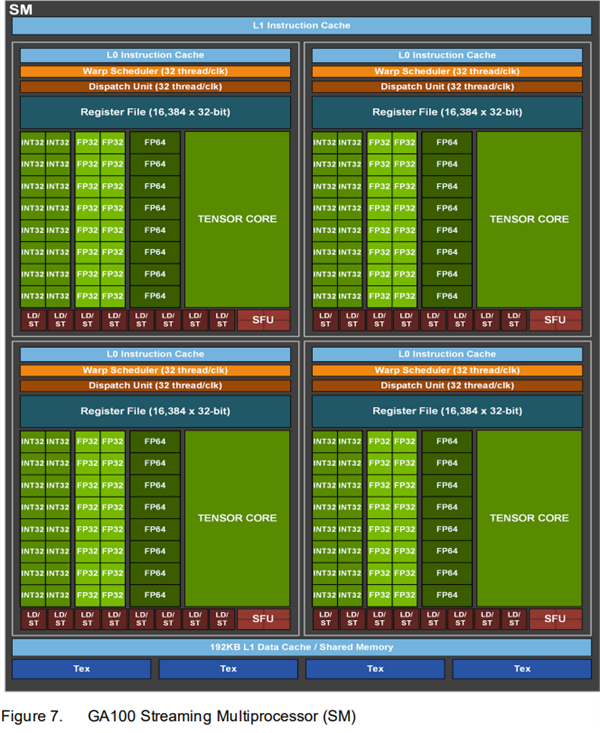
Lõi GA100 trước đây, mỗi nhóm SM bao gồm 64 đơn vị INT32, 64 đơn vị FP32 và 32 đơn vị FP64, nhưng trong lõi GA102, đơn vị FP64 bị giảm đi đáng kể, RT Core được thêm vào và Tensor Core cũng giảm nhẹ.
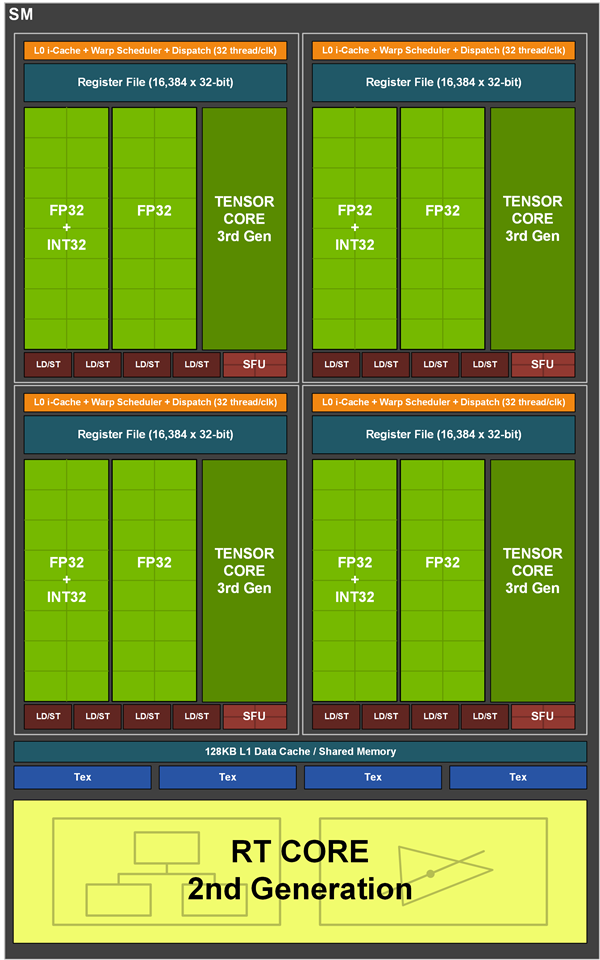
Đơn vị SM của lõi GA102
So với GPU Turing , đơn vị SM của GPU Ampere không tăng nhiều nhưng trên thực tế hiệu suất của FP32 đã tăng hơn gấp đôi, tính tần số thì hiệu suất lý thuyết của RTX 3080 gần gấp 3 lần RTX 2080. Nvidia đã làm điều đó như thế nào?
Câu trả lời là FP32 của lõi CUDA được nhân đôi, nhưng phương pháp nhân đôi hơi đặc biệt. Mỗi đơn vị SM có 4 phân vùng. Ngoài lõi Tensor Core thế hệ thứ ba, mỗi phân vùng có một bộ 16 đơn vị FP32 và 16 đơn vị bao gồm FP32 và 16 IN32, sau này có thể thực hiện các hoạt động FP32 hoặc INT32 cùng một lúc.
16 khối FP32 có thể thực hiện 16 phép tính FP32 mỗi chu kỳ và khối hỗn hợp có thể thực hiện 32 FP32 hoặc 16 FP32 + 16 INT32. Theo cách tính này, mỗi đơn vị SM có thể thực hiện đồng thời 4x (16FP32 + 16FP32) = 128 phép tính FP32 hoặc 4x (16FP32 + 16INT32) = 64 phép tính FP32 + 64 INT32.
Nếu chỉ đếm số phép tính FP32, thì con số đã tăng gấp đôi, vì Turing và GA100 chỉ có 64phép tính FP32 trên mỗi chu kỳ và hiện có thể thực hiện 128 phép toán FP32.

Cải thiện hiệu suất của FP32 mang lại lợi ích to lớn khi chơi trò chơi cũng như hiệu suất của máy tính, nhưng nó cũng cần được nâng cấp. Dung lượng L1 của GA102 đã tăng 33%, băng thông L1 tăng gấp đôi từ 116GB / s lên 219GB / s , hiệu suất của bộ nhớ dùng chung cũng thay đổi theo từng chu kỳ. 64B tăng gấp đôi thành 128B.

Kiến trúc GPU Ampere : Nâng cấp theo dõi quang học RTX từ khả dụng thành dễ sử dụng
Điểm nhấn lớn nhất của thế hệ kiến trúc GPU Turing là sự ra đời của công nghệ theo dõi ánh sáng thời gian thực RTX, mở ra kỷ nguyên theo dõi ánh sáng trong game 3D, công nghệ này có ý nghĩa rất lớn.
Tuy nhiên, giá thành của công nghệ đầu tiên này không hề nhỏ, hiệu ứng theo dõi ánh sáng của GPU Turing không rõ ràng trong một số game , điều này làm ảnh hưởng lớn đến hiệu suất. Chỉ có thể nói thế hệ card đồ họa hỗ trợ công nghệ theo dõi ánh sáng RTX đầu tiên cũng góp phần giải quyết các vấn đề của GPU Ampere hiện nay. Theo dõi quang học RTX tốt hơn trong quá trình trải nghiệm và sử dụng.

GPU Turing, RT Core thế hệ đầu tiên được NVIDIA sử dụng có thể cung cấp hiệu suất 10Giga Rays / s, trong khi trên GPU Ampere, RT Core được nâng cấp lên thế hệ thứ hai, tăng gấp đôi hiệu suất. Riêng điều này có thể cải thiện đáng kể hiệu suất theo dõi ánh sáng.
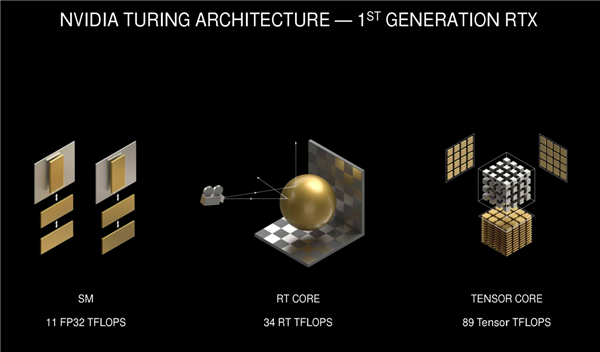
Kiến trúc theo dõi ánh sáng trên GPU Turing

GPU khuếch đại ánh sáng
Tất cả những công nghệ trên là chưa đủ. Trên GPU Ampere, không chỉ đơn vị SM và đơn vị RT tham gia vào quá trình tăng tốc khả năng theo dõi ánh sáng. Đơn vị Tensor Core thế hệ thứ ba cũng tham gia nhiều hơn vào hiệu suất của các đơn vị SM, RT và Tensor trong kiến trúc Ampere. Tất cả đều đã được cải thiện đáng kể. RTX 3080 làm ví dụ, hiệu suất đơn vị SM đã tăng từ 11T lên 30T, hiệu suất RT tăng từ thế hệ trước 34T lên 58T và Tensor tăng vọt từ 89 lên 238T.
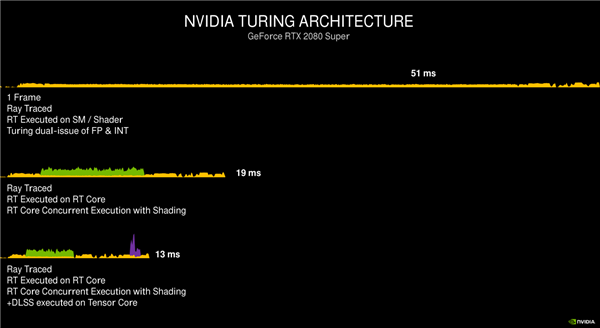
GPU Pascal không hỗ trợ tăng tốc phần cứng , card đồ họa sử dụng công nghệ này mất 51ms để hiển thị một khung hình và Turing có thể tăng nó lên 19ms và DLSS có thể được rút ngắn xuống còn 13ms, thấp hơn nhiều so với yêu cầu 60fps mất thời gian 16,6ms.

GPU Ampere, thời gian có thể nhanh hơn, và khả năng tăng tốc phần cứng thuần túy có thể được rút ngắn từ 13ms xuống còn 7,5ms, cộng với công nghệ thế hệ thứ hai với thời gian hiển thị chỉ mất 6,7ms.

Xét về hiệu năng theo dõi ánh sáng RT, thực ra không thể không kể đến card đồ họa Pascal , so với thay đổi từ RTX 2080 lên RTX 3080 thì hiệu suất kết xuất phần mềm đã tăng 40%, tăng tốc phần cứng lên 70% thì khả năng tăng tốc phần cứng + DLSS cũng được cải thiện 70%, cùng với sự hỗ trợ của các công nghệ khác, có thể cải thiện tới 90% hiệu suất theo dõi ánh sáng.
Tensor Core thế hệ thứ ba, trò chơi 8K
Tensor Core là lõi mới được giới thiệu bởi GPU Volt, là một trong ba lõi phụ của đơn vị SM. Tuy nhiên, chức năng tăng tốc AI rất quan trọng trên GPU của trung tâm dữ liệu, vì vậy Tensor Core của lõi A100 chiếm một diện tích đáng kể , Chức năng và hiệu suất được cải thiện rất nhiều.
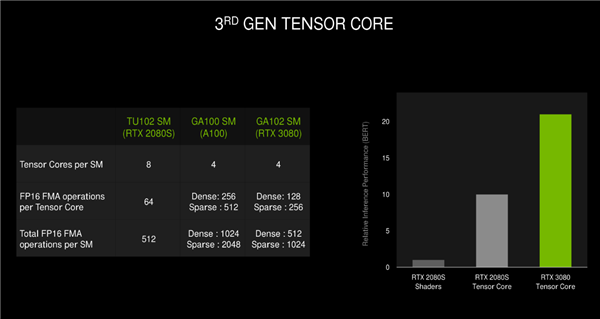
Trong lõi GA102, Tensor Core là kiến trúc thế hệ thứ ba, nhưng nó vẫn khác với lõi GA100. Mỗi nhóm đơn vị SM cũng có 4 lõi Tensor, hiệu suất giảm đi một nửa. Nhưng trên GPU game thì ý nghĩa của Tensor Core lại không quá lớn, DLSS được coi là tốt hơn cho khả năng tăng tốc AI, có thể cải thiện hơn nữa hiệu suất trò chơi. Mặc dù lần này vẫn là DLSS 2.0 tương xứng với hiệu năng mạnh mẽ của card đồ họa RTX 3090. , Trò chơi 8K DLSS trở nên khả thi.
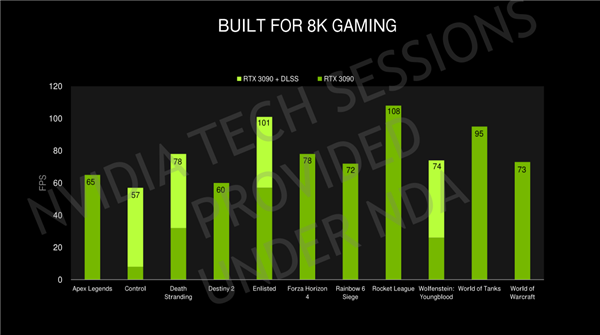
Độ phân giải của các trò chơi 8K gấp 4 lần 4K và 16 lần so với 1080p. Chỉ riêng độ phân giải cao đã đủ để khiến phần cứng cao cấp hiện nay quá tải, nhưng với công nghệ DLSS, RTX 3090 đang chiếm ưu thế hơn nhiều. Các trò chơi có thể đạt khung hình 60fps, lên đến 100fps , việc chơi gam 8k không còn là vấn đề.

Chất lượng hình ảnh của công nghệ DLSS

So sánh 8K trong Game Watchdog

Hình ảnh chi tiết hơn sẽ là lợi thế cho các game thủ
Đây có lẽ là tầm quan trọng của Tensor Core đối với Game, nhưng chúng tôi phải nói rằng 8K vẫn còn rất xa phần cứng mới theo kịp, tuy nhiên bạn có thể chơi tốt 4K.
Nâng cấp băng thông bộ nhớ GDDR6X tương đương với HBM2
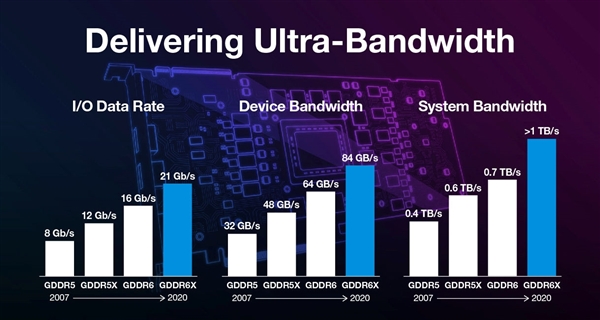
Ngoài bản thân GPU, công nghệ bộ nhớ video thế hệ Kiến trúc GPU Ampere cũng được nâng cấp, trước đây thế hệ GPU Turing lần đầu tiên ra mắt bộ nhớ video GDDR6. Lần này NVIDIA đã nhanh chóng thương mại hóa bộ nhớ video GDDR6X, trong đó RTX 3090 không chỉ có tần số 19,5Gbps mà còn có dung lượng lớn tới 24GB.
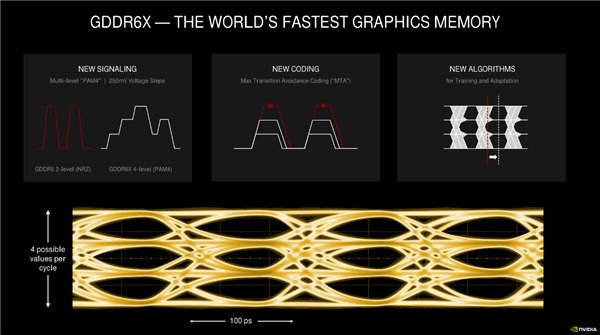
GDDR6X dựa trên bản nâng cấp GDDR6 hiện tại, cấu trúc và công nghệ cơ bản không thay đổi, có thêm cơ chế báo hiệu PAM4. Bốn mức điện áp được sử dụng giữa bộ xử lý và bộ nhớ, hai bit được mã hóa và truyền trong mỗi chu kỳ.
Về cơ chế PAM4, mọi người đều có thể hiểu việc nâng cấp bộ nhớ flash từ SLC lên MLC. Lượng dữ liệu truyền mỗi chu kỳ có thể tăng gấp đôi. Do đó, có thể nhận ra tần số tương đương tốc độ siêu cao có thể đạt được 21Gbps ngay từ đầu. NVIDIA hiện sử dụng hơi thận trọng , RTX 3090 là 19,2Gbps, RTX 3080 là 18Gbps.
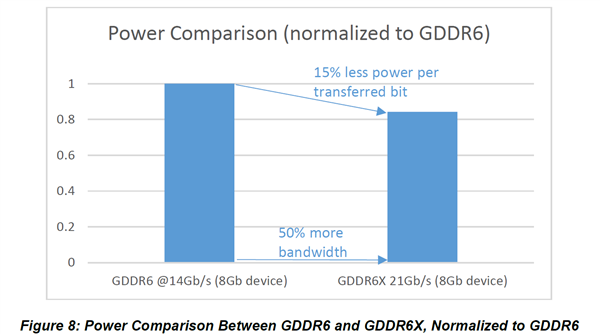
Bộ nhớ video GDDR6X, băng thông được tăng lên 50%, hiệu suất năng lượng cũng được cải thiện và mức tiêu thụ điện trên mỗi bit giảm 15%.
Kiến trúc giao tiếp PCI 4.0
Trên GPU Ampere, có một số nâng cấp kỹ thuật
· Hỗ trợ nâng cấp giải mã video AV1 8K

8K là một phần quan trọng trong quá trình nâng cấp của NVIDIA, ngoài hiệu năng game có thể hỗ trợ 8K thì giao diện và giải mã cũng đã được Nvidia chuẩn bị.
GPU Ampere lần đầu tiên cập nhật bộ mã hóa NVDEC có khả năng hỗ trợ giải mã 8K 60p của AV1. Kiểu mã hóa này có thể tiết kiệm rất nhiều băng thông so với H264, CPU được giải mã nhẹ nhàng với tỷ lệ sử dụng CPU 9900K đạt 85%, trong khi NVDEC của GPU Ampere là cứng. Tỷ lệ lấp đầy của giải pháp chỉ là 4%, trong khi tốc độ khung hình có thể đạt 60 khung hình / giây , độ mượt của được cải thiện từ 28 khung hình / giây .
. HDMI 2.1 đầu tiên, đầu ra 8K

Ngoài giao diện DP1.4a, lần này HDMI 2.1 là giao diện đầu tiên hỗ trợ đầu ra 4 màn hình. Chuẩn này có 48Gbps mới hỗ trợ HDR 8K 60Hz, phù hợp với thế hệ màn hình mới.
- Hỗ trợ PCIe 4.0 mà không lo lắng về việc giảm hiệu suất
Card đồ họa RTX 30 series hỗ trợ PCIe 4.0, đây là xu hướng chung, nhưng vấn đề của PCIe 4.0 là chỉ trên nền tảng AMD’s X570 mới có thể hỗ trợ đầy đủ. Nền tảng máy tính để bàn của Intel vẫn chưa hỗ trợ chuẩ PCIe 4.0.
Các bạn có thể cân nhắc sử dụng nền tảng Ryzen của AMD, nhưng họ không bắt buộc phải sử dụng nền tảng đó cho PCIe 4.0. NVIDIA cho biết tác động hiệu suất của PCIe 4.0 xuống PCIe 3.0 là rất hạn chế, chỉ một vài điểm phần trăm, không lớn bằng tác động của CPU. Ngụ ý là nếu bạn sử dụng nền tảng Intel nên sử dụng Core i9 -9900K hoặc Core i9-10900K .
- Công cụ game Reflex, Broadcast, Omniverse Machinima :
Người dùng yêu thích card đồ họa Nvidia không chỉ vì hiệu năng , công nghệ phần cứng ... mà do Nvidia hỗ trợ nhiều trò chơi , với nhiều phần mềm và trải nghiệm GFE tích hợp nhiều công cụ được game thủ ưa chuộng .
Trên card đồ họa Ampere, NVIDIA đã mang đến ba tính năng mới, bao gồm NVIDIA Reflex để giảm độ trễ, NVIDIA Broadcast trực tiếp tăng tốc AI và NVIDIA Omniverse Machinima.
· NVIDIA Reflex: Độ trễ giảm 50%
Người chơi game, đặc biệt là game online đặc biệt quan tâm tới độ trễ, độ trễ này không chỉ liên quan đến hiệu suất mạng và card đồ họa mà còn liên quan đến hệ thống, bao gồm cả độ trễ đầu vào của bàn phím và chuột.
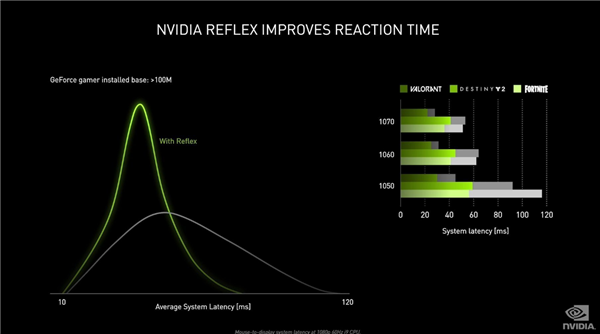
NVIDIA Reflex là một công cụ có thể giảm độ trễ. Trong các trò chơi hỗ trợ công nghệ này, "Apex Heroes", "Call of Duty: Warzone", "Fortnite", "VALORANT" và các trò chơi thể thao điện tử phổ biến khác, độ trễ có thể được giảm bớt tới 50%.
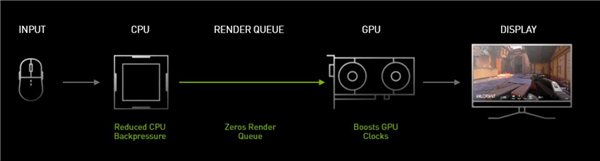
NVIDIA Reflex cũng sẽ có trình phân tích độ trễ phản xạ trong tương lai, có thể theo dõi các lần nhấp chuột và đo thời gian cần thiết cho các thay đổi pixel tương ứng trên màn hình, chẳng hạn như đèn flash của súng, . Công nghệ hiệu ứng này tương đương với một chiếc máy ảnh chuyên dụng và thiết bị tốc độ cao trị giá tới 7.000 USD.
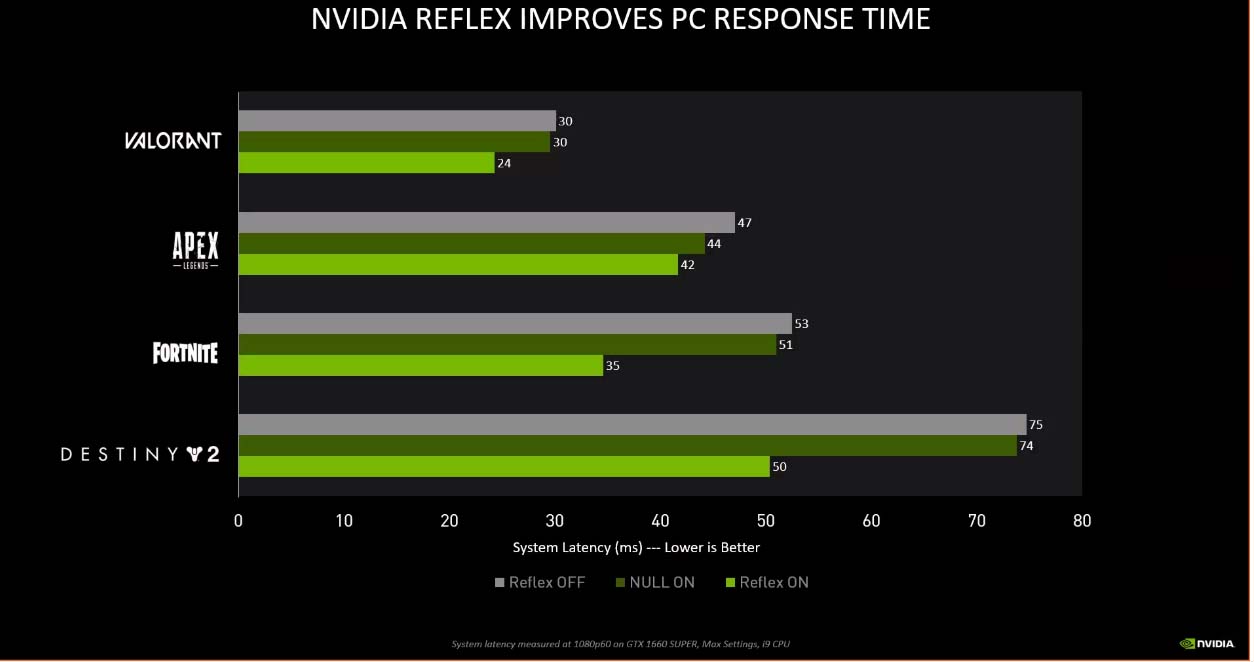
Giảm độ trễ trong một số trò chơi ( chỉ số thấp là tốt hơn)
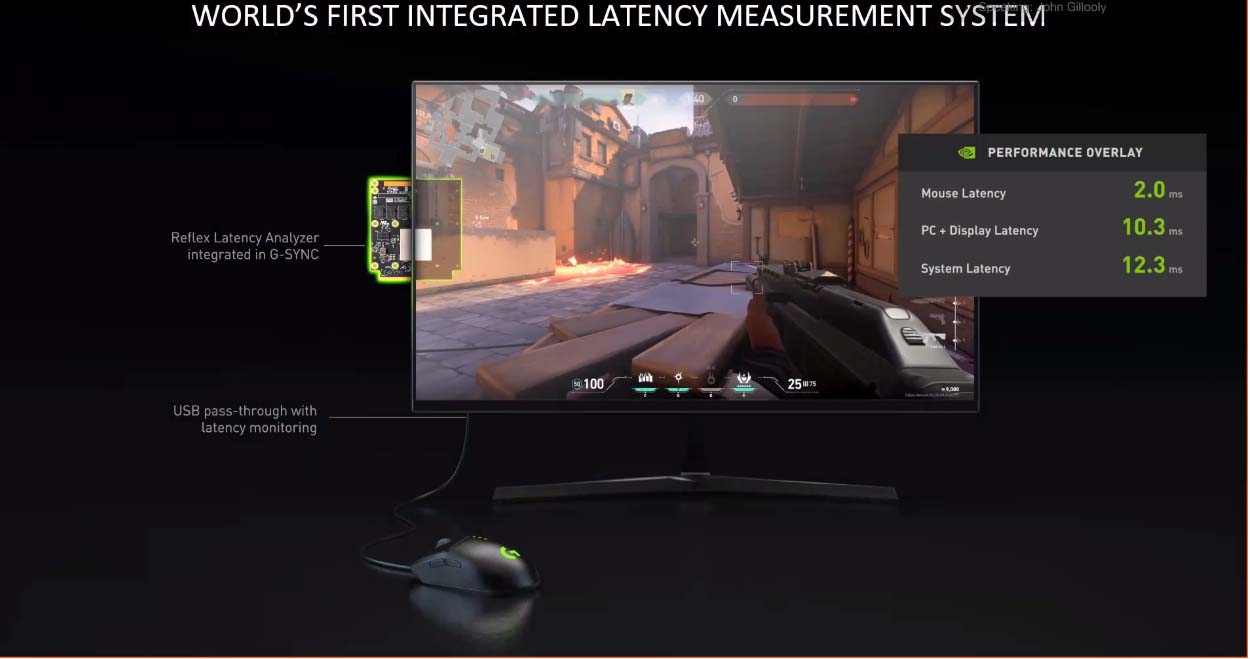
Công nghệ giảm độ trễ được phân tích trên các thiết bị phần cứng gồm chuột, màn hình PC, ...
Hỗ trợ màn hình và chuột tương ứng từ các thương hiệu cho Game thủ chuyên nghiệp
· NVIDIA Broadcast: công cụ tuyệt vời cho game thủ livestream
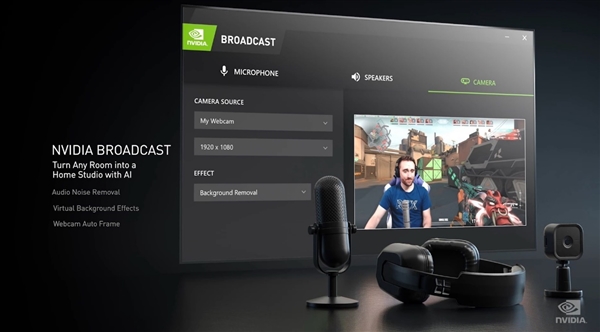
Ngày nay, chơi game các game thủ thường yêu thích phát sóng trực tiếp. Phần mềm NVIDIA Broadcast có thể giúp người quản lý trò chơi tiết kiệm công sức hơn. Phần mềm này thực hiện nhiều chức năng thông qua khả năng tăng tốc AI của cạc đồ họa, chẳng hạn như khử nhiễu, nền ảo và hiển thị khung hình tự động, do đó nâng cao chất lượng âm thanh và hình ảnh của micrô và webcam.
· NVIDIA Omniverse Machinima: Tự mình tạo nên những bộ phim bom tấn
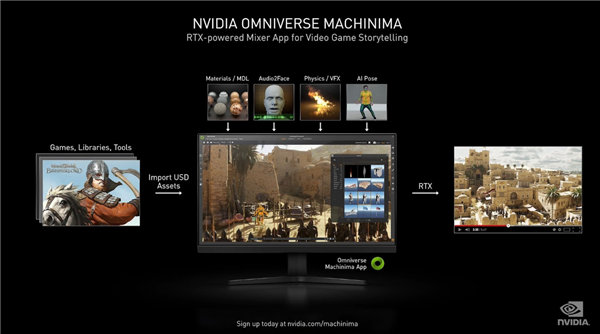
Omniverse Machinima là một công cụ làm phim cơ động , cho phép người chơi sử dụng các tài nguyên trong trò chơi để làm thành những bộ phim của riêng họ, mô phỏng chính xác ánh sáng, vật thể, vật liệu và trí tuệ nhân tạo và có thể được áp dụng cho hầu hết các công cụ thiết kế chuyên nghiệp của bên thứ ba, chẳng hạn như 3DS, Max, Maya , Photoshop, Epic Unreal và Rhino, v.v., sử dụng card đồ họa RTX series hiển thị các hiệu ứng cấp độ phim trường. Đây cũng là một vũ khí để các nhà phát triển trò chơi làm cho trò chơi CG, giúp đơn giản hóa đáng kể quá trình thực hiện các đoạn cắt cảnh của trò chơi.
- RTX IO: Công nghệ -RTX IO, cho phép ổ cứng SSD tải trò chơi trong thời gian thực.

Ổ cứng SSD gần như phổ biến hiện nay, hiệu năng siêu nhanh của SSD mang lại lợi ích cho game thủ rất nhiều, tốc độ tải game đã được cải thiện nhưng điều này vẫn chưa ổn vì dung lượng game ngày càng lớn, việc đọc dữ liệu ngày càng trở nên thường xuyên hơn.
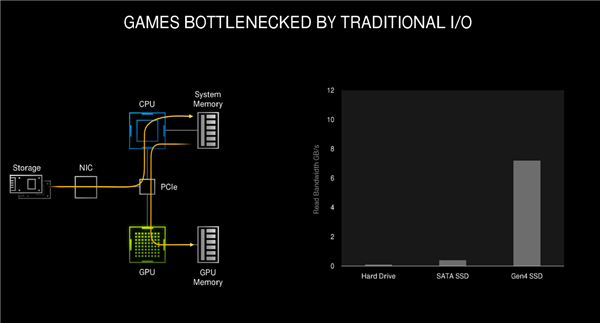
Nguyên nhân sâu xa của vấn đề này nằm ở thiết kế IO truyền thống, dữ liệu trò chơi được nén cần thông qua ổ đĩa cứng, bo mạch chủ, PCIe, CPU, GPU và hệ thống bộ nhớ tương ứng. Quá trình này cồng kềnh và có thể xảy ra tắc nghẽn.
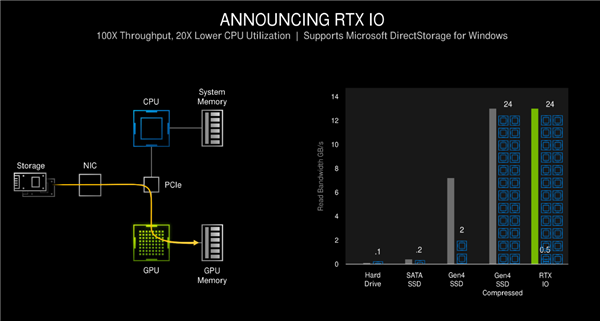
Với RTX IO, dữ liệu trò chơi không cần đi qua CPU và bộ nhớ, nó được đọc trực tiếp bởi GPU và hỗ trợ giải nén không mất dữ liệu, giúp mức sử dụng CPU thấp hơn 20 lần và thông lượng tăng gấp 100 lần.
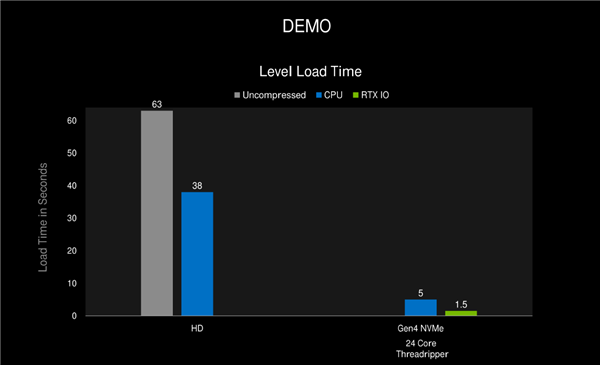
Tốc độ tải game được cải thiện rất nhiều, như hình trên, chưa kể thời gian tải của ổ cứng HD là 38 giây, tốc độ tăng tốc của ổ cứng PCIe 4.0 mất 5 giây, nhưng công nghệ RTX IO chỉ mất1,5 giây. Mất hơn 1 giây để tải gần như trong thời gian thực , quá trình chuyển đổi hoàn tất trong chớp mắt. Với công nghệ này việc chuyển đổi bản đồ hoặc cảnh trong trò chơi cực kỳ nhanh chóng.
Công nghệ RTX IO của NVIDIA thực sự là công nghệ trong thế hệ máy tính lớn mới, hỗ trợ nhiều định dạng nén hơn và giải nén hiệu quả hơn. Công nghệ này cũng hỗ trợ DirectStorage của Microsoft, rên nền tảng Windows 10 vào năm 2021, lúc này máy chủ và máy tính cá nhân đều có thể tận hưởng công nghệ này.
Vn-Z.vn team tổng hợp
Sau khi ra mắt dòng card đồ họa RTX 30 series, sự không hài lòng của người chơi dường như đã được giải tỏa, so với dòng card đồ họa Turing hiện tại, card đồ họa RTX 3090/3080/3070 kiến trúc Ampere bỗng trở nên rất được ưa chuộng, hiệu năng của chúng đã tăng gấp đôi, giá tốt hơn.
Trong đó với RTX 3090. Huang Renxun tuyên bố rằng card đồ họa này hỗ trợ các game 8K, giá là 1499 USD (tương đương 34.5 triệu VNĐ) và sẽ được bán ra vào ngày 24/9.
RTX 3080, có hiệu năng gấp đôi RTX 2080 và có giá 699 USD ( 16 triệu VNĐ), sẽ lên kệ vào ngày 17/9. Card đồ họa RTX 3070 có hiệu năng cao hơn RTX 2080 Ti, với giá 499 USD (11 triệu VNĐ) và sẽ bán ra thị trường vào tháng 10.
Hiệu suất đồ họa dòng RTX 30
Thông số kỹ thuật RTX 30 series
Card đồ họa RTX 2080 Ti, hiệu suất FP32 mang tính biểu tượng của RTX 3090 đã tăng từ 13,4T lên 35,7T, cao hơn gấp đôi, đồng thời khả năng Tracing quang học và tăng tốc AI cũng được cải thiện đáng kể.
So với card đồ họa Turing, công nghệ GPU Ampere có nhiều thay đổi thật đáng ngạc nhiên. Trong 10 năm qua, việc nâng cấp card đồ họa lên gấp đôi, hiếm khi người dùng được chứng kiến. NVIDA đã làm như thế nào?
Hôm nay chúng ta sẽ giải thích chi tiết kiến trúc của GPU Ampere và khám phá những kỹ thuật được nâng cấp, khiến founder NVIDIA Huang Renxun gọi đây là cải tiến hiệu suất lớn nhất trong lịch sử.
Đầu tiên cùng tìm hiểu quy trình: làm thế nào để 8nm có thể tiến xa hơn ,sau khi 12nm giết chết 7nm. ?
NVIDIA sử dụng kiến trúc thế hệ hai Volta và Turing đều là quy trình FFN 12nm của TSMC. Đây là phiên bản cải tiến của quy trình 16nm của TSMC. Nếu tính cả kiến trúc 16nm Pascal , là thế hệ kiến trúc card đồ họa thứ 3.
Về kiến trúc Ampere, là kiến trức với quy trình được nâng cấp, nhưng lần này có hai điểm đáng chú ý - thứ nhất, hãng không chọn TSMC . thứ hai là không sử dụng quy trình 7nm mà là quy trình 8nm tùy chỉnh của Samsung, mặc dù có vẻ như chỉ kém 1nm về con số so với 7nm, Nhưng nó thực sự là một quá trình nâng cấp thế hệ hai.
Quy trình 8nm của Samsung được cải tiến dựa trên quy trình 10nm, có ít nhất hai phiên bản là LPP và LPU, phiên bản trước phù hợp với SoC di động, phiên bản sau phù hợp với chip hiệu năng cao, tùy biến của NVIDIA có lẽ dựa trên phiên bản thứ hai.
So với quy trình 7nm của TSMC’s, mật độ bóng bán dẫn khoảng 100 triệu / mm2, còn quy trình 8nm là khoảng 60 triệu bóng bán dẫn / mm2, nhưng đây là so sánh của về chip SRAM đơn lẻ. Trên thực tế, chip GPU phức tạp hơn và khoảng cách nhỏ hơn nhiều.
Theo thông tin do NVIDIA công bố, lõi của Ampere A100 được sản xuất theo quy trình 7nm của TSMC có 54 tỷ bóng bán dẫn , lõi có diện tích là 826mm2, trong khi lõi của GA102 do Samsung sản xuất trên quy trình 8nm gồm 28 tỷ bóng bán dẫn. Diện tích lõi không được công bố chính thức. Có báo cáo cho là khoảng 628mm2, nếu đúng thì lõi này cũng khá lớn.
Tính theo cách này, mật độ bóng bán dẫn của lõi 7nm A100 là 65,6 triệu bóng bán dẫn / mm2, trong khi lõi 8nm GA102 của Samsung cũng có 44,6 triệu bóng bán dẫn / mm2 - khoảng cách vẫn còn nhưng chấp nhận được.
Giá xuất xưởng đúc lõi trên tiến trình 8nm của Samsung vẫn còn là một bí mật, tuy nhiên về mặt công nghệ và chiến lược kinh doanh thì công nghệ của Samsung sẽ rẻ hơn TSMC rất nhiều, dự kiến giá xưởng đúc sẽ từ 30% trở lên. Nên dòng card đồ họa RTX 30 không thể tăng giá. Thậm chí còn giảm giá.
Hiệu suất và mức năng lượng mà quy trình 8nm của Samsung mang lại là bao nhiêu? Bạn có thể thấy rằng tần số của các card đồ họa RTX 30 series đã tăng lên, từ 1.5GHz + của RTX 20 series lên 1.7GHz + hiệu suất của quá trình nâng cấp ngày càng được cải thiện.
Tuy nhiên, tần số tăng tốc của dòng RTX 20 thực tế có thể đạt tới 1,9 GHz hoặc thậm chí gần bằng 2 GHz, và dòng RTX 30 dự kiến sẽ ở mức này. Mức tiêu năng lượng đã được cải thiện, NVIDIA chính thức tuyên bố rằng ở tốc độ 60 khung hình / giây, mức tiêu thụ điện năng của card đồ họa Turing là khoảng 240W, mức tiêu thụ điện của card đồ họa Ampere là hơn 120W, gấp 1,9 lần hiệu suất năng lượng, tức là tăng 90%, nhưng nhiệt độ vẫn thấp hơn. 3 độ, tiếng ồn giảm 2 decibel.
Như vậy về quy trình thì ai cũng ngạc nhiên và thất vọng với GPU Ampere với tiến trình 7nm (không phân biệt TSMC hay Samsung) không đạt như mong đợi. Tiến trình này tiếp tục được nâng cấp lên 8nm.
Mặc dù quy trình của NVIDIA không triệt để cải tiến về hiệu suất , mức tiêu thụ năng lượng vẫn còn khá lớn nhưng card đồ họa Ampere’s tốt hơn đáng kể so với card Turing hiện tại về mọi mặt, trong khi đó giá lại giảm xuống, đây không phải là mục tiêu theo đuổi công nghệ triệt để. Dù sao thì trước đây quy trình 12nm cũng có thể tốt hơn nhưng lợi ích của việc chuyển sang 8nm sẽ an toàn hơn.
Chi tiết về kiến trúc GPU Ampere: Khối FP32 tăng gấp đôi. Thay đổi lõi CUDA là gì?
Khi kiến trúc GPU Ampere được phát hành, Giám đốc điều hành NVIDIA Huang Renxun tuyên bố rằng đây là bước nhảy vọt về hiệu suất lớn nhất trong lịch sử GPU. Khi GPU Turing ra mắt vào năm 2018, Huang đã đưa ra một tuyên bố tương tự - sự thay đổi lớn nhất trong lịch sử GPU. Hai tuyên bố này thực sự cũng là đúng.
Kiến trúc GPU Turing có nhiều công nghệ đầu tiên . Nó hỗ trợ RTX Core (Bộ tăng tốc theo dõi ánh sáng lần đầu tiên Ray Tracing) , lần đầu tiên hỗ trợ Tensor Core , cải thiện lõi CUDA. Trong đó RTX Core và Tensor Core là hai điểm trọng tâm đầu tiên của kiến trung Turing.
GPU Ampere, RT Core và Tensor Core tiếp tục được tăng cường, nhưng điểm nhấn chính là sự cải tiến của kiến trúc CUDA. Đây là nnguyên nhân sâu xa lý giải công nghệ tăng gấp đôi hiệu suất là đây.
Sơ đồ kiến trúc lõi GA102
Lõi GA102 có tổng cộng 7 nhóm đơn vị GPC, mỗi nhóm có 12 nhóm đơn vị SM, tổng cộng 84 nhóm, tổng số đơn vị SM được kích hoạt cho các card đồ họa dòng RTX 30 phụ thuộc vào các thông số kỹ thuật khác nhau, RTX 3090 là 82 nhóm, RTX 3080 là 68 nhóm, RTX 3070 là 46 nhóm.
Lõi GA100 trước đây, mỗi nhóm SM bao gồm 64 đơn vị INT32, 64 đơn vị FP32 và 32 đơn vị FP64, nhưng trong lõi GA102, đơn vị FP64 bị giảm đi đáng kể, RT Core được thêm vào và Tensor Core cũng giảm nhẹ.
Đơn vị SM của lõi GA102
So với GPU Turing , đơn vị SM của GPU Ampere không tăng nhiều nhưng trên thực tế hiệu suất của FP32 đã tăng hơn gấp đôi, tính tần số thì hiệu suất lý thuyết của RTX 3080 gần gấp 3 lần RTX 2080. Nvidia đã làm điều đó như thế nào?
Câu trả lời là FP32 của lõi CUDA được nhân đôi, nhưng phương pháp nhân đôi hơi đặc biệt. Mỗi đơn vị SM có 4 phân vùng. Ngoài lõi Tensor Core thế hệ thứ ba, mỗi phân vùng có một bộ 16 đơn vị FP32 và 16 đơn vị bao gồm FP32 và 16 IN32, sau này có thể thực hiện các hoạt động FP32 hoặc INT32 cùng một lúc.
16 khối FP32 có thể thực hiện 16 phép tính FP32 mỗi chu kỳ và khối hỗn hợp có thể thực hiện 32 FP32 hoặc 16 FP32 + 16 INT32. Theo cách tính này, mỗi đơn vị SM có thể thực hiện đồng thời 4x (16FP32 + 16FP32) = 128 phép tính FP32 hoặc 4x (16FP32 + 16INT32) = 64 phép tính FP32 + 64 INT32.
Nếu chỉ đếm số phép tính FP32, thì con số đã tăng gấp đôi, vì Turing và GA100 chỉ có 64phép tính FP32 trên mỗi chu kỳ và hiện có thể thực hiện 128 phép toán FP32.
Cải thiện hiệu suất của FP32 mang lại lợi ích to lớn khi chơi trò chơi cũng như hiệu suất của máy tính, nhưng nó cũng cần được nâng cấp. Dung lượng L1 của GA102 đã tăng 33%, băng thông L1 tăng gấp đôi từ 116GB / s lên 219GB / s , hiệu suất của bộ nhớ dùng chung cũng thay đổi theo từng chu kỳ. 64B tăng gấp đôi thành 128B.
Kiến trúc GPU Ampere : Nâng cấp theo dõi quang học RTX từ khả dụng thành dễ sử dụng
Điểm nhấn lớn nhất của thế hệ kiến trúc GPU Turing là sự ra đời của công nghệ theo dõi ánh sáng thời gian thực RTX, mở ra kỷ nguyên theo dõi ánh sáng trong game 3D, công nghệ này có ý nghĩa rất lớn.
Tuy nhiên, giá thành của công nghệ đầu tiên này không hề nhỏ, hiệu ứng theo dõi ánh sáng của GPU Turing không rõ ràng trong một số game , điều này làm ảnh hưởng lớn đến hiệu suất. Chỉ có thể nói thế hệ card đồ họa hỗ trợ công nghệ theo dõi ánh sáng RTX đầu tiên cũng góp phần giải quyết các vấn đề của GPU Ampere hiện nay. Theo dõi quang học RTX tốt hơn trong quá trình trải nghiệm và sử dụng.
GPU Turing, RT Core thế hệ đầu tiên được NVIDIA sử dụng có thể cung cấp hiệu suất 10Giga Rays / s, trong khi trên GPU Ampere, RT Core được nâng cấp lên thế hệ thứ hai, tăng gấp đôi hiệu suất. Riêng điều này có thể cải thiện đáng kể hiệu suất theo dõi ánh sáng.
Kiến trúc theo dõi ánh sáng trên GPU Turing
GPU khuếch đại ánh sáng
GPU Pascal không hỗ trợ tăng tốc phần cứng , card đồ họa sử dụng công nghệ này mất 51ms để hiển thị một khung hình và Turing có thể tăng nó lên 19ms và DLSS có thể được rút ngắn xuống còn 13ms, thấp hơn nhiều so với yêu cầu 60fps mất thời gian 16,6ms.
GPU Ampere, thời gian có thể nhanh hơn, và khả năng tăng tốc phần cứng thuần túy có thể được rút ngắn từ 13ms xuống còn 7,5ms, cộng với công nghệ thế hệ thứ hai với thời gian hiển thị chỉ mất 6,7ms.
Xét về hiệu năng theo dõi ánh sáng RT, thực ra không thể không kể đến card đồ họa Pascal , so với thay đổi từ RTX 2080 lên RTX 3080 thì hiệu suất kết xuất phần mềm đã tăng 40%, tăng tốc phần cứng lên 70% thì khả năng tăng tốc phần cứng + DLSS cũng được cải thiện 70%, cùng với sự hỗ trợ của các công nghệ khác, có thể cải thiện tới 90% hiệu suất theo dõi ánh sáng.
Tensor Core thế hệ thứ ba, trò chơi 8K
Tensor Core là lõi mới được giới thiệu bởi GPU Volt, là một trong ba lõi phụ của đơn vị SM. Tuy nhiên, chức năng tăng tốc AI rất quan trọng trên GPU của trung tâm dữ liệu, vì vậy Tensor Core của lõi A100 chiếm một diện tích đáng kể , Chức năng và hiệu suất được cải thiện rất nhiều.
Trong lõi GA102, Tensor Core là kiến trúc thế hệ thứ ba, nhưng nó vẫn khác với lõi GA100. Mỗi nhóm đơn vị SM cũng có 4 lõi Tensor, hiệu suất giảm đi một nửa. Nhưng trên GPU game thì ý nghĩa của Tensor Core lại không quá lớn, DLSS được coi là tốt hơn cho khả năng tăng tốc AI, có thể cải thiện hơn nữa hiệu suất trò chơi. Mặc dù lần này vẫn là DLSS 2.0 tương xứng với hiệu năng mạnh mẽ của card đồ họa RTX 3090. , Trò chơi 8K DLSS trở nên khả thi.
Chất lượng hình ảnh của công nghệ DLSS
So sánh 8K trong Game Watchdog
Hình ảnh chi tiết hơn sẽ là lợi thế cho các game thủ
Đây có lẽ là tầm quan trọng của Tensor Core đối với Game, nhưng chúng tôi phải nói rằng 8K vẫn còn rất xa phần cứng mới theo kịp, tuy nhiên bạn có thể chơi tốt 4K.
Nâng cấp băng thông bộ nhớ GDDR6X tương đương với HBM2
Ngoài bản thân GPU, công nghệ bộ nhớ video thế hệ Kiến trúc GPU Ampere cũng được nâng cấp, trước đây thế hệ GPU Turing lần đầu tiên ra mắt bộ nhớ video GDDR6. Lần này NVIDIA đã nhanh chóng thương mại hóa bộ nhớ video GDDR6X, trong đó RTX 3090 không chỉ có tần số 19,5Gbps mà còn có dung lượng lớn tới 24GB.
Về cơ chế PAM4, mọi người đều có thể hiểu việc nâng cấp bộ nhớ flash từ SLC lên MLC. Lượng dữ liệu truyền mỗi chu kỳ có thể tăng gấp đôi. Do đó, có thể nhận ra tần số tương đương tốc độ siêu cao có thể đạt được 21Gbps ngay từ đầu. NVIDIA hiện sử dụng hơi thận trọng , RTX 3090 là 19,2Gbps, RTX 3080 là 18Gbps.
Bộ nhớ video GDDR6X, băng thông được tăng lên 50%, hiệu suất năng lượng cũng được cải thiện và mức tiêu thụ điện trên mỗi bit giảm 15%.
Kiến trúc giao tiếp PCI 4.0
Trên GPU Ampere, có một số nâng cấp kỹ thuật
· Hỗ trợ nâng cấp giải mã video AV1 8K
GPU Ampere lần đầu tiên cập nhật bộ mã hóa NVDEC có khả năng hỗ trợ giải mã 8K 60p của AV1. Kiểu mã hóa này có thể tiết kiệm rất nhiều băng thông so với H264, CPU được giải mã nhẹ nhàng với tỷ lệ sử dụng CPU 9900K đạt 85%, trong khi NVDEC của GPU Ampere là cứng. Tỷ lệ lấp đầy của giải pháp chỉ là 4%, trong khi tốc độ khung hình có thể đạt 60 khung hình / giây , độ mượt của được cải thiện từ 28 khung hình / giây .
. HDMI 2.1 đầu tiên, đầu ra 8K
Ngoài giao diện DP1.4a, lần này HDMI 2.1 là giao diện đầu tiên hỗ trợ đầu ra 4 màn hình. Chuẩn này có 48Gbps mới hỗ trợ HDR 8K 60Hz, phù hợp với thế hệ màn hình mới.
- Hỗ trợ PCIe 4.0 mà không lo lắng về việc giảm hiệu suất
Card đồ họa RTX 30 series hỗ trợ PCIe 4.0, đây là xu hướng chung, nhưng vấn đề của PCIe 4.0 là chỉ trên nền tảng AMD’s X570 mới có thể hỗ trợ đầy đủ. Nền tảng máy tính để bàn của Intel vẫn chưa hỗ trợ chuẩ PCIe 4.0.
Các bạn có thể cân nhắc sử dụng nền tảng Ryzen của AMD, nhưng họ không bắt buộc phải sử dụng nền tảng đó cho PCIe 4.0. NVIDIA cho biết tác động hiệu suất của PCIe 4.0 xuống PCIe 3.0 là rất hạn chế, chỉ một vài điểm phần trăm, không lớn bằng tác động của CPU. Ngụ ý là nếu bạn sử dụng nền tảng Intel nên sử dụng Core i9 -9900K hoặc Core i9-10900K .
- Công cụ game Reflex, Broadcast, Omniverse Machinima :
Người dùng yêu thích card đồ họa Nvidia không chỉ vì hiệu năng , công nghệ phần cứng ... mà do Nvidia hỗ trợ nhiều trò chơi , với nhiều phần mềm và trải nghiệm GFE tích hợp nhiều công cụ được game thủ ưa chuộng .
Trên card đồ họa Ampere, NVIDIA đã mang đến ba tính năng mới, bao gồm NVIDIA Reflex để giảm độ trễ, NVIDIA Broadcast trực tiếp tăng tốc AI và NVIDIA Omniverse Machinima.
· NVIDIA Reflex: Độ trễ giảm 50%
Người chơi game, đặc biệt là game online đặc biệt quan tâm tới độ trễ, độ trễ này không chỉ liên quan đến hiệu suất mạng và card đồ họa mà còn liên quan đến hệ thống, bao gồm cả độ trễ đầu vào của bàn phím và chuột.
NVIDIA Reflex là một công cụ có thể giảm độ trễ. Trong các trò chơi hỗ trợ công nghệ này, "Apex Heroes", "Call of Duty: Warzone", "Fortnite", "VALORANT" và các trò chơi thể thao điện tử phổ biến khác, độ trễ có thể được giảm bớt tới 50%.
Giảm độ trễ trong một số trò chơi ( chỉ số thấp là tốt hơn)
Công nghệ giảm độ trễ được phân tích trên các thiết bị phần cứng gồm chuột, màn hình PC, ...
Hỗ trợ màn hình và chuột tương ứng từ các thương hiệu cho Game thủ chuyên nghiệp
· NVIDIA Broadcast: công cụ tuyệt vời cho game thủ livestream
· NVIDIA Omniverse Machinima: Tự mình tạo nên những bộ phim bom tấn
- RTX IO: Công nghệ -RTX IO, cho phép ổ cứng SSD tải trò chơi trong thời gian thực.
Ổ cứng SSD gần như phổ biến hiện nay, hiệu năng siêu nhanh của SSD mang lại lợi ích cho game thủ rất nhiều, tốc độ tải game đã được cải thiện nhưng điều này vẫn chưa ổn vì dung lượng game ngày càng lớn, việc đọc dữ liệu ngày càng trở nên thường xuyên hơn.
Nguyên nhân sâu xa của vấn đề này nằm ở thiết kế IO truyền thống, dữ liệu trò chơi được nén cần thông qua ổ đĩa cứng, bo mạch chủ, PCIe, CPU, GPU và hệ thống bộ nhớ tương ứng. Quá trình này cồng kềnh và có thể xảy ra tắc nghẽn.
Với RTX IO, dữ liệu trò chơi không cần đi qua CPU và bộ nhớ, nó được đọc trực tiếp bởi GPU và hỗ trợ giải nén không mất dữ liệu, giúp mức sử dụng CPU thấp hơn 20 lần và thông lượng tăng gấp 100 lần.
Công nghệ RTX IO của NVIDIA thực sự là công nghệ trong thế hệ máy tính lớn mới, hỗ trợ nhiều định dạng nén hơn và giải nén hiệu quả hơn. Công nghệ này cũng hỗ trợ DirectStorage của Microsoft, rên nền tảng Windows 10 vào năm 2021, lúc này máy chủ và máy tính cá nhân đều có thể tận hưởng công nghệ này.
Vn-Z.vn team tổng hợp

